尝试使用Selenium自动化测试库对Github中指定topic的所有库信息进行爬取!
首先简单介绍下Selenium库 。这是一个针对浏览器应用的自动化测试库,能够模拟人类的点击、敲击键盘、输入文字等操作,因此也能够很好地作为爬虫工具使用。Selenium的使用原理就是首先创建浏览器驱动WebDriver,并获取给定url的HTML,使用Selector对HTML元素进行选取,然后进行自定义的操作。
本文中,我们将使用Selenium库对Github topics页面进行解析,并爬取指定topic下的所有库信息。这里以motion-generation这个主题为例。
首先,我们需要创建WebDriver,并获取指定页面的HTML。
1 2 3 4 topic = "motion-generation" driver = webdriver.Chrome() topic_url = 'https://github.com/topics/' +topic driver.get(topic_url)
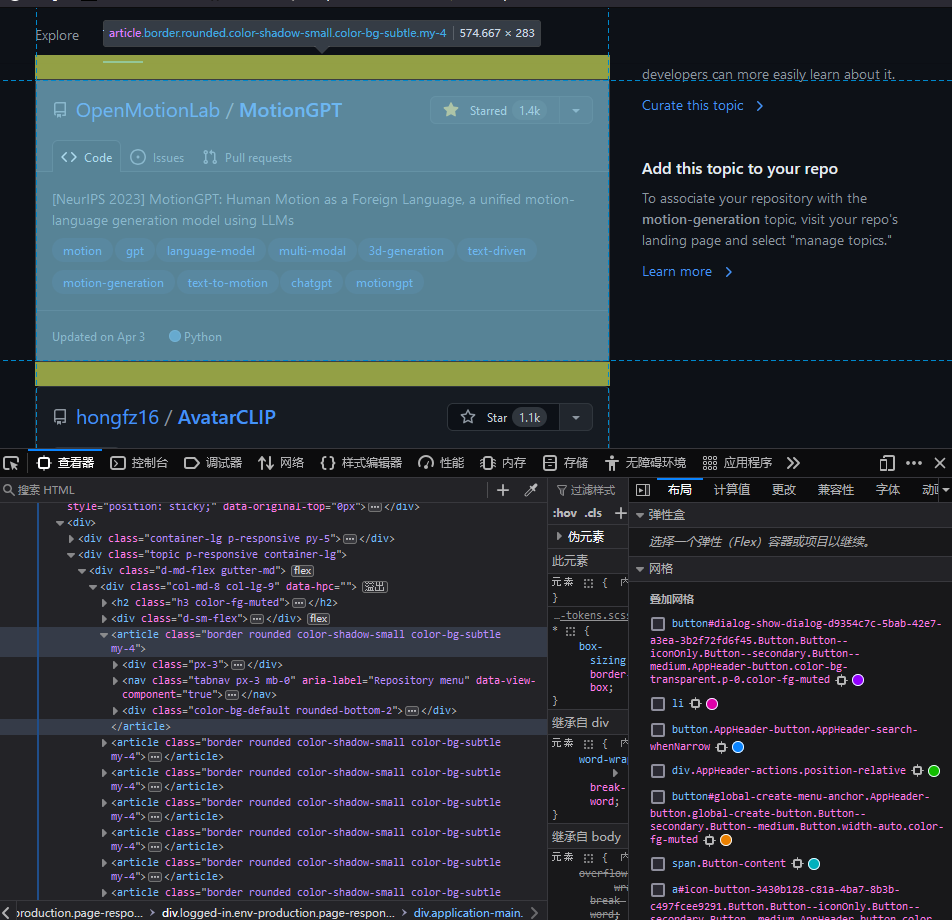
接下来我们需要对指定页面的HTML进行分析,以提取出我们想要的内容。在浏览器中F12打开开发者工具可以看到网页源码,并且鼠标悬停在代码上方可以在页面上看到对应区域高亮。这里我们需要提取的是库名字、库url、作者名字、star数以及库的描述信息,以其中一个为例:
可以观察到,所有文章项目都是在//div[@class="col-md-8 col-lg-9"]/article便签下的,进一步点开可以看到各个项目所在标签。因此我们可以用下面的代码提取出所有的article便签及他们的各个属性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 articles_tags = driver.find_elements(By.XPATH, '//div[@class="col-md-8 col-lg-9"]/article' ) for article in articles_tags: topic_item = TopicItems() topic_item.repo_name = article.find_element(By.XPATH, './/descendant::h3/a[@class="Link text-bold wb-break-word"]' ).text topic_item.repo_url = article.find_element(By.XPATH, './/descendant::h3/a[@class="Link text-bold wb-break-word"]' ).get_attribute('href' ) topic_item.author_name = article.find_element(By.XPATH, './/descendant::h3/a[@class="Link"]' ).text topic_item.stars = article.find_element(By.XPATH, './/descendant::span[@id="repo-stars-counter-star"]' ).text try : topic_item.description = article.find_element(By.XPATH, './/descendant::div[@class="px-3 pt-3"]/p' ).text except : topic_item.description = '' results.append(topic_item)
需要注意的是,这个页面使用AJAX来动态加载页面,当用户点击Load more...按钮时,AJAX会添加新的article到之前的article后面。因此我们可以先点击所有的Load more...,直到全部加载完之后再来抽取article标签。
1 2 3 4 5 6 7 8 9 10 while True : try : load_more_button = driver.find_element(By.XPATH, '//form[@class="ajax-pagination-form js-ajax-pagination"]/button' ) load_more_button.submit() WebDriverWait(driver, 15 ).until( EC.presence_of_element_located((By.XPATH, '//div[@class="col-md-8 col-lg-9"]/article' )) ) except : break
需要注意的是,AJAX加载需要时间,因此得显式地等待article标签加载出来,否则会爬取的不够全。
完整的代码参见:simple-scraper 。参考资料 :
XPath Tutorial Selenium with Python