





正在更新中……
秋招在即,用这篇博客记录一下求职过程中的一些与CV/多模态相关的知识汇总。
机器学习
损失函数
常用损失函数
均方误差(MSE,L2): (回归任务常用,隐含的预设是数据误差符合高斯分布)
绝对误差(MAE,L1):
二值交叉熵(BCE):;
交叉熵(CE):;(倾向于任务数据接近多项式分布)MAE和MSE的理解和区别
交叉熵伪代码
1
2
3
4
5
6
7
8
9def softmax(x):
exps = np.exp(x - np.max(x)) # 防止上溢
return exps / np.sum(exps)
def cross_entropy_error(p,y):
assert y.shape == y_hat.shape
delta=1e-7 #添加一个微小值可以防止负无限大(np.log(0))的发生。
p = softmax(p) # 通过 softmax 变为概率分布,并且sum(p) = 1
return -np.sum(y*np.log(p+delta))分类任务为什么常用交叉熵而不是MSE?
问题本质:交叉熵损失函数是为分类问题设计的,而均方误差是为回归问题设计的。分类问题的目标是预测一个离散的标签,而回归问题的目标是预测一个连续的值。交叉熵直接衡量的是预测概率分布与真实分布之间的差异。
梯度大小:交叉熵损失函数的梯度在预测错误时相对较大,这有助于模型在训练初期快速学习。而MSE的梯度随着预测值接近真实值而减小,这可能导致训练过程在后期变得缓慢。
归一化:交叉熵损失函数对类别进行了归一化处理,这意味着不同类别的预测误差对损失的贡献是相等的。而MSE可能会偏向于数值较大的类别。如何选择损失函数?
需要出于对数据分布的假设,不同的loss隐式地对数据分布有要求。例如L2隐含的是数据误差符合高斯分布。
评估指标
TP,FP,TN,FN
TP(True Positive): 预测为正,实际为正
FP(False Positive): 预测为正,实际为负
TN(True Negative):预测为负,实际为负
FN(false negative): 预测为负,实际为正Accuracy,Precision,Recall,F-Score, Macro-F1, Micro-F1
Accuracy = (TP+TN)/N
Precision = TP/(TP+FP)
Recall = TP/(TP+FN)
F1-Score = (2* Precision * Recall)/(Precision+Recall)P-R曲线,ROC, AUC
P-R曲线:横轴是Recall,纵轴是Precision。
ROC曲线:横轴是FPR=FP/N,纵轴是TPR=TP/N。
AUC(Area Under Curve):ROC曲线下的面积大小,AUC越大,说明分类器越可能把真正的正样本排在前面,分类性能越好。
SVM
支持向量机(supporr vector machine,SVM)是一种二类分类模型,该模型是定义在特征空间上的间隔最大的线性分类器。间隔最大使它有区别于感知机;支持向量机还包括核技巧,这使它成为实质上的非线性分类器。支持向量机的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的最小化问题。使用Hinge loss训练。
当训练数据线性可分时,通过硬间隔最大化(hard margin maximization)学习一个线性的分类器,即线性可分支持向量机,又成为硬间隔支持向量机;
当训练数据近似线性可分时,通过软间隔最大化(soft margin maximization)也学习一个线性的分类器,即线性支持向量机,又称为软间隔支持向量机;
当训练数据线性不可分时,通过核技巧(kernel trick)及软间隔最大化,学习非线性支持向量机。
K-means
K-means算法逻辑
K-means算法是一个实用的无监督聚类算法,其聚类逻辑依托欧式距离,当两个目标的距离越近,相似度越大。对于给定的样本集,按照样本之间的距离大小,将样本集划分为 K 个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
主要步骤:- 选择初始化的 k 个样本作为初始聚类中心 D = D1 , D2 , D3 , …, Dk 。
- 针对数据集中每个样本 xi ,计算它到 k 个聚类中心的距离并将其分到距离最小的聚类中心所对应的类中。
- 针对每个类别 Dj ,重新计算它的聚类中心 Dj 。(即属于该类的所有样本的质心)。
- 重复上面2和3两步的操作,直到达到设定的中止条件(迭代次数、最小误差变化等)。
手撕K-means
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29import numpy as np
# 生成随机数据
np.random.seed(0)
X = np.random.rand(100, 2)
# 定义K值和迭代次数
K = 3
max_iterations = 100
# 随机初始化簇中心点
centers = X[np.random.choice(X.shape[0], K, replace=False)]
# 迭代更新簇中心点
for _ in range(max_iterations):
# 计算每个数据点到每个簇中心点的欧氏距离
distances = np.linalg.norm(X[:, np.newaxis, :] - centers, axis=2)
# 分配每个数据点到最近的簇
labels = np.argmin(distances, axis=1)
# 更新簇中心点为每个簇的平均值
new_centers = np.array([X[labels == k].mean(axis=0) for k in range(K)])
# 如果簇中心点不再改变,结束迭代
if np.all(centers == new_centers):
break
centers = new_centers
KNN
KNN算法逻辑
KNN是一种非参数有监督分类算法。K近邻(K-NN)算法计算不同数据特征值之间的距离进行分类。存在一个样本数据集合,也称作训练数据集,并且数据集中每个数据都存在标签,即我们知道每一个数据与所属分类的映射关系。接着输入没有标签的新数据后,在训练数据集中找到与该新数据最邻近的K个数据,然后提取这K个数据中占多数的标签作为新数据的标签(少数服从多数逻辑)。(训练可以使用KD树加速)
主要步骤:- 计算新数据与各个训练数据之间的距离。
- 选取距离最小的K个点。
- 确定前K个点所在类别的出现频率
- 返回前K个点中出现频率最高的类别作为新数据的预测分类。
手撕KNN
1
2
3
4
5
6
7def knn_code(loc, k=5, order=2 ): # k order是超参
# print(order)
diff_loc = X - loc
dis_loc = np.linalg.norm(diff_loc, ord=order, axis=1) # 没有axis得到一个数,矩阵的泛数。axis=0,得到两个数
knn = y[dis_loc.argsort()[:k]]
counts = np.bincount(knn)
return np.argmax(counts)
PCA
对原始样本进行中心化处理,即零均值化.
求出样本的协方差矩阵。
求解协方差矩阵的特征值和特征向量。
将特征值由大到小排列,取出前 k 个特征值对应的特征向量。
将 n 维样本映射到 k 维,实现降维处理。
其他
- 常见数据集划分方法
留出法(hold-out) 直接将数据集划分为两个互斥的集合,其中一个集合作为训练集,另一个作为测试集。在训练集上训练出模型后,用测试集来评估其测试误差,作为对泛化误差的估计。
k折交叉验证(k-fold cross validation) 通过分层抽样的方法,将数据集划分为k个大小相似的互斥子集。选择k-1个子集合并作为训练集,用于模型的训练,而剩下的一个子集则作为测试集,用于评估模型的性能。这个过程重复k次,每次选择不同的子集作为测试集,从而获得k组不同的训练/测试集组合。这种方式可以对模型进行k次独立的训练和测试,最终得到一个更加稳健和可靠的性能评估结果
自助法(boostrapping) 通过采用有放回抽样的方法,我们每次从原始数据集D中随机选择一个样本,并将其复制到新的数据集D’中。这个过程重复进行m次,从而创建了一个包含$m$个样本的训练集D’。根据概率论的公式,这种有放回抽样的方式意味着每个样本在m次抽样中都不被选中的概率是(1-1/m)^m。当m趋向于无穷大时,这个概率的极限值为36.8%。因此,可以预期大约有36.8%的原始样本不会出现在新数据集D’中,这些未出现在D’中的样本可以用来作为测试集,以评估模型的性能。
- 判别式模型和生成式模型的区别
判别式模型
目标:直接学习输入数据 X 和标签 Y 之间的决策边界,即条件概率 P ( Y | X ) 。
任务:对未见数据X ,根据 P ( Y | X ) 可以求得标签 Y ,即可以直接判别出来未见数据的标签,主要用于分类和回归任务,关注如何区分不同类别。
例子:逻辑回归、支持向量机(SVM)、神经网络、随机森林等。
生成式模型
目标:学习输入数据 X 和标签 Y 的联合概率分布 P ( X , Y ) ,并通过它推导出条件概率 P ( Y | X ) 。
任务:不仅用于分类,还可以生成新的数据样本、建模数据的分布。
例子:扩散模型、高斯混合模型(GMM)、隐马尔可夫模型(HMM)、朴素贝叶斯、生成对抗网络(GAN)等。
- 基础信息论:熵,交叉熵,KL散度,JS散度,互信息
熵:衡量了一个概率分布的随机性程度,或者说它包含的信息量的大小。
公式:
对于离散型随机变量:;
交叉熵:定义于两个概率分布之上,反映了它们之间的差异程度
公式:;
交叉熵不具有对称性,H(p,q) != H(q,p);
KL散度:也叫相对熵,用于度量两个分布之间的差异。
公式:;
与交叉熵的关系:;
JS散度:KL散度是不对称的,会因为不同的顺序造成不一样的训练结果。
公式:;
互信息:变量间相互依赖性的量度。
公式:;
数据类别不平衡怎么办?
- 数据增强。
- 对少数类别数据做过采样,多数类别数据做欠采样。
- 损失函数的权重均衡。(不同类别的loss权重不一样,最佳参数需要手动调节)
- 采集更多少数类别的数据。
- Focal loss
什么是过拟合?解决办法有哪些?
过拟合:模型在训练集上拟合的很好,但是模型连噪声数据的特征都学习了,丧失了对测试集的泛化能力。
解决过拟合的方法:- 重新清洗数据,数据不纯会导致过拟合,此类情况需要重新清洗数据或重新选择数据。
- 增加训练样本数量。使用更多的训练数据是解决过拟合最有效的手段。我们可以通过一定的规则来扩充训练数据,比如在图像分类问题上,可以通过图像的平移、旋转、缩放、加噪声等方式扩充数据;也可以用GAN网络来合成大量的新训练数据。
- 降低模型复杂程度。适当降低模型复杂度可以避免模型拟合过多的噪声数据。在神经网络中减少网络层数、神经元个数等。
- 加入正则化方法,增大正则项系数。给模型的参数加上一定的正则约束,比如将权值的大小加入到损失函数中。
- 采用dropout方法,dropout方法就是在训练的时候让神经元以一定的概率失活。
- 提前截断(early stopping),减少迭代次数。
- 集成学习方法。集成学习是把多个模型集成在一起,来降低单一模型的过拟合风险,如Bagging方法。
常用正则化手段
- L范数
- Dropout
- BatchNorm
- Early Stopping
- 数据增强
- 对抗训练
深度学习
激活函数
激活函数作用
如果不用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合,这种情况就是最原始的感知机(Perceptron)。使用激活函数能够给神经元引入非线性因素,使得神经网络可以任意逼近任何非线性函数,使深层神经网络表达能力更加强大,这样神经网络就可以应用到众多的非线性模型中
激活函数分类

常见激活函数
Sigmoid
数学表达式:;
导数表达式:;
函数图像:缺点:容易造成梯度消失;消耗计算资源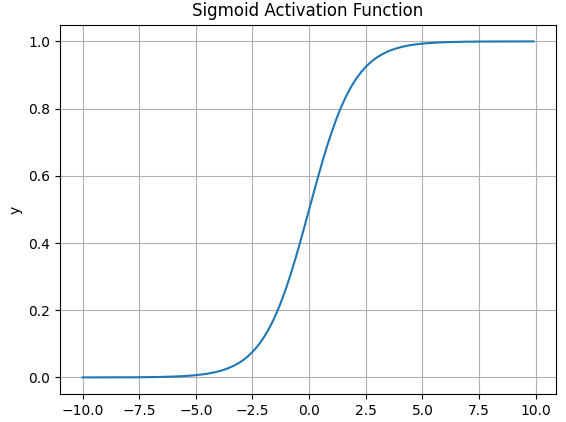
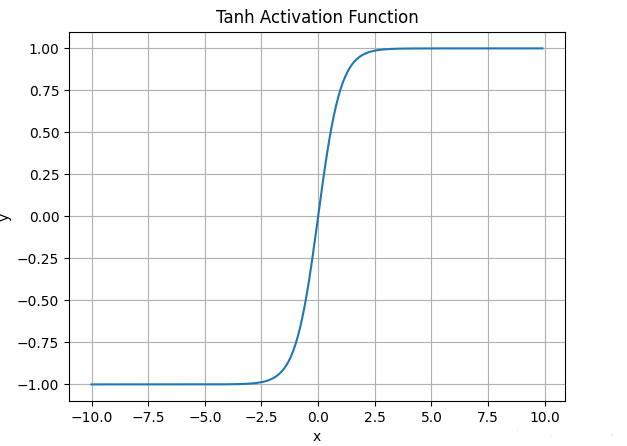
Tanh
数学表达式:;
函数图像:缺点:与Sigmoid类似
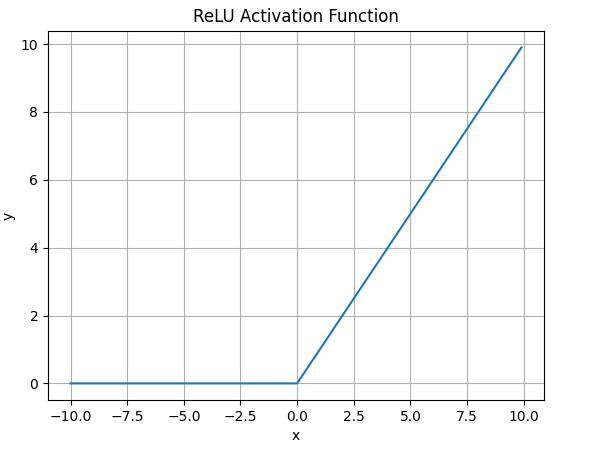
ReLU
数学表达式:;
函数图像:优点:相较于上面的改进:解决了梯度消失,当输入为正时,不会饱和;由于ReLU线性非饱和的性质,在SGD中能快速收敛;计算复杂度低。 缺点:与Sigmoid一样不是以0为中心的;Dead ReLU,当输入为负时,梯度为0。这个神经元及之后的神经元梯度永远为0,不再对任何数据有所响应,导致相应参数永远不会被更新。
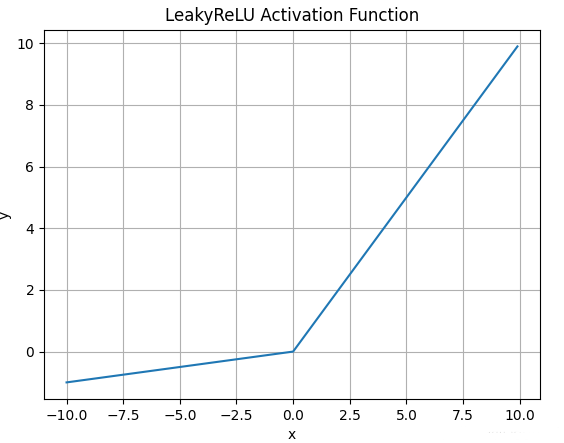
LeakyReLU
数学表达式:;
函数图像:优点:解决了Dead ReLu问题;线性非饱和;计算复杂度低。 缺点:a需要先验知识人工赋值。
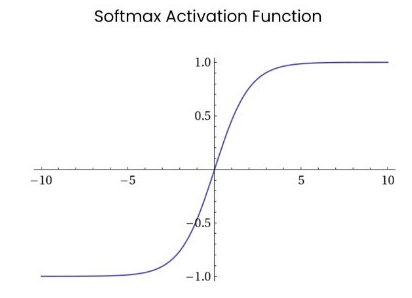
Softmax
数学表达式:;
函数图像:Softmax函数常在神经网络输出层充当激活函数,将输出层的值通过激活函数映射到0-1区间,将神经元输出构造成概率分布,用于多分类问题中,Softmax激活函数映射值越大,则真实类别可能性越大。
GLU
Swish
SwiGLU
CNN
- CNN的感受野
- CNN的参数量计算
- 空洞卷积
- Numpy手搓卷积
- Numpy手搓Filter
RNN,GRU,LSTM
目标检测
- NMS描述及手写
- IOU计算及手写
- 目标检测单双阶段
- Anchor-free和Anchor-based
- YoloV5和YoloV8的区别
- Focal loss
Transformer
Encoder,Decoder
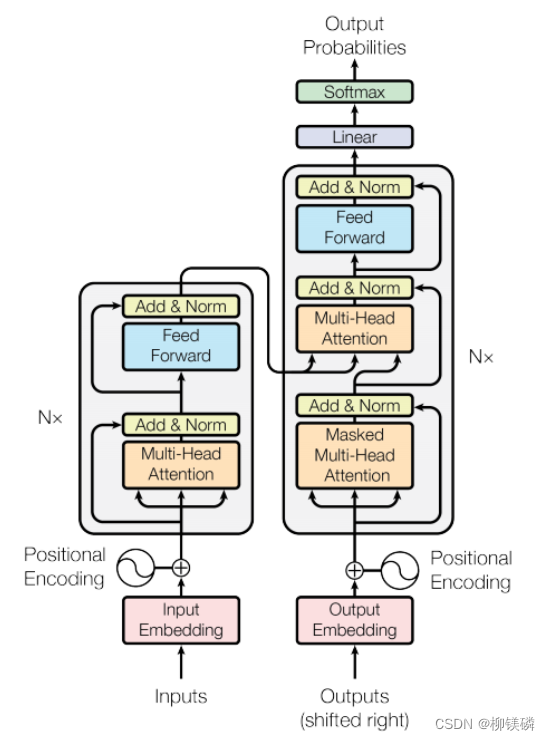
Transformer结构描述
见下图
简述Transformer中的FFN。
使用了ReLU作为激活函数。
Decoder和Encoder是如何进行交互的?
Cross attention。Decoder提供Q,Encoder提供K,V。
Decoder和Encoder结构的差别
Encoder的MHSA中需要对padding部分进行mask;Decoder部分的第一个MHSA是self-attention,并且这部分需要引入casual mask避免后面的序列看到前面的序列;Decoder部分的第二个MHA是Cross-attention,其中Q来自前一部分的输出,K,V来自Encoder的输出。
Decoder在预测Next word时要注意什么?
解码策略:Random sampling, Greedy search, Beam search,Top-k。
残差的作用
与Resnet相同,解决梯度消失,防止过拟合,加速模型收敛。
Transformer是如何做到并行的?
在Encoder的并行化主要体现在Self-attention模块,可以并行处理整个序列,并得到整个输入序列经过Encoder端的输出,但RNN只能从前到后的串行执行。
在Decoder端,训练的时候使用Teacher-forcing训练方式,因此也可以并行;但推理的时候仍然是自回归的模式。RNN,CNN和Transformer的区别
RNN(递归神经网络):
时间序列处理:RNN特别适用于处理序列数据,如时间序列、自然语言等。
递归结构:RNN通过递归地应用相同的权重来处理序列中的每个元素,允许信息在序列中流动。
参数共享:在序列的每个时间步上,RNN使用相同的权重矩阵。
问题:RNN在处理长序列时可能会遇到梯度消失或梯度爆炸的问题,这限制了它们学习长期依赖关系的能力。
CNN(卷积神经网络):
空间特征提取:CNN主要用于图像处理,通过卷积层提取图像的空间特征。
局部连接:每个卷积神经元只与输入数据的一个局部区域相连接,这减少了参数的数量。
参数共享:卷积核在整个输入数据上滑动,共享相同的权重。
层次结构:CNN通常具有多个卷积层,每个层级可以捕捉不同级别的特征。
应用:CNN在图像分类、目标检测和图像分割等领域非常成功。
Transformer:
自注意力机制:Transformer使用自注意力机制来处理序列数据,允许模型在编码每个元素时考虑到序列中的所有其他元素。
并行处理:由于自注意力机制,Transformer可以并行处理序列中的所有元素,这大大提高了训练效率。
无循环结构:与RNN不同,Transformer没有递归或循环结构,这使得它们在处理长序列时更加有效。
多头注意力:Transformer通常使用多头注意力,这允许模型同时学习序列数据的多个表示。
应用:Transformer在自然语言处理任务中非常流行,如机器翻译、文本摘要和问答系统。
总结来说,RNN适合处理序列数据,但可能在长序列上遇到训练问题;CNN擅长提取图像的空间特征,但在处理序列数据时可能不是最佳选择;而Transformer通过自注意力机制有效地处理序列数据,且能够并行处理,使其在自然语言处理任务中非常有效。每种架构都有其优势和局限性,选择哪一种取决于具体的应用场景和数据类型
Attention
- Attention机制描述
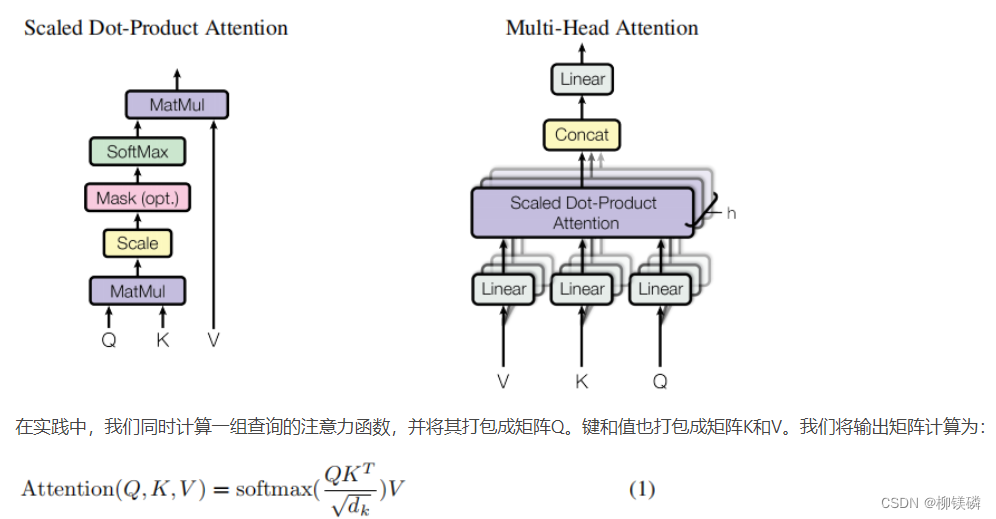
- Attention的复杂度
单头注意力的计算复杂度:
假设输入序列长度为,输出序列长度为,词向量的维度为。计算复杂度约为。
多头注意力的计算复杂度:
假设输入序列长度为,输出序列长度为,词向量的维度为,有,每个头的维度为。计算复杂度约为。
尽管Multi-head attention引入了多个头,但由于每个头的维度减小,并且计算可以并行进行,其总计算复杂度与单头Attention相同,即O(L⋅M⋅d)O(L⋅M⋅d)。然而,实际应用中,由于并行计算和维度分割,Multi-head attention通常能够更有效地利用计算资源。
Attention中为什么除以sqrt(k)?
在计算时,假设Q和K的维度为,其中每个元素期望值是0,方差为1,,这使得的期望为0,方差为。因此,在计算softmax时,如果比较大,的值也会很大,导致softmax输出非常尖锐的分布,会出现指数溢出或梯度消失的问题,难以训练。因此对进行缩放,是的每个元素的方差变为1,避免了上述问题。
综上,提升了模型的训练效果和稳定性在计算Attention score时,如何对Padding做mask?
一般有两种方式:
- Padding mask:将填充位置对应的token设置为一个很大的负数(如负无穷),这样在进行softmax计算式,填充位置对应的权重就会趋近于0,这样计算注意力时就不会考虑填充位置的信息。
- Masked softmax: 在softmax之前,将填充位置对应的token的score设置为一个很小的值,然后再进行softmax。
为什么要用Multi-head Attention?
- 并行计算: 多头注意力机制允许模型同时关注输入序列的不同部分,每个注意力头可以独立计算,从而实现更高效的并行计算。这样能够加快模型的训练速度。
- 提升表征能力: 通过引入多个注意力头,模型可以学习到不同类型的注意力权重,从而捕捉输入序列中不同层次、不同方面的语义信息。这有助于提升模型对输入序列的表征能力。
- 降低过拟合风险:多头注意力机制使得模型可以综合不同角度的信息,从而提高泛化能力,降低过拟合的风险。
- 降低计算复杂度: 通过对每个头进行降维,使得每个头的参数量减少,进而降低计算复杂度。
- 手搓Multi-head attention
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, heads, d_model, dropout=0.1):
super().__init__()
self.d_model = d_model
self.d_k = d_model // heads # 每个“头”对应的维度
self.h = heads # “头”的数量
# 初始化线性层,用于生成Q,K,V
self.q_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
# 输出线性层
self.out = nn.Linear(d_model, d_model)
def attention(self, q, k, v, mask=None):
# 计算点积,并通过 sqrt(d_k) 进行缩放
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k)
# 如果有 mask,应用于 scores
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 对 scores 应用 softmax
scores = F.softmax(scores, dim=-1)
# 应用 dropout
scores = self.dropout(scores)
# 获取输出
output = torch.matmul(scores, v)
return output
def forward(self, q, k, v, mask=None):
batch_size = q.size(0)
# 对 q,k,v 进行线性变换
q = self.q_linear(q).view(batch_size, -1, self.h, self.d_k).transpose(1, 2)
k = self.k_linear(k).view(batch_size, -1, self.h, self.d_k).transpose(1, 2)
v = self.v_linear(v).view(batch_size, -1, self.h, self.d_k).transpose(1, 2)
# 进行多头注意力计算
scores = self.attention(q, k, v, mask)
# 将多个头的输出拼接回单个张量
concat = scores.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
# 通过输出线性层
output = self.out(concat)
return output
Positional Encoding
Positional Encoding的作用
因为self-attention是位置无关的,无论句子的顺序是什么样的,通过self-attention计算的token的hidden embedding都是一样的,这显然不符合人类的思维。因此要有一个办法能够在模型中表达出一个token的位置信息,transformer使用了固定的positional encoding来表示token在句子中的绝对位置信息。
Transformer使用的位置编码
Sinusoidal Positional Encoding。这是一种绝对位置编码。的内积会随着相对位置的递增而减小,从而表征位置的相对距离,但由于距离的对称性,此方法虽然能够反应相对位置的距离,但是无法区分方向,即。见下图
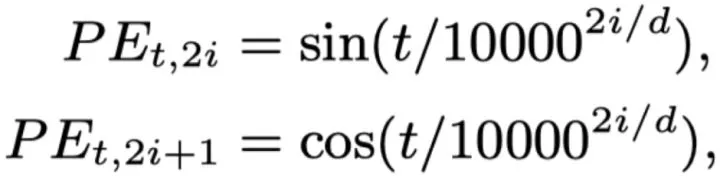
什么是大模型的外推性?
外推性是指大模型在训练时和预测时的输入长度不一致,导致模型的泛化能力下降的问题。
不同种Positional Encoding
此处参考苏神的文章
绝对位置编码:- Learnable Positional Encoding:直接将位置编码当作可训练参数。BERT,GPT,ALBERT等模型用的就是这种。缺点是没有外推性,无法感知相对位置。
- Sinusidal Positional Encoding:虽然pos+k可以被pos线性表示,这提供了表达相对位置信息的可能性,但不能表示方向。还具有远程衰减的性质。没有外推性。
- Autoregressive:RNN就属于这种,它本身自带位置信息。
相对位置编码:相对位置并没有完整建模每个输入的位置信息,而是在算Attention的时候考虑当前位置与被Attention的位置的相对距离。这一部分需要继续学习《Self-attention with Relative Position Representation》等文章。
- 显式的相对位置(Self-attention with Relative Position Representation):对于第m和第n个位置的token,其相对位置可以表示为,即两个token之间的相对距离。因此,相比于绝对位置,相对位置只需要有个表征向量即可,即在计算两个token之间的attetnion score时,只需要在attention中注入相对位置表征向量即可。这样可以表征任意长度的句子:
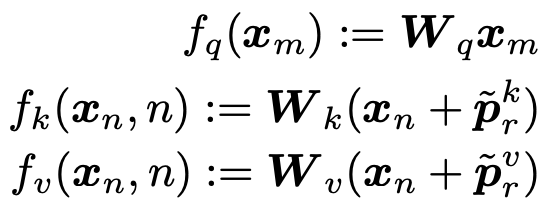
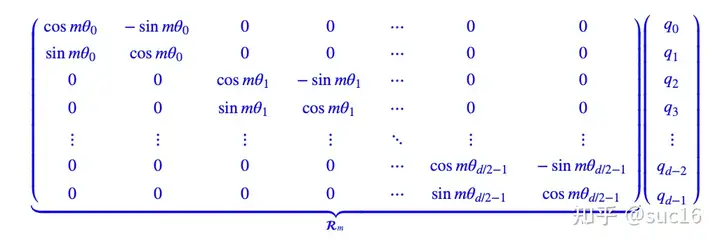
旋转位置编码(RoPE):通过绝对位置编码的方式实现了相对位置编码,对attention中的q、k向量注入了绝对位置信息,qk内积就会引入相对位置信息。(具体推导见苏神论文)见下图:
这里的\theta采取的和Transformer中一致,可以带来远程衰减的性质。
- 手撕Sinusoidal PE
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
#pe.requires_grad = False
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:x.size(0), :]
BatchNorm,LayerNorm,Dropout,etc
- BatchNorm原理
训练时前向传导见下图:
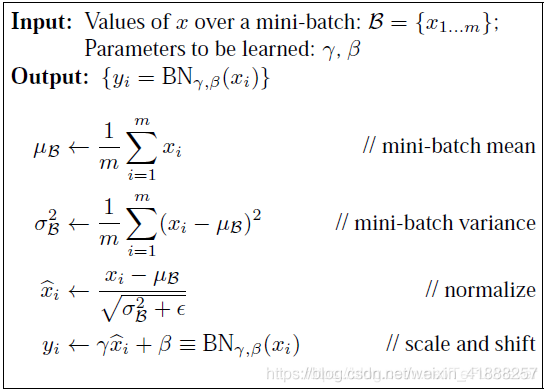
包含可学习参数,让网络可以学习恢复出原始数据的特征分布。同时也保存整个训练集的,使用移动平均法更新。
BatchNorm的优劣
优点:解决内部协变量偏移,加速模型收敛;增强模型稳定性,允许使用更高的学习率,提高模型泛化能力。
缺点:对batch size敏感(batch size较小时效果差,可用Group Normalization代替);不适用于变长序列;在推理阶段额外计算。BatchNorm训练和推理时的区别
我们在预测阶段,有可能只需要预测一个样本或很少的样本,没有像训练样本中那么多的数据,这样的要怎么计算呢?利用训练集训练好模型之后,其实每一层的BN层都保留下了每一个batch算出来的(使用移动平均得到),利用整体训练集的无偏估计来估计测试集的。即,然后再用学习到的参数进行BN。
其他的Norm方法
不同种Norm方法之间区别如下图:
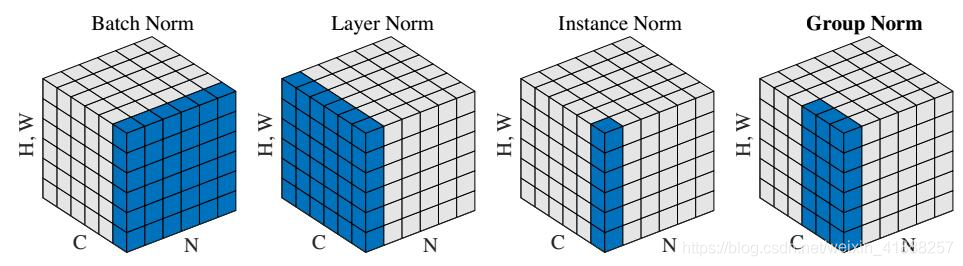
BatchNorm:batch 方向做归一化,算 N ∗ H ∗ W 的均值
LayerNorm:channel 方向做归一化,算 C ∗ H ∗ W 的均值
InstanceNorm:一个 channel 内做归一化,算 H ∗ W 的均值
GroupNorm:将 channel 方向分 group ,然后每个 group 内做归一化,算 ( C / / G ) ∗ H ∗ W 的均值
- Transformer中用BatchNorm可以吗?
LN是针对每个样本序列进行归一化,没有样本间依赖,对一个序列的不同特征维度进行归一化。
CV使用BN是因为认为通道维度的信息对cv方面有重要意义,如果对通道维度也归一化会造成不同通道信息一定的损失。NLP认为句子长短不一,且各batch之间的信息没有什么关系,因此只考虑句子内信息的归一化。
LayerNorm是对每个样本的所有特征做归一化,BatchNorm是对一个batch样本内的每个特征做归一化。
手撕BatchNorm
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28def Batchnorm_simple_for_train(x, gamma, beta, bn_param):
"""
param:x : 输入数据,设shape(B,L)
param:gama : 缩放因子 γ
param:beta : 平移因子 β
param:bn_param : batchnorm所需要的一些参数
eps : 接近0的数,防止分母出现0
momentum : 动量参数,一般为0.9, 0.99, 0.999
running_mean :滑动平均的方式计算新的均值,训练时计算,为测试数据做准备
running_var : 滑动平均的方式计算新的方差,训练时计算,为测试数据做准备
"""
running_mean = bn_param['running_mean'] #shape = [B]
running_var = bn_param['running_var'] #shape = [B]
results = 0. # 建立一个新的变量
x_mean=x.mean(axis=0) # 计算x的均值
x_var=x.var(axis=0) # 计算方差
x_normalized=(x-x_mean)/np.sqrt(x_var+eps) # 归一化
results = gamma * x_normalized + beta # 缩放平移
running_mean = momentum * running_mean + (1 - momentum) * x_mean
running_var = momentum * running_var + (1 - momentum) * x_var
#记录新的值
bn_param['running_mean'] = running_mean
bn_param['running_var'] = running_var
return results , bn_param1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19def Batchnorm_simple_for_test(x, gamma, beta, bn_param):
"""
param:x : 输入数据,设shape(B,L)
param:gama : 缩放因子 γ
param:beta : 平移因子 β
param:bn_param : batchnorm所需要的一些参数
eps : 接近0的数,防止分母出现0
momentum : 动量参数,一般为0.9, 0.99, 0.999
running_mean :滑动平均的方式计算新的均值,训练时计算,为测试数据做准备
running_var : 滑动平均的方式计算新的方差,训练时计算,为测试数据做准备
"""
running_mean = bn_param['running_mean'] #shape = [B]
running_var = bn_param['running_var'] #shape = [B]
results = 0. # 建立一个新的变量
x_normalized=(x-running_mean )/np.sqrt(running_var +eps) # 归一化
results = gamma * x_normalized + beta # 缩放平移
return results , bn_param手撕LayerNorm
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39import torch
eps = 1e-5
class LayerNorm:
def forward(x, w, b):
# x is the input activations, of shape B,T,C
# w are the weights, of shape C
# b are the biases, of shape C
B, T, C = x.size()
# calculate the mean
mean = x.sum(-1, keepdim=True) / C # B,T,1
# calculate the variance
xshift = x - mean # B,T,C
var = (xshift**2).sum(-1, keepdim=True) / C # B,T,1
# calculate the inverse standard deviation: **0.5 is sqrt, **-0.5 is 1/sqrt
rstd = (var + eps) ** -0.5 # B,T,1
# normalize the input activations
norm = xshift * rstd # B,T,C
# scale and shift the normalized activations at the end
out = norm * w + b # B,T,C
# return the output and the cache, of variables needed later during the backward pass
cache = (x, w, mean, rstd)
return out, cache
def backward(dout, cache):
x, w, mean, rstd = cache
# recompute the norm (save memory at the cost of compute)
norm = (x - mean) * rstd
# gradients for weights, bias
db = dout.sum((0, 1))
dw = (dout * norm).sum((0, 1))
# gradients for input
dnorm = dout * w
dx = dnorm - dnorm.mean(-1, keepdim=True) - norm * (dnorm * norm).mean(-1, keepdim=True)
dx *= rstd
return dx, dw, dbPre norm和Post norm的区别
Pre-norm训练更稳定,Post-norm效果更好但是需要warm up,且对超参数敏感。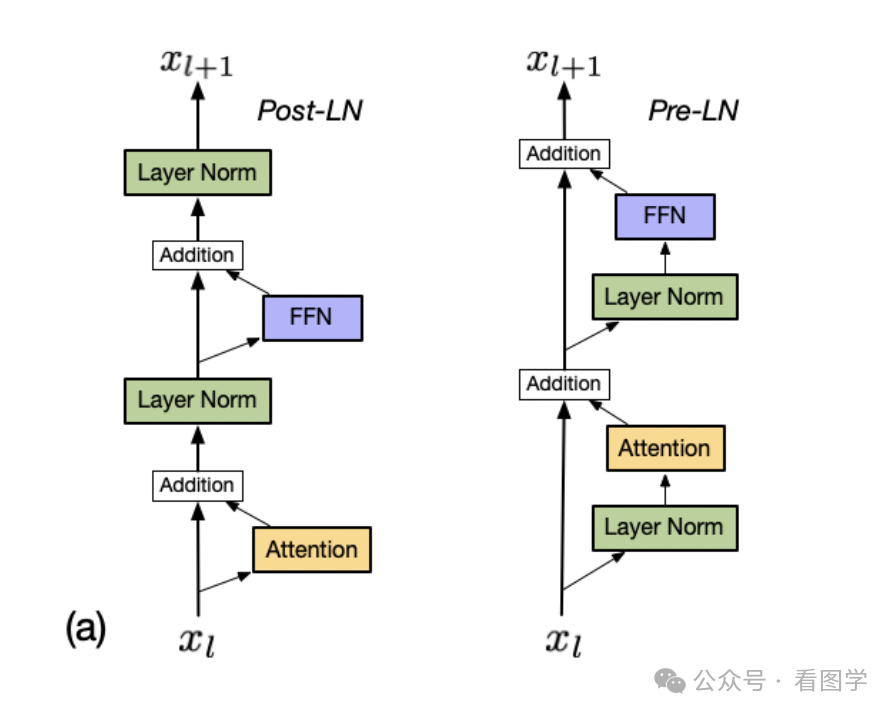
Dropout在训练和推理时的区别
训练时,随机屏蔽一部分神经元以防止过拟合;测试时,需要用完整的模型进行预测,因此禁用dropout。(可以通过model.eval())
使用dropout需要对神经元的输出重新缩放:- 假设dropout的保留率为p,在训练期间,一个神经元以概率p保留,其输出会被除以p来保持期望不变。
- 在测试期间,所有神经元保留,保持原始输出即可。
Dropout作用
是一种常用的正则化技术,训练时随机丢弃神经元,主要用于防止过拟合。
位置:Embedding之后;MHSA之后的Add&Norm之前;FFN的激活函数之后,Add&Norm之前;Decoder的最终输出层之前。
ViT
- ViT的结构描述
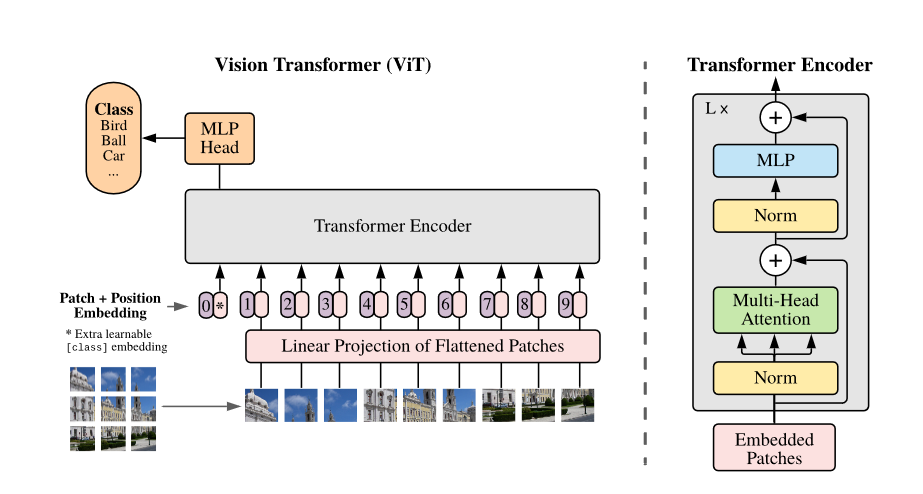
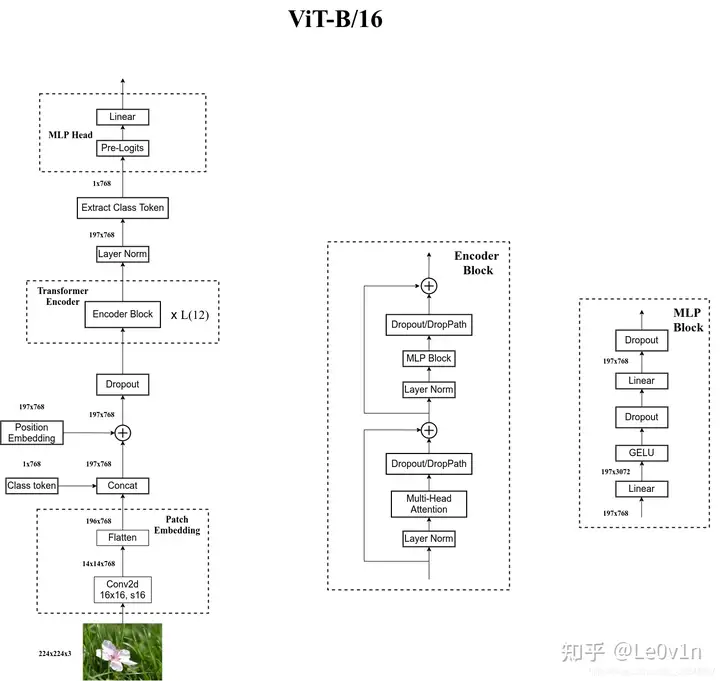
- 将图片patchify成P*P的patch,共N个patch。将每个patch进行flatten之后过一层线性层之后得到embedding。
- 与BERT类似,在patched embedding序列开头附加一个可学习的[class] token,来表示整个图片representation。
- 使用的位置编码为learnable 1D position embedding。
- 整体的结构为Transformer Encoder。
- 最后将[class] token的embedding过分类头。
- 微调时通常会使用更高分辨率,此时保持patch size不变,这样sequence length会变大,position embedding会不够用。文中采取的做法是进行2D插值拟合得到position embedding。
- 手撕ViT的patchify
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26class PatchEmbed(nn.Module):
"""
2D Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None):
super().__init__()
img_size = (img_size, img_size)
patch_size = (patch_size, patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
# flatten: [B, C, H, W] -> [B, C, HW]
# transpose: [B, C, HW] -> [B, HW, C]
x = self.proj(x).flatten(2).transpose(1, 2)
x = self.norm(x)
return x
优化器
BGD优化器
BGD采用整个训练集的数据来计算loss对参数的梯度。
优点:如果是凸优化一定能取得全局最优解,如果是非凸优化可以取得局部最优解
缺点:在一次迭代中,对整个数据集计算梯度,计算起来非常慢,遇到大型数据集会非常棘手。SGD优化器
SGD 可以避免 BGD 因为大数据集而造成的冗余计算,比如 BGD 会对相似的数据进行重复计算。SGD 则是每次只选择一个样本的数据来进行更新梯度。
优点:由于一次只用一个数据,因此梯度更新很快;当然也可以进行在线学习(不用收齐所有数据)。
缺点:因为震荡,很难收敛于一个精准的极小值。MBGD优化器
小批量随机梯度下降可以看作是 SGD 和 BGD 的中间选择,每次选择数量为 n 的数据进行计算,既节约的每次更新的计算时间和成本,也减少了 SGD 的震荡,使得收敛更加快速和稳定。
缺点:选择合适的学习率仍然是一个玄学;对于非凸问题极易陷入局部最优(鞍点)。Momentum优化器
公式:,一般取0.9.
优点: 加速收敛。Adagrad优化器
公式:
优点:减少了学习率的手动调节
缺点: 学习率会收缩并变得非常小。RMSprop优化器
为了解决AdaGrad学习率急剧下降问题的。
公式:
Adam优化器
是Momentum和RMSprop的结合体,需要保存梯度和梯度平方的指数加权平均。
公式:- 由于初始时刻没有什么可平均的,因此进行偏差修正,.
- 最后更新权重。
AdamW优化器
在Adam基础上加了L2正则化项,即optimizer参数中的weight_decay项。
其它
梯度消失和梯度爆炸及解决办法
梯度消失:梯度趋近于零,网络权重无法更新或更新的很微小,网络训练再久也不会有效果
原因:激活函数偏导过小,梯度连乘导致很低。
梯度爆炸:梯度呈指数级增长,变的非常大,然后导致网络权重的大幅更新,使网络变得不稳定
解决方法:梯度截断、梯度正则;使用ReLU、LeakyReLU等激活函数;引入BN层;使用残差结构。什么是warm up?
模型训练开始时使用非常小的学习率,再逐渐增大。
zero shot,few shot区别
Zero-shot: 利用训练集数据训练模型,使得模型能够对测试集的对象进行分类,但是训练集类别和测试集类别之间没有交集;期间需要借助类别的描述,来建立训练集和测试集之间的联系,从而使得模型有效。
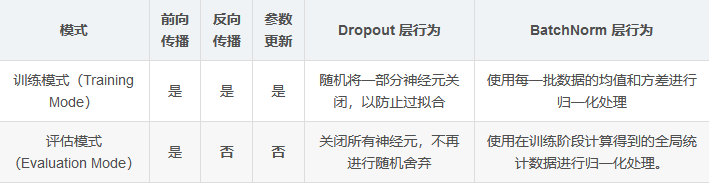
Few-shot: 旨在利用极少量的样本来训练模型,从而在新的任务中表现出良好的性能。这通常涉及到模型在预训练阶段获得大量的背景知识,然后在只提供几个新样本的情况下快速适应新任务。Pytorch中nn.eval函数和训练的区别
DDP时训练细节
并行训练的方式
模型加速、剪枝、量化的方法
权重初始化的方法
多模态
CLIP
CLIP模型结构
Image Encoder有两种架构:一种是ResNet50,将全局平均池化替换为注意力池化;第二种是ViT(Pre-norm)。
Text Encoder实际上是GPT-2架构,即Transformer decoder,将文本用[SOS]和[EOS]括起来,取[EOS]上的feature过一层Linear作为文本特征。CLIP训练时的损失函数
InfoNCE,一种用于自监督学习的特征表示学习损失函数。
公式:,N是样本的数量,q是查询样本的编码,k是与查询样本对应的正样本或负样本的编码。CLIP训练的伪代码

CLIP训练代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27image_embeds = vision_outputs[1]
image_embeds = self.visual_projection(image_embeds)
text_embeds = text_outputs[1]
text_embeds = self.text_projection(text_embeds)
# normalized features
image_embeds = image_embeds / image_embeds.norm(p=2, dim=-1, keepdim=True)
text_embeds = text_embeds / text_embeds.norm(p=2, dim=-1, keepdim=True)
# cosine similarity as logits
logit_scale = self.logit_scale.exp()
logits_per_text = torch.matmul(text_embeds, image_embeds.t()) * logit_scale
logits_per_image = logits_per_text.t()
loss = None
if return_loss:
loss = clip_loss(logits_per_text)
def contrastive_loss(logits: torch.Tensor) -> torch.Tensor:
return nn.functional.cross_entropy(logits, torch.arange(len(logits), device=logits.device))
def clip_loss(similarity: torch.Tensor) -> torch.Tensor:
caption_loss = contrastive_loss(similarity)
image_loss = contrastive_loss(similarity.t())
return (caption_loss + image_loss) / 2.0CLIP损失函数中温度系数的作用
如果温度系数设的越大,logits分布变得越平滑,那么对比损失会对所有的负样本一视同仁,导致模型学习没有轻重。
如果温度系数设的过小,则模型会越关注特别困难的负样本,但其实那些负样本很可能是潜在的正样本,这样会导致模型很难收敛或者泛化能力差。CLIP的位置编码,如何外推?
CLIP的text encoder是GPT,因此使用的Learable Positional Encoding,是绝对位置编码。理论上不能外推,但也许可以将超过长度的部分随机初始化然后微调。
BEiT
ALBEF,BLIP,BLIP-2,InstructBLIP
- BLIP,BLIP2架构和区别
- 描述一下Q-former
- 可学习的Query作用是什么?
- BLIP2时如何微调的?
- InstructBLIP
LLaVa
- LLaVa的结构
- LLaVa和BLIP2区别
- LLaVa两阶段的训练过程和数据集的构建
- LLaVa1.5和1.6的改进
Flamingo
其它
- 常见的多模态大模型,ChatGLM
- 多模态模型支持的任务类型
- 多模态中特征对齐和融合方法有哪些
- 其他对比学习方法(SimCLR等)
- 对比学习的本质是在解决什么问题,目的是什么?
本质上是自监督学习,即学习一个编码器,此编码器对同类数据进行相似的编码,并使不同类的数据的编码结果尽可能的不同。
- 对多模态领域的看法·
AIGC
VAE
- VQ-GAN和VQ-VAE
- VAE公式推导
GAN
- GAN和Diffsuion的优势,从分布映射的角度讲
- 为什么GAN不稳定,如何解决?
- GAN为什么会出现Mode collapse?
生成对抗网络(GAN)中的模式崩塌是指生成器网络只能生成有限的几种样本,而不能生成更多的样本。这种情况通常发生在训练过程中,生成器网络只学习到了一部分数据的特征,而没有学习到其他数据的特征。这导致生成器网络只能生成与这些数据相似的样本,而无法生成其他样本。
模式崩塌的原因可能是由于训练数据集过小或者过于相似,导致生成器网络只能学习到少量的数据特征。此外,GAN中的优化问题也可能导致模式崩塌。GAN的训练过程是一个非常复杂的优化问题,需要同时优化生成器和判别器网络。如果优化过程不充分或者不平衡,可能会导致生成器网络无法学习到更多的数据特征,从而出现模式崩塌。
- GAN怎么做Inversion
Diffusion
DDPM原理


去噪网络预测的是什么?
原始DDPM论文预测的是每一步的噪声,但是直接预测x0的方法也有。
DDIM原理
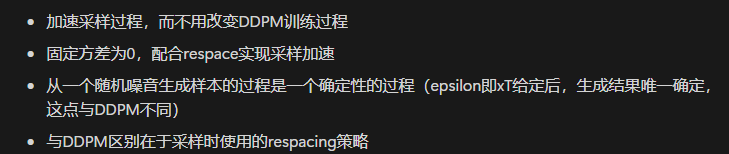

其他的加速采样方法DPM+,DPM++
Score-based Diffusion
Classifier guidance和Classifier-free guidance的区别和原理
LLM
GPT 1/2/3, InstructGPT
简述一下GPT的训练过程。
GPT的训练过程采用了预训练和微调的二段式训练策略。
- 非监督式预训练: 利用大规模无标记语料,构建预训练单向语言模型。训练目标是Language Modeling loss。
- 监督式微调: 用预训练的结果作为下游任务的初始化参数,增加一个线性层,匹配下游任务。训练目标是有监督的目标函数,并加上Language Modeling作为辅助目标。
GPT的Decoder与Transformer Decoder的区别
- 激活函数为GELU
- 位置编码为Learning Position embedding
- 去除了Cross attention。
- Tokenizer采用的是BPE。
为什么GPT是Decoder-only?
Transformer 结构提出是用于机器翻译任务,机器翻译是一个Seq2Seq的任务,因此 Transformer 设计了Encoder 用于提取源端语言的语义特征,而用 Decoder 提取目标端语言的语义特征,并生成相对应的译文。GPT目标是服务于单序列文本的生成式任务,所以舍弃了关于 Encoder部分以及包括 Decoder 的 Cross Attention 层。
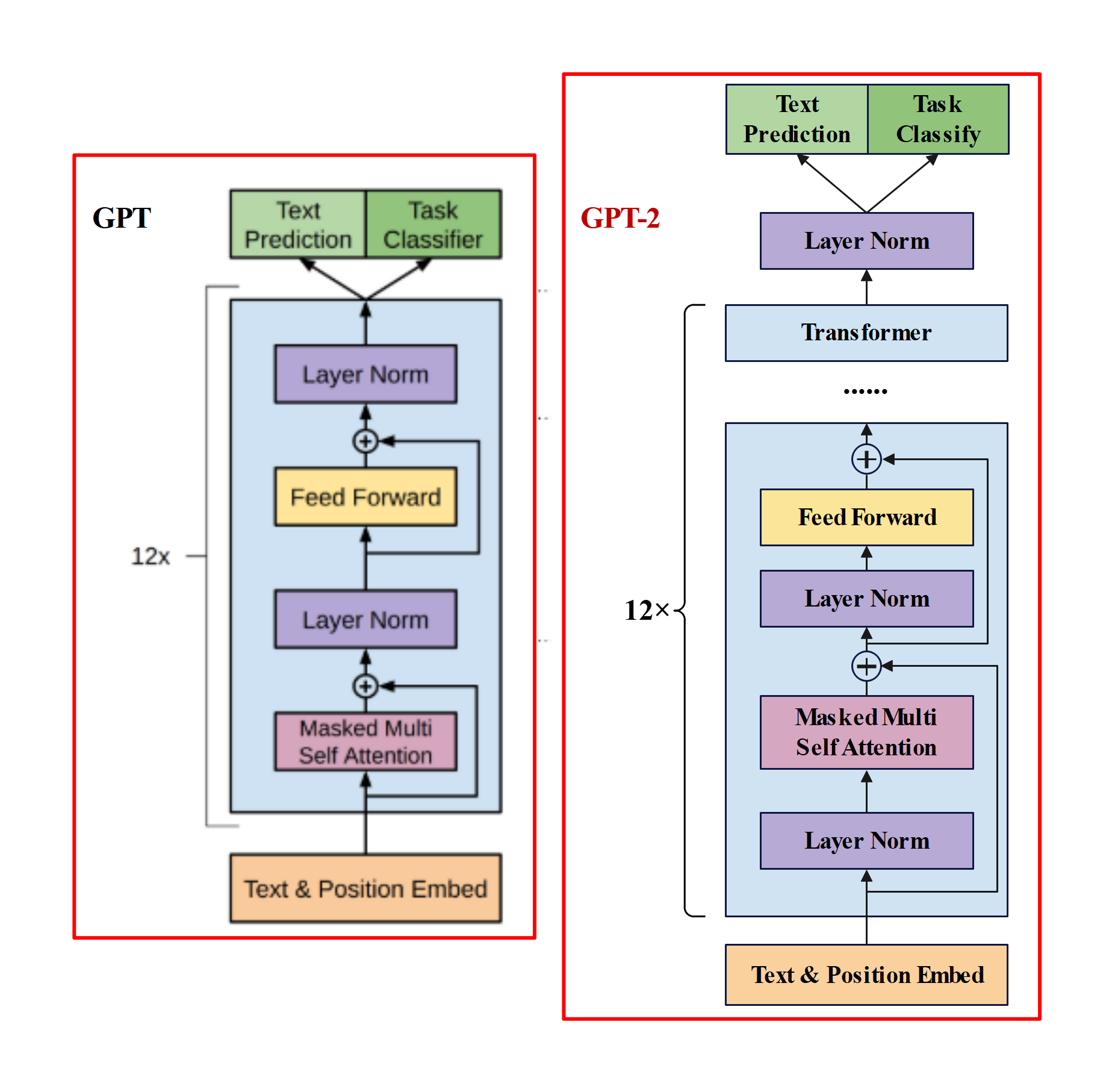
GPT-2与GPT的区别?
主推zero-shot,而GPT-1为pre-train+fine-tuning。
模型更大。参数量达到1.5B,而GPT只有0.117B.
数据集更大。
训练参数变化,batch_size 从 64 增加到 512,上文窗口大小从 512 增加到 1024。
模型结构变化:- 后置层归一化( post-norm )改为前置层归一化( pre-norm );
- 在模型最后一个自注意力层之后,额外增加一个层归一化;
- 调整参数的初始化方式,按残差层个数进行缩放,缩放比例为;
- 输入序列的最大长度从 512 扩充到 1024;
GPT-3与GPT-2区别?
GPT-2虽然提出zero-shot,比bert有新意,但是有效性方面不佳。GPT-3考虑few-shot,用少量文本提升有效性。
模型结构:- 大部分和GPT-2一样,但应用了Sparse attention。
论文尝试了四种方式的评估方法: - fine-tuning:预训练 + 训练样本计算loss更新梯度,然后预测。会更新模型参数.
- zero-shot:预训练 + task description + prompt,直接预测。不更新模型参数.
- one-shot:预训练 + task description + example + prompt,预测。不更新模型参数.
- few-shot(又称为in-context learning):预训练 + task description + examples + prompt,预测。不更新模型参数.
- 大部分和GPT-2一样,但应用了Sparse attention。
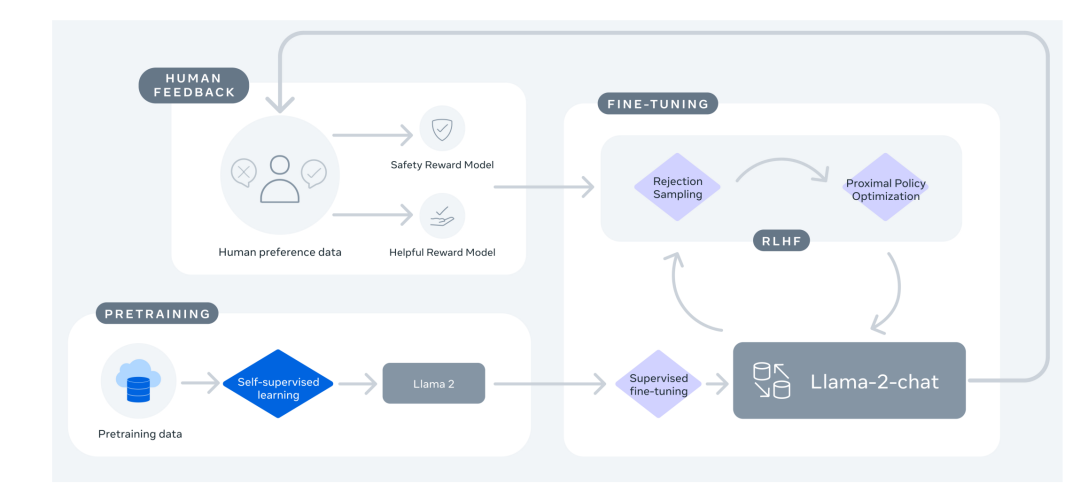
介绍一下InstructGPT。
为了和人类的需求对齐—— 主要由三个阶段组成 : (1) SFT(Supervised Fine-tuning):收集一系列人工标注的(Question,Response)作为数据集,使用LM目标函数监督学习微调GPT-3(16个epoch)。根据验证集上的RM分数,选择最终的SFT模型。 (2) RM(Reward Modeling):RM是训练一个Reward Model,将SFT模型最后的嵌入层去掉后的模型,它的输入是prompt和response,输出是标量的奖励值。奖励模型的损失函数如下,这里使用的是排序中常见的pairwise ranking loss。这是因为人工标注的是答案的顺序,而不是分数,所以中间需要转换一下。 (3) RL(PPO):训练RL policy,即之前SFT过的GPT-3。用SFT的GPT-3输出Response,用上一步训练的Reward Model输出标量作为Reward,来训练这个RL policy。为了确保输出的质量不降低,有时也会在PPO的目标函数之外额外加上加权的LM目标函数。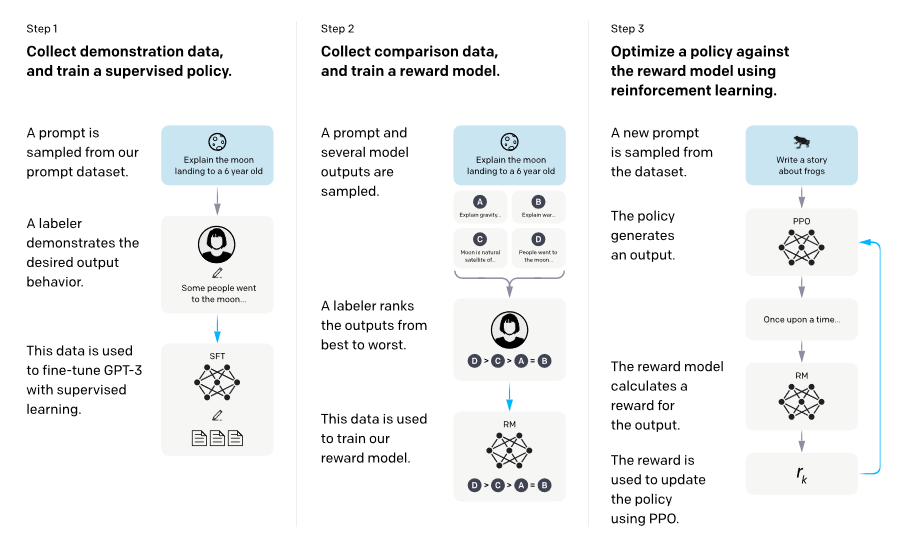
LLAMA
LLaMa介绍
预训练数据:全是开源数据。
Tokenizer: BPE implemented by SentecePiece,分词后训练集中共包含1.4T tokens。
模型架构:相比与原始Transformer架构,有如下改动- Pre-norm:参考GPT3,在transformer sub-layer前进行norm。使用的是RMSNorm。
- SwiGLU: 参考PaLM,使用SwiGLU作为激活函数。
- RoPE: 将PE换成了RoPE。
- 在casual MHA这里使用了更efficient的实现方式。
- 保存线性层输出的activation。
Optimizer: AdamW,同时用CosLR schedule。同时有0.1的weight decay和1.0的grad clip。有2000 steps的warm up。
在2048台A100-80GB上训练了21天。
LLAMA中的RMSNorm
RMSNorm(Root Mean Square Layer Normalization)
提出动机:LayerNorm计算量比较大。
主要区别:不需要同时计算均值和方差两个统计量,而只需要计算均方根这一个统计量(没有去中心化操作)。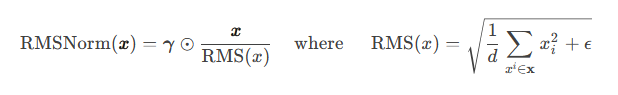
1 | class LlamaRMSNorm(nn.Module): |
LLAMA的loss函数
Language Modeling,即自回归预测next word的概率,实现方式为Cross Entropy。
也会有其他的预训练损失函数。LLAMA2的改进
* 预训练语料扩充到2T token。 * 上下文长度从2048翻倍到4096. * 引入了Grouped-query attention、KV cache等技术 * 在LLAMA2基础上进一步SFT(Supervised Fine-tuning)和RLHF,得到LLAMA2-Chat。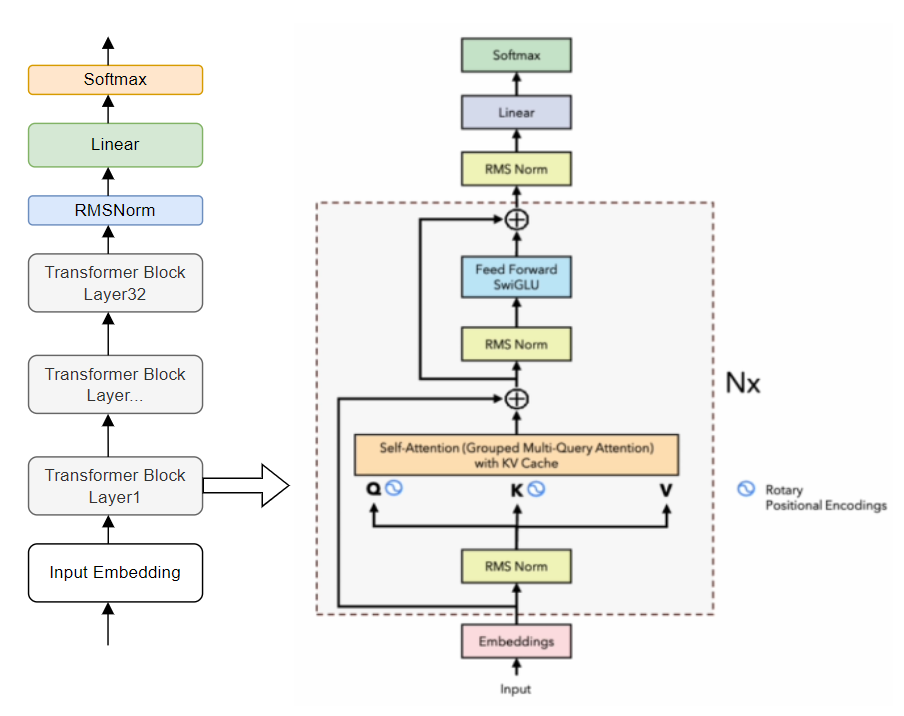
LLAMA3的改进
- 训练数据集比LLAMA2大7倍。
- 采用了数据并行、模型并行、管道并行等并行化技术。
- 结合了SFT,Rejection sampling、PPO、DPO对预训练模型进行指令微调。
BERT
- BERT结构和预训练任务
- BERT和GPT区别
ChatGLM
Qwen
PEFT
LoRA原理
LoRA假设微调变化矩阵的内在秩远低于原矩阵维度d,因此将变化矩阵分解为B和A,而原矩阵的权重不发生变化。这样使得可训练参数数量极大减少,降低显存消耗量。见下图:
初始时将A矩阵高斯随机初始化,将B矩阵初始化为0,这样变化矩阵在开始训练时是0。还需要将进行scale: ,其中分子为r中的一个常数,r为选取的秩。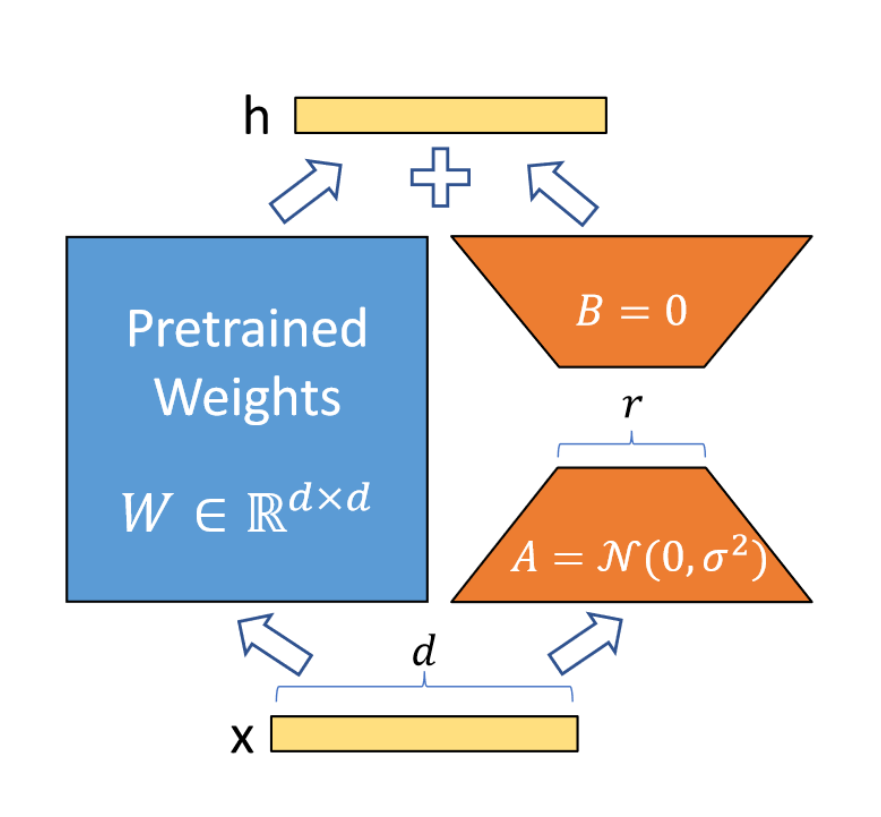
LoRA推理过程中有额外计算吗?
LoRA在推理时通常会将变化矩阵加在原矩阵上,这样并没有额外的计算开销,因此没有额外计算。
Lora初始化方式
A矩阵进行高斯分布初始化,B矩阵初始化为0.
LoRA应用于网络的哪些部分?
在Transformer中,可以应用于Attention中的Q,K,V矩阵和线性层,以及FFN中的两个MLP模块。能够大大降低微调参数量。
LoRA的r一般选取多少?
对于一般的任务,r=1,2,4,8 就足够了。而一些领域差距比较大的任务可能需要更大的r 。
LoRA的几种变种(QLoRA,etc)
LLaMa-Adapter介绍
Prompt tuning和Prefix tuning
P-tuning V1/V2的原理
其他
- 提示学习
- RAG流程
- 如何处理长文本?
- LLM的解码方式
- Encoder-only,Decoder-only,Encoder-Decoder的几种模型
- Tokenizer的种类和区别
- Text转Embedding的过程
- Flash attention
- Group Query Attention
- Sparse attention
- KV Cache
- PPO,DPO及其他强化学习算法
文生图
- 常见T2I模型
Stable Diffusion,Imagen,DALLE2
- Stable Diffusion模型原理
- Stable Diffusion生成结果如何评价,定量指标
- Stable Diffusion训练推理过程
- Stable Diffusion的各个模块
- 简述一下ControlNet,DreamBooth,LoRA,Adapter的原理,各自的优缺点
其它
- SAM效果好的原因