正在更新中……
秋招在即,用这篇博客记录一下算法岗求职过程中的一些必备知识汇总。
VAE
VAE
VAE模型
VAE公式推导
见知乎文章。
KL项的作用
KL loss类似于一个正则项,用于规范latent的范围,这也是与AE的最大区别。
VQ-VAE
VQ-VAE模型结构
前向时,Encoder出来的latent会与codebook中的code做最近邻,直接使用codebook中的code作为latent。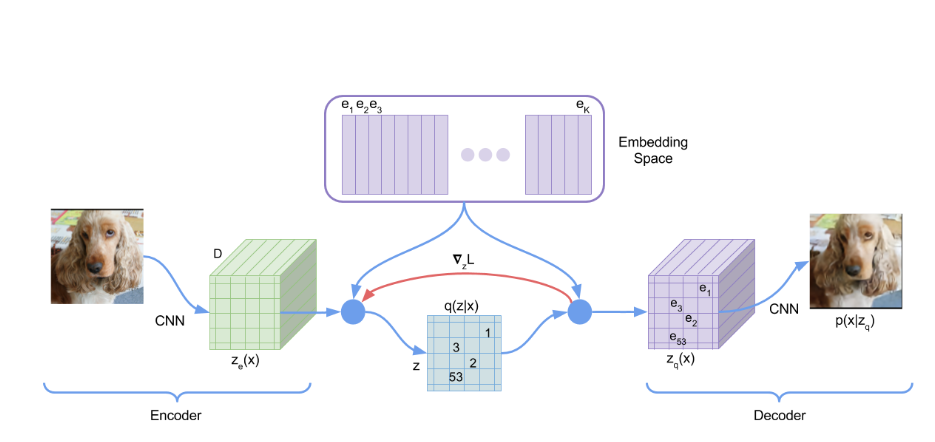
VQ-VAE实质上是AE,用来将图像进行压缩。如果要做到图像生成,可以使用PixelCNN来拟合离散的分布。(原文中做法)
VQ-VAE的优化目标
有三部分组成:reconstruction loss,VQ loss, commitment loss。
Reconstruction loss: 反向过程,encoder无法得到反传的梯度,这里采取的方法是将decoder的梯度复制到encoder。具体实现如下图。
即 L = x - decoder(z_e+(z_q-z_e).detach())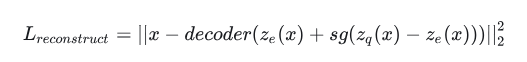
VQ loss:为了学习codebook,将codebook中的code与encoder的输出拉近。这一部分不反传给encoder。可以使用EMA算法实现。
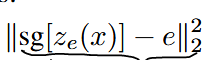
Commitment loss:Encoder和codebook的学习速度不同,为了不让encoder的输出偏离codebook太多,使用了commitment loss。这一部分不反传给codebook。
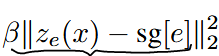
Encoder由Reconstruction loss和commitment loss优化,Decoder由Reconstruction loss优化,Codebook由VQ loss优化。
- VAE与VQ-VAE的区别
VAE是假设latent分布为高斯分布;VQ-VAE则是假设latent分布为类别分布。
GAN
GAN
GAN模型结构
生成器G,判别器D,先验分布Z(可以采用高斯噪声)。

GAN的损失函数
首先考虑判别器D,这是一个二分类问题,那么其损失函数为:
再考虑生成器G。G是要与D唱反调,那么G的目标就是最小化-L_D,即: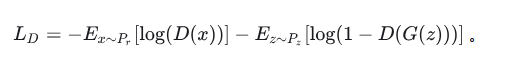 最终形成的损失函数,是如下的形式:
最终形成的损失函数,是如下的形式: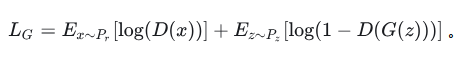 改进的版本如下:
改进的版本如下: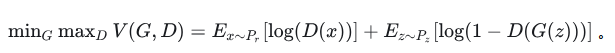 该损失函数可以证明其收敛性。(如果D对于所有的G都能够迅速变化为最优判别器,那么生成器G实际上是在最小化真实数据分布P_r与伪造数据分布P_f之间的JS散度)
该损失函数可以证明其收敛性。(如果D对于所有的G都能够迅速变化为最优判别器,那么生成器G实际上是在最小化真实数据分布P_r与伪造数据分布P_f之间的JS散度)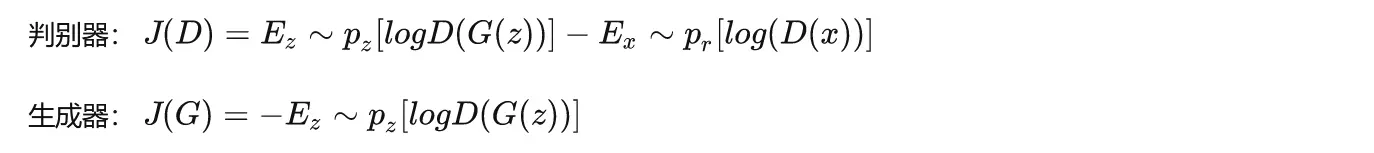
GAN的训练流程
每一轮更新中,(1)固定G,更新D;(2)固定D,更新G。

GAN的问题
- Mode collapse:生成器生成的图像都特别像。可能是数据集过小导致过拟合。
- Diminished gradient:判别器太强,导致gradients vanish使得生成器学不到新东西。
- 不收敛、经常过拟合、对超参数敏感。
WGAN与GAN的区别
除此之外还需要做梯度裁剪。
VQ-GAN
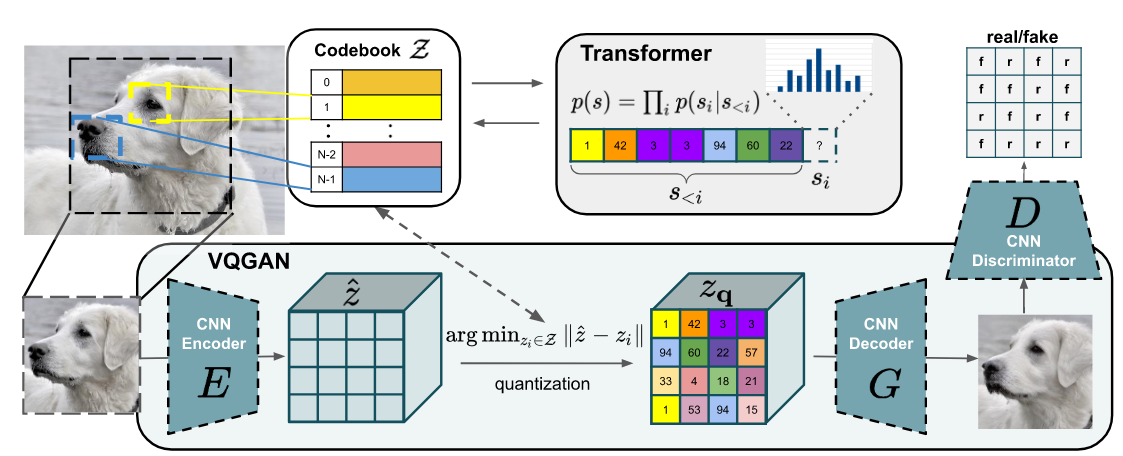
VQ-GAN与VQ-VAE的区别
- 将VQ-VAE中的先验生成器从PixelCNN改成了Transformer。
- 重建损失中将L2 loss换成了Perceptual loss。
- 在训练过程中使用PatchGAN的判别器加入对抗损失。
VQ-GAN的GAN部分训练过程
这一部分学习训练CNN Encoder,CNN Decoder和Codebook。
对于VQ部分,与VQ-VAE类似。将图片H* W* 3经过卷积后得到h* w* n的feature,与codebook进行最近邻后得到新的latent。这里将重建的L2 loss换成了Perceptual loss。
判别器使用了PatchGAN,这部分的loss为: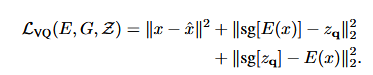 最后的优化目标为:
最后的优化目标为: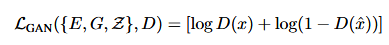
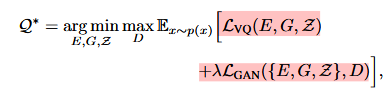
Perceptual loss是什么?

VQ-GAN的Transformer部分
这一部分训练Transformer作为先验分布来自回归地生成图像code,然后送给decoder得到生成的图像。训练过程与GPT训练过程类似,做Next-word-prediction;同时这里还进行了mask,所以不是传统的GPT训练方法。
Diffusion
DDPM

DDPM的前向加噪过程

DDPM的反向去噪过程

DDPM的训练过程

随机采样时间步t和前向噪声epsilon,用神经网络拟合该epsilon。
DDPM的采样过程

首先从高斯分布采样初始噪声xt,然后每一步预测出epsilon来还原x_{t-1}。由于x_{t-1}是有均值方差的高斯分布,因此
预测出epsilon还原出均值后,还需要从标准正态分布中随机采样一个z来加上方差。DDPM的生成是随机性过程吗?
是的。在DDPM的反向过程中,每一步都会采样一个噪声,然后利用这个噪声和前一步的输出来生成下一步的图像。这个过程是随机的,因为每一步都会引入新的随机性。
DDIM
DDIM的采样过程

DDIM的采样过程是非马尔可夫的,且由于eta设置为0,每一步去噪无需重采样高斯噪声(除了第一步采样x_t),因此采样过程是一个确定性过程。
单独DIIM并没有加速,加速使用respacing(按照一定间隔减小采样步数)。只不过respacing对DDPM使用会大幅降低生成效果,但是DDIM不会。所以DDIM+respacing又快又好。
DDIM的Inversion
DDIM除了可以确定性去噪外,还可以确定性加噪,从而实现Image editing。
DDPM与DDIM的区别
DDPM:固定sample方差为beta或者\hat{beta}。
DDIM:固定方差为0,配合respacing实现加速。
Score-based
DiT
DiT的主要结构
DiT是从LDM改进而来的,将LDM中的U-Net替换为Transformer,VAE仍然使用Stable Diffusion的。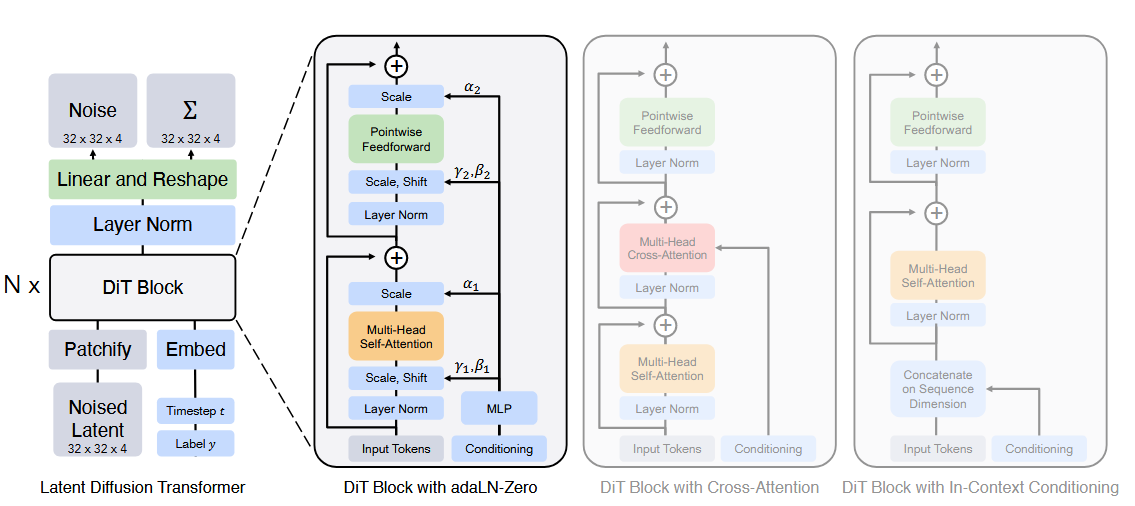
最后一个DiT block之后,将tokens decode为output noise prediction和covariance prediction。
DiT的Patchify过程
与ViT的一样,使用卷积将压缩后的z切分成一个一个的token,并嵌入位置信息。
DiT的不同条件注入机制
- In-context conditioning:将去噪时间步和条件c作为额外两个token附在输入序列前;最后一个block之后再将它们移除。
- Cross-attnetion:将去噪时间步和条件c连接成一个长度为2的序列,在原始transformer block中插入cross attention并注入条件。
- adaLN:将原始layerNorm替换为adaLN,即从t和c中回归得到scale和shift。
- adaLN-Zero:将每个ResBlock初始化为identity function。同时除了回归scale和shift外,同时在每个Residual connection前回归dimension-wise scale的参数。
AdaLN的实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class AdaLayerNorm(nn.Module):
def __init__(self, embedding_dim: int, num_embeddings: int):
super().__init__()
self.emb = nn.Embedding(num_embeddings, embedding_dim)
self.silu = nn.SiLU()
self.linear = nn.Linear(embedding_dim, embedding_dim * 2)
self.norm = nn.LayerNorm(embedding_dim, elementwise_affine=False)
def forward(self, x: torch.Tensor, timestep: torch.Tensor) -> torch.Tensor:
emb = self.linear(self.silu(self.emb(timestep)))
scale, shift = torch.chunk(emb, 2)
x = self.norm(x) * (1 + scale) + shift # 用 timestep 进行 affine
return x
Classifier Guidance
Classifier Guidance的推导

分类器是需要预训练的,训练数据和扩散模型的训练数据一致,且由于分类过程贯穿整个采样(i.e. t从T到0),因此分类器的训练数据还需要加上不同程度的噪音,来使得该分类器在噪音图片下依然可以起到引导作用。
s是一个大于1的系数。当s较大时,会更关注分类器,生成样本更符合y,但多样性更低,因此是一个保真度与多样性之间的trade-off。
DDPM中Classifier Guidance采样过程

DDIM中Classifier Guidance采样过程

Classifier Guidance的优点和缺点
优点: 不需要重新训练扩散模型,只需要在采样时根据分类器梯度修改采样的均值即可。
缺点:推理时每一步需要过分类器,速度较慢。
Classifier-free Guidance
CFG的推导

CFG的训练过程
训练时,Classifier-Free Guidance需要训练两个模型,一个是无条件生成模型,另一个是条件生成模型。但这两个模型可以用同一个模型表示,训练时只需要以一定概率将条件置空即可。
CFG的推理过程
推理时,需要同时得到cond和uncond的推理结果,按照上述公式对预测噪声进行线性外推。
其中,uncond也可以用negative prompt代替,这样可以实现不生成某些内容。
为什么需要两次推理分别得到cond和uncond?
通过线性外推方式,获得更多的生成多样性。
CFG的guidance_scale的作用
一般取7.5。guidance scale越大,生成的结果越倾向于输入条件,图像质量更高,多样性会下降;越小,多样性越大。
相比于Classifier Guidance的优点
- 不需要额外训练分类器。
- 更加灵活,因为它不依赖于特定的分类器,可以处理更广泛的条件。
- 采样时效率更高。
其他加速采样
- DPM,DPM++
文生图模型
Stable Diffusion(LDM)
SD 1.x/2.x
SD中的VAE。
Perceptual loss,Patch-based GAN loss。
为了避免latent太过无序,使用正则项对latent space进行规范。原文中使用了两种:(1)KL-reg,但权重设置得很小(过强的正则化会导致生成的图像模糊);(2)VQ-reg,使用很大的codebook。
SD中的VAE不具有生成功能,主要起的是压缩作用。
SD中VAE与普通VAE的区别
这里的KL只是起了规范latent的作用。而且原文中设置的KL设置的极小。(ELBO中过强的正则化会导致生成的图像模糊)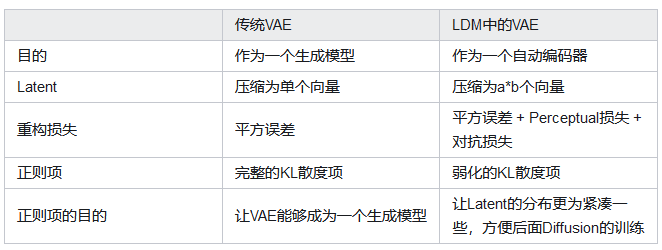
SD的U-Net结构及与DDPM中U-Net的区别。
其中时间步t在ResBlock中过线性层后与x相加;文本c在SpatialTransformer的cross attention中与flatten的x交互。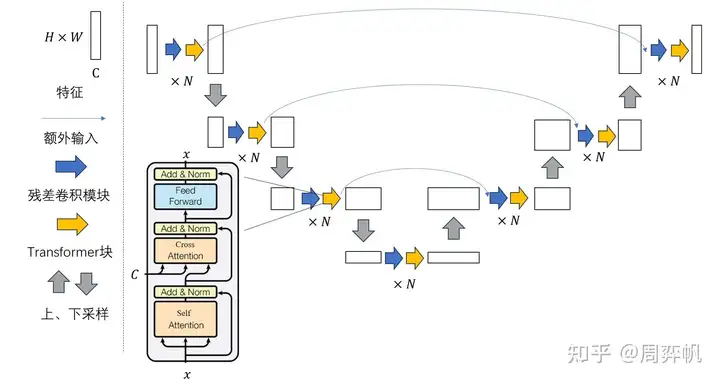
区别:(1)DDPM中是自注意力模块,而SD中替换成Transformer block。
(2) DDPM中自注意力仅在较深的几层,而SD中每个层都有Transformer block。
SD的训练过程
训练:首先预训练Autoencoder,然后训练LDM(LDM恢复的是latent)。
SD的生成结果评估指标
IS(Inception Score):用分类模型评测样本集的“类别确定性”和“类别多样性”,越大越好。用了一个图像分类网络来评估生成图片的质量。这个分类网络是在 ImageNet 数据集上训的,一共有1000类。
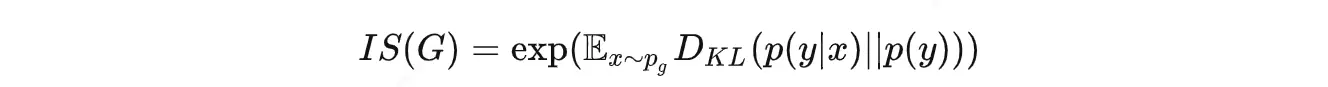
- 清晰度上:把一张生成的图像喂给分类模型,让模型输出最后一层的1000维向量,如果图像更清晰,那么分类的置信度会很高,其中的某个值会更接近1,其他值更接近0,这个1000维向量的熵就会更低。
- 多样性上:生成5000张图片给分类模型去分类,如果图像更多样,那么分出来的类型会更均匀,总体接近均匀分布,熵更高。
IS指标就是在计算这两个熵的KL散度(可以简单理解为一种距离),图像越清晰、多样性约高,前一个熵越低,后一个熵越高,KL散度越大,所以 IS 指标越大表示生成的效果越好。
缺点: 评测方式的前提是,图像生成所用的训练图片必须得是与分类模型训练数据相同,否则这种评测方式就是有问题的。
FID(Fréchet Inception Distance):用两个分布的期望和方差,计算两个分布的距离,越小越好。
- 用一个去掉分类头的分类模型推理出生成图像和真实图像的特征层(一般是2048维).
- 假设两个数据的特征层都服从正态分布
- 用上面这个公式计算两个分布的均值和协方差的“距离”
缺点:没法衡量是否过拟合的问题。
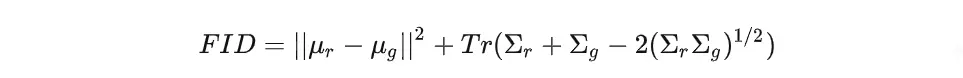
CLIP score:计算prompt与生成图片的cos相似度。用于评测遵守prompt的程度。
R-precision:对提取的图像和文本特征之间的检索结果进行排序,来衡量文本描述和生成的图像之间的视觉语义相似性。
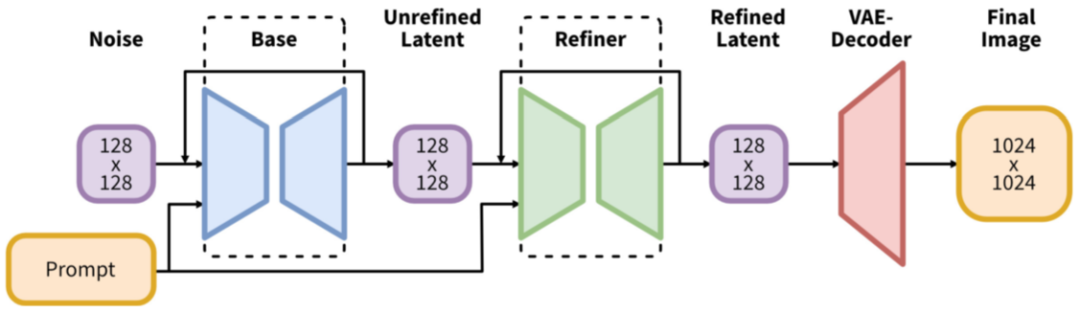
SD-XL
SD-XL与SD 1.x的区别
增加一个 Refiner 模型,用于对图像进一步地精细化
使用 CLIP ViT-L 和 OpenCLIP ViT-bigG 两个 text encoder
基于 OpenCLIP 的 text embedding 增加了一个 pooled text embedding
训练方式上:(1)以图像大小作为条件。提出将原始图像分辨率作用于 U-Net 模型,并提供图像的原始长和宽(csize = (h, w))作为附加条件。 (2) 以裁剪参数作为条件。将裁剪的左上坐标(top, left)作为条件输入模型,和 size 类似。(3)基于多尺度分辨率训练。
SD-XL-turbo的改进
引入蒸馏技术,以便减少 LDM 的生成步数,提升生成速度。