





正在更新中……
秋招在即,用这篇博客记录一下算法岗求职过程中的一些必备知识汇总。
GPT系列
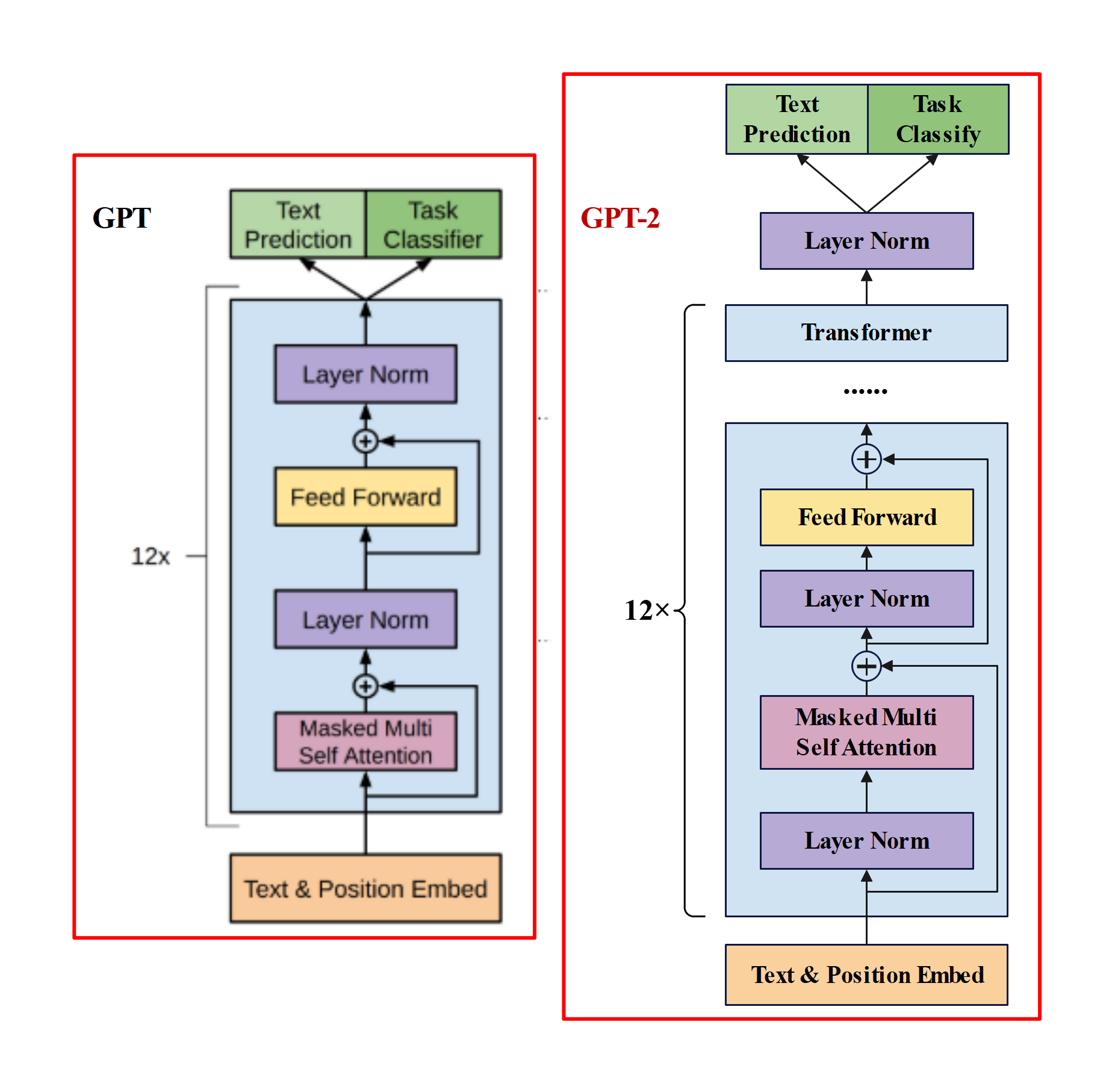
GPT-1
简述一下GPT的训练过程。
GPT的训练过程采用了预训练和微调的二段式训练策略。
- 非监督式预训练: 利用大规模无标记语料,构建预训练单向语言模型。训练目标是Language Modeling loss。
- 监督式微调: 用预训练的结果作为下游任务的初始化参数,增加一个线性层,匹配下游任务。训练目标是有监督的目标函数,并加上Language Modeling作为辅助目标。
GPT的Decoder与Transformer Decoder的区别
- 激活函数为GELU
- 位置编码为Learning Position embedding
- 去除了Cross attention。
- Tokenizer采用的是BPE。
为什么GPT是Decoder-only?
Transformer 结构提出是用于机器翻译任务,机器翻译是一个Seq2Seq的任务,因此 Transformer 设计了Encoder 用于提取源端语言的语义特征,而用 Decoder 提取目标端语言的语义特征,并生成相对应的译文。GPT目标是服务于单序列文本的生成式任务,所以舍弃了关于 Encoder部分以及包括 Decoder 的 Cross Attention 层。
GPT-2
- GPT-2与GPT的区别?
主推zero-shot,而GPT-1为pre-train+fine-tuning。
模型更大。参数量达到1.5B,而GPT只有0.117B.
数据集更大。
训练参数变化,batch_size 从 64 增加到 512,上文窗口大小从 512 增加到 1024。
模型结构变化:- 后置层归一化( post-norm )改为前置层归一化( pre-norm );
- 在模型最后一个自注意力层之后,额外增加一个层归一化;
- 调整参数的初始化方式,按残差层个数进行缩放,缩放比例为;
- 输入序列的最大长度从 512 扩充到 1024;
GPT-3
- GPT-3与GPT-2区别?
GPT-2虽然提出zero-shot,比bert有新意,但是有效性方面不佳。GPT-3考虑few-shot,用少量文本提升有效性。
模型结构:- 大部分和GPT-2一样,但应用了Sparse attention。
论文尝试了四种方式的评估方法: - fine-tuning:预训练 + 训练样本计算loss更新梯度,然后预测。会更新模型参数.
- zero-shot:预训练 + task description + prompt,直接预测。不更新模型参数.
- one-shot:预训练 + task description + example + prompt,预测。不更新模型参数.
- few-shot(又称为in-context learning):预训练 + task description + examples + prompt,预测。不更新模型参数.
- 大部分和GPT-2一样,但应用了Sparse attention。
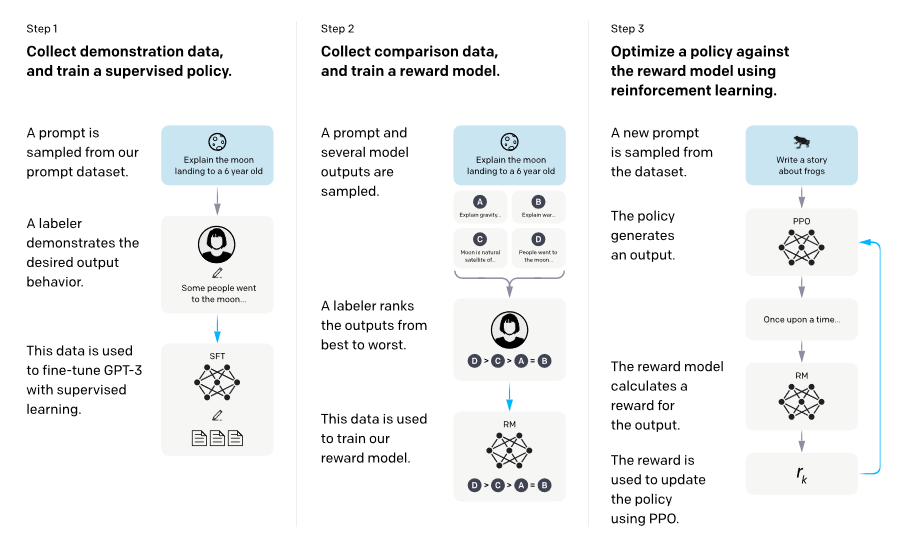
Instruct-GPT
- 介绍一下InstructGPT。为了和人类的需求对齐—— 主要由三个阶段组成 : (1) SFT(Supervised Fine-tuning):收集一系列人工标注的(Question,Response)作为数据集,使用LM目标函数监督学习微调GPT-3(16个epoch)。根据验证集上的RM分数,选择最终的SFT模型。 (2) RM(Reward Modeling):RM是训练一个Reward Model,将SFT模型最后的嵌入层去掉后的模型,它的输入是prompt和response,输出是标量的奖励值。奖励模型的损失函数如下,这里使用的是排序中常见的pairwise ranking loss。这是因为人工标注的是答案的顺序,而不是分数,所以中间需要转换一下。 (3) RL(PPO):训练RL policy,即之前SFT过的GPT-3。用SFT的GPT-3输出Response,用上一步训练的Reward Model输出标量作为Reward,来训练这个RL policy。为了确保输出的质量不降低,有时也会在PPO的目标函数之外额外加上加权的LM目标函数。
BERT系列
BERT
BERT模型结构
由多个Transformer Encoder堆叠。分为12层的BERT-base和24层的BERT-large。
最长序列:512个token,超过的需要截断。
Tokenizer: WordPiece。每个句子首个token都是[CLS],分隔符用[SEP]。会拆分Subword,例如playing拆分为play和###ing。
Embedding:见下图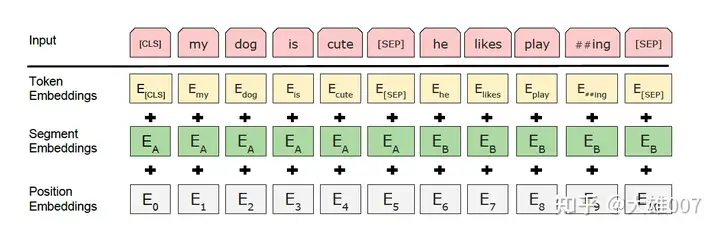
- Token Embedding:分词后转为词向量。
- Segement Embedding:用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务。(在句子对任务中,第一个句子为0,第二个为1;在文本分类中只有一个句子,则全部为0)
- Position Embedding:使用可学习的Position Embedding。
BERT预训练任务
由MLM和NSP两个自监督任务组成。
Masked Language Modeling(MLM):在BERT的实验中,15%的WordPiece Token会被随机Mask掉。在训练模型时,一个句子会被多次喂到模型中用于参数学习,但是Google并没有在每次都mask掉这些单词,而是在确定要Mask掉的单词之后,做以下处理:(1)80%的时候会直接替换为[Mask],将句子 “my dog is cute” 转换为句子 “my dog is [Mask]”。(2)10%的时候将其替换为其它任意单词,将单词 “cute” 替换成另一个随机词,例如 “apple”。将句子 “my dog is cute” 转换为句子 “my dog is apple”。(3)10%的时候会保留原始Token,例如保持句子为 “my dog is cute” 不变。
*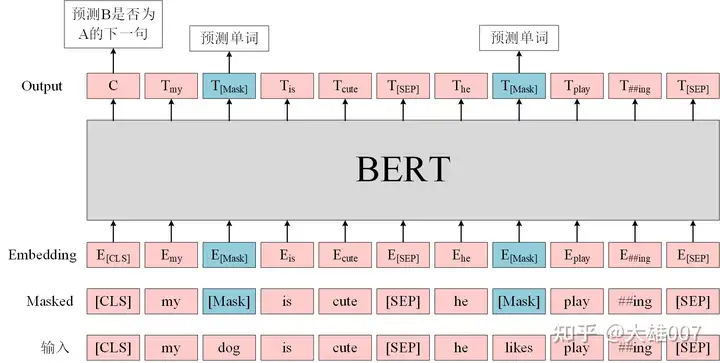
Next Sentence Prediction(NSP):判断句子B是否是句子A的下文。如果是的话输出’IsNext‘,否则输出’NotNext‘。训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的。
[CLS]的作用
BERT在第一句前会加一个[CLS]标志,最后一层该位对应向量可以作为整句话的语义表示,从而用于下游的分类任务等。因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。
BERT的优缺点
优点:(1)BERT 相较于原来的 RNN、LSTM 可以做到并发执行,同时提取词在句子中的关系特征,并且能在多个不同层次提取关系特征,进而更全面反映句子语义。(2)相较于 word2vec,其又能根据句子上下文获取词义,从而避免歧义出现。
缺点:(1)模型参数太多,而且模型太大,少量数据训练时,容易过拟合。(2)BERT的NSP任务效果不明显,MLM存在和下游任务mismathch的情况。(3)BERT对生成式任务和长序列建模支持不好。
BERT和GPT区别
- 训练目标不同:BERT是MLM和NSP;GPT是自回归的LM。
- 模型结构不同:BERT是Transformer Encoder,双向注意力;GPT是Decoder,单向注意力。
- 应用场景不同:BERT由于其双向上下文理解能力,BERT在需要理解整个输入序列的任务中表现更好,如问答系统、命名实体识别(NER)和句子对分类;由于其生成能力,GPT在文本生成任务中表现更好,如文本续写、对话系统和文本摘要。
- 使用方式:BERT通常是pretrain+finetune;;GPT通常是pretrain+prompting。
BERT-wwm
- BERT-wwm与BERT的区别
BERT在MLM过程中,可能只会mask掉某个Subword;BERT-wwm则是如果Subword被选中mask,那么整个单词都会进行mask。因此是全词掩码(Whole Word Mask)。
RoBERTa
- RoBERTa与BERT的区别
- 更多的预训练语料。
- 更大的batchsize。
- 更长的训练步数。
- 剔除NSP任务。
- 动态mask:BERT中,对于每一个样本序列进行mask之后,mask的tokens都固定下来了,即是静态mask的方式;而RoBERTa使用了动态mask的方式:对于每一个输入样本序列,都会复制10条,然后复制的每一个都会重新进行mask,即拥有不同的masked tokens。
LLAMA系列
LLAMA
LLaMa介绍
预训练数据:全是开源数据。
Tokenizer: BPE implemented by SentecePiece,分词后训练集中共包含1.4T tokens。
模型架构:相比与原始Transformer架构,有如下改动- Pre-norm:参考GPT3,在transformer sub-layer前进行norm。使用的是RMSNorm。
- SwiGLU: 参考PaLM,使用SwiGLU作为激活函数。
- RoPE: 将PE换成了RoPE。
- 在casual MHA这里使用了更efficient的实现方式。
- 保存线性层输出的activation。
Optimizer: AdamW,同时用CosLR schedule。同时有0.1的weight decay和1.0的grad clip。有2000 steps的warm up。
在2048台A100-80GB上训练了21天。
LLAMA中的RMSNorm
RMSNorm(Root Mean Square Layer Normalization)
提出动机:LayerNorm计算量比较大。
优点:(1)计算效率高。不需要同时计算均值和方差两个统计量,而只需要计算均方根这一个统计量(没有去中心化操作)。同时也减少了Norm中的参数量(只有lambda一个参数)。 (2)稳定性好。能缓解梯度消失和梯度爆炸。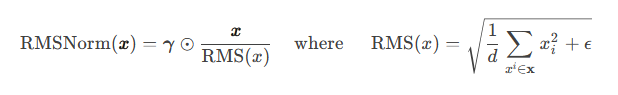
1 | class LlamaRMSNorm(nn.Module): |
- LLAMA的loss函数
Language Modeling,即自回归预测next word的概率,实现方式为Cross Entropy。
也会有其他的预训练损失函数。
LLAMA2
- LLAMA2的改进* 预训练语料扩充到2T token。 * 上下文长度从2048翻倍到4096. * 引入了Grouped-query attention、KV cache等技术 * 在LLAMA2基础上进一步SFT(Supervised Fine-tuning)和RLHF,得到LLAMA2-Chat。
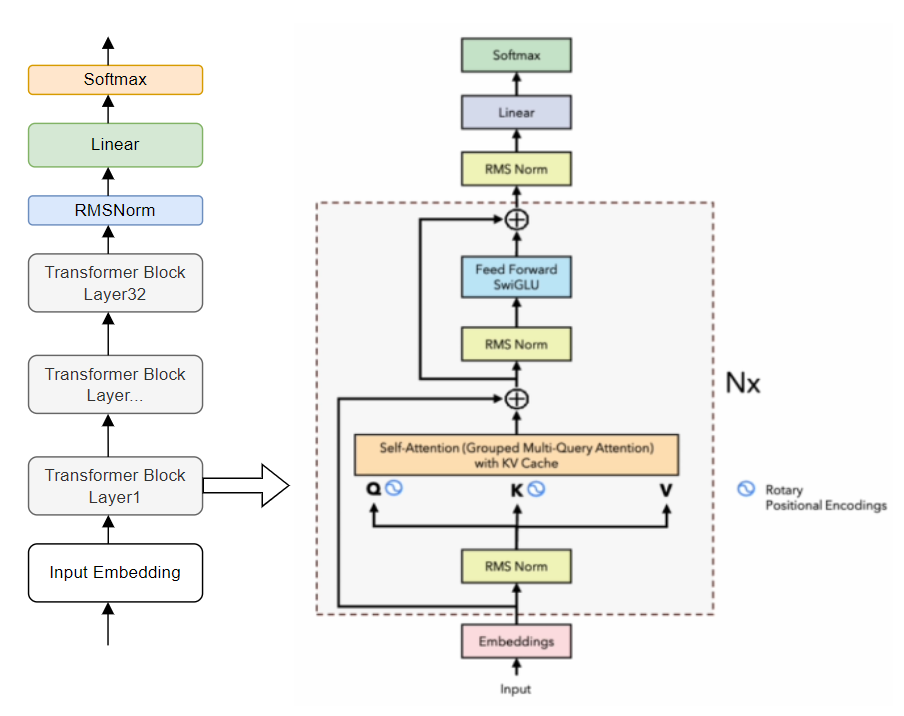
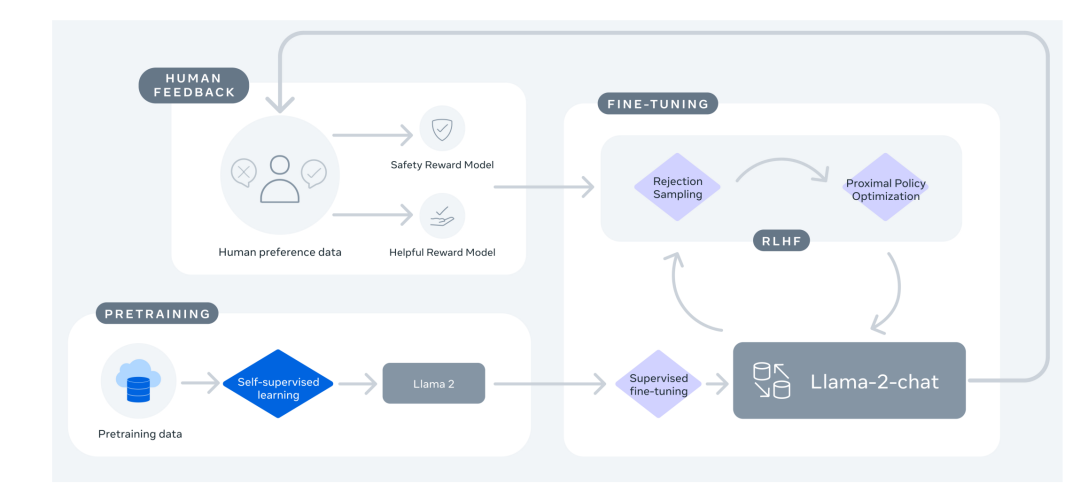
LLAMA3
- LLAMA3的改进
- 训练数据集比LLAMA2大7倍。
- 采用了数据并行、模型并行、管道并行等并行化技术。
- 结合了SFT,Rejection sampling、PPO、DPO对预训练模型进行指令微调。
Vicuna
Vicuna是在LLaMa-13B的基础上使用监督数据微调得到的模型,数据集来自于ShareGPT.com 产生的用户对话数据,共70K条。
Vicuna在训练中将序列长度由512扩展到了2048,并且通过梯度检测和flash attention来解决内存问题;调整训练损失考虑多轮对话,并仅根据模型的输出进行微调。
Qwen系列
Qwen
Qwen的技术要点
- 数据:公共网络文档,百科全书,书籍,代码等。此外,数据集是多语言的,其中很大一部分数据是英语和中文的。最终数据集多达3万亿token。
- Tokenizer:采用开源的BPE,并以vocabulary C1100K base作为起始点,增加了常用的中文字符和单词以及其他语言的词汇。此外,仿照LLAMA2,将数字分为单个数字,最终词汇量大约是152K.
- 模型结构:
(1) Embedding和Output project:解耦嵌入。
(2) Positional embedding: RoPE,使用FP32的逆频率矩阵。
(3) Bias,除了Attention中的QKV,其他层的bias都去除,以增强外推能力,并防止过拟合。
(4) Pre-Norm & RMSNorm
(5) Activation:选用SwiGLU。 - 对于文本长度的拓展,使用了Dynamic NTK-aware interpolation,可以在无需训练的方法下调整尺度以防止高频信息的丢失,有效地扩展Transformer模型的上下文长度。
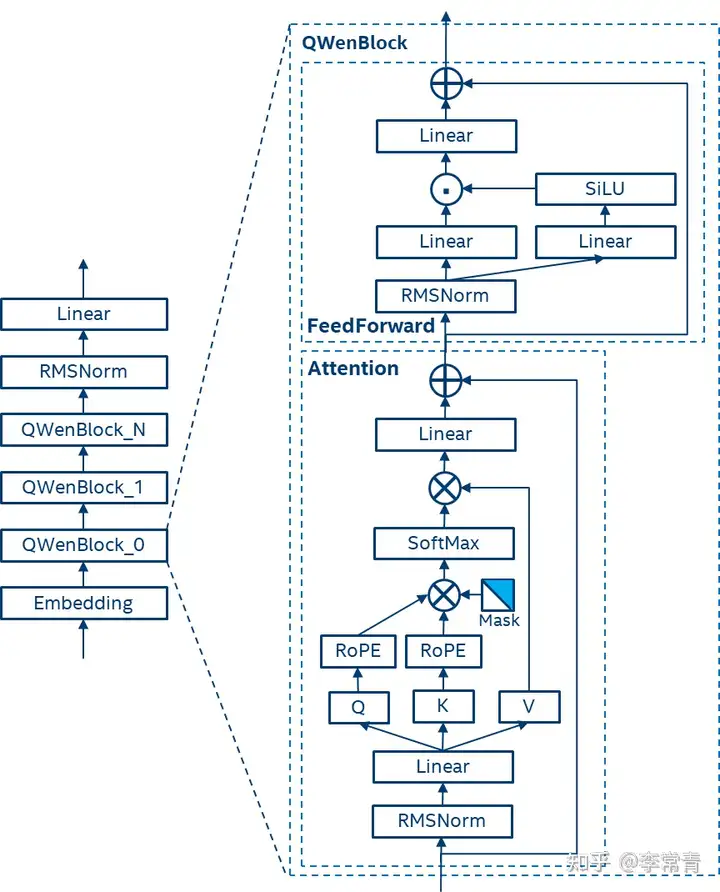
Qwen的预训练
- 采用标准的自回归语言模型训练目标
- 训练时上下文长度为2048
- 注意力模块采用Flash Attention技术,以提高计算效率并减少内存使用
- 采用AdamW优化器,设置β1=0.9,β2=0.95,,=1e-8
- 使用余弦学习率计划,为每种模型设定一个峰值学习率,学习率会衰减到峰值的10%
- 使用BFloat16混合精度加速训练
Qwen的对齐
SFT:采用ChatML格式的数据进行模型训练。
RM:偏好模型预训练和微调
PPO:使用RM进行RLHF。
Qwen-2
- Qwen2相对于Qwen的改进
- 多种模型规模
- 多语言支持:在训练数据中增加了27种语言的高质量数据,增强了模型的多语言能力。
- 代码和数学能力
- 长文本处理:Qwen2模型能够处理更长的上下文,最高可达128K tokens。
- 架构创新:引入了Group Query Attention。
Parameter-efficition finetuning(PEFT)
LoRA
LoRA原理
LoRA假设微调变化矩阵的内在秩远低于原矩阵维度d,因此将变化矩阵分解为B和A,而原矩阵的权重不发生变化。这样使得可训练参数数量极大减少,降低显存消耗量。见下图:
初始时将A矩阵高斯随机初始化,将B矩阵初始化为0,这样变化矩阵在开始训练时是0。还需要将进行scale: ,其中分子为r中的一个常数,r为选取的秩。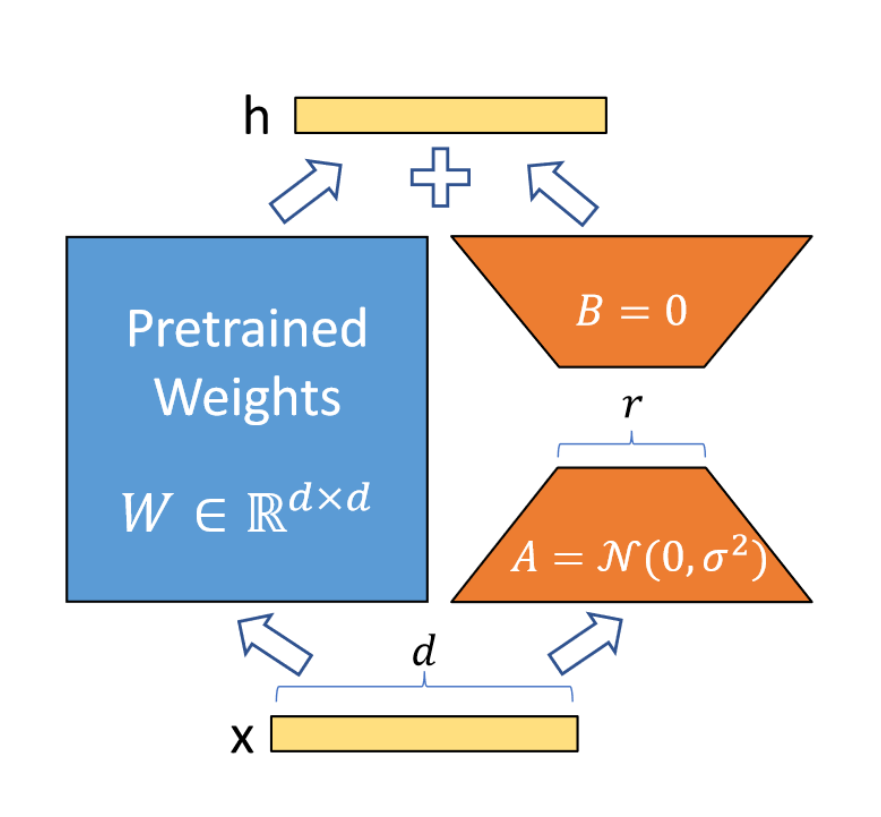
LoRA推理过程中有额外计算吗?
LoRA在推理时通常会将变化矩阵加在原矩阵上,这样并没有额外的计算开销,因此没有额外计算。
Lora初始化方式
A矩阵进行高斯分布初始化,B矩阵初始化为0.
LoRA应用于网络的哪些部分?
在Transformer中,可以应用于Attention中的Q,K,V矩阵和线性层,以及FFN中的两个MLP模块。能够大大降低微调参数量。通常用在Attention的q和v效果最好。
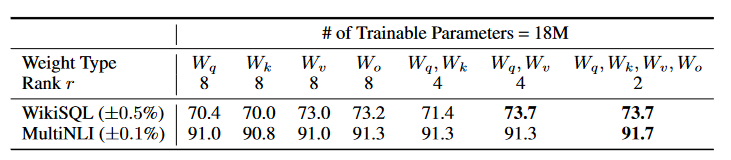
LoRA的r一般选取多少?
对于一般的任务,r=1,2,4,8 就足够了。而一些领域差距比较大的任务可能需要更大的r 。
LoRA的几种变种(QLoRA等)
Adapter tuning
Adapter tuning原理
在模型内部外置一些轻量级的层,通过训练这些层来适应新的数据变化。下图中为Bottleneck adapter。
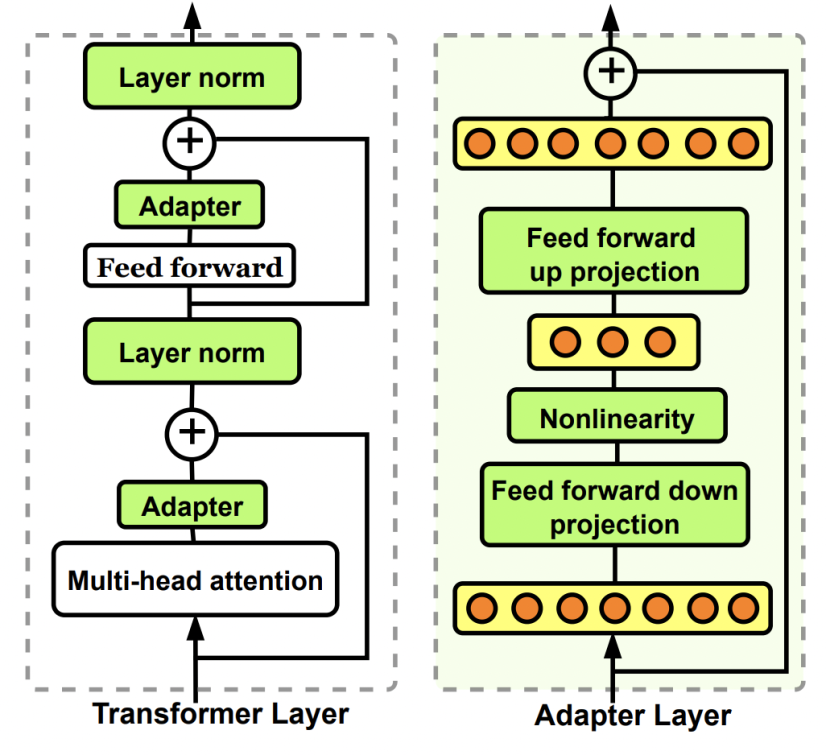
与LoRA的区别
Adapter会有新的模型层和参数;LoRA训练得到的部分最后会合并回原模型。
Prefix tuning
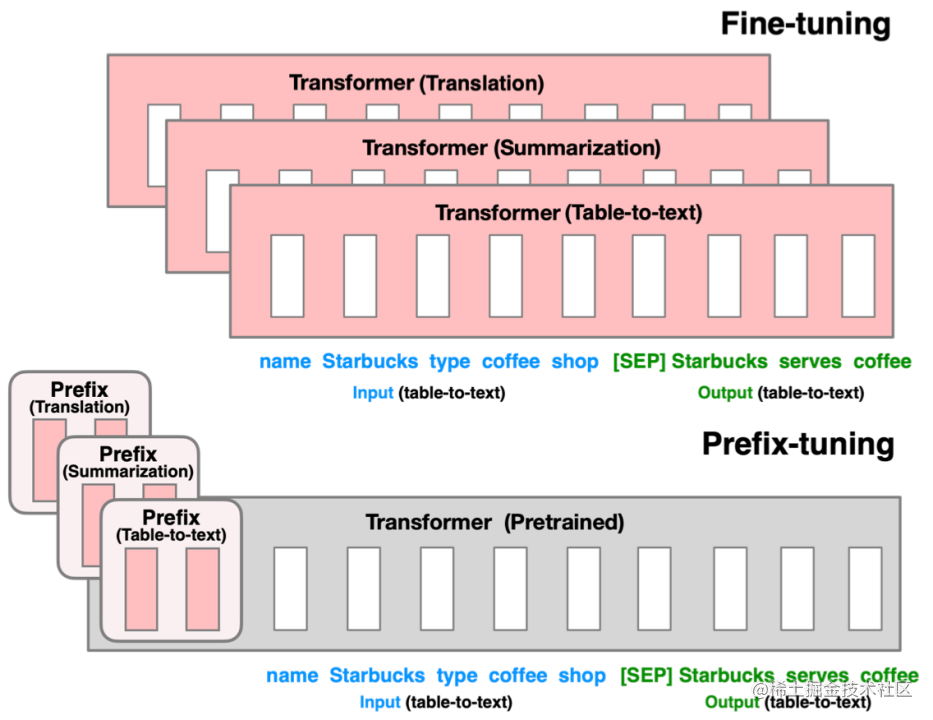
- Prefix tuning原理
主要适配NLG任务。
与Full-finetuning更新所有参数的方式不同,该方法是在输入token之前构造一段任务相关的virtual tokens作为Prefix,然后训练的时候只更新Prefix部分的参数,而Transformer中的其他部分参数固定。(该方法其实和构造Prompt类似,只是Prompt是人为构造的“显式”的提示,并且无法更新参数,而Prefix则是可以学习的“隐式”的提示。)同时,为了防止直接更新Prefix的参数导致训练不稳定的情况,他们在Prefix层前面加了MLP结构(相当于将Prefix分解为更小维度的Input与MLP的组合后输出的结果),训练完成后,只保留Prefix的参数。在每个Transformer layer前都会有prefix。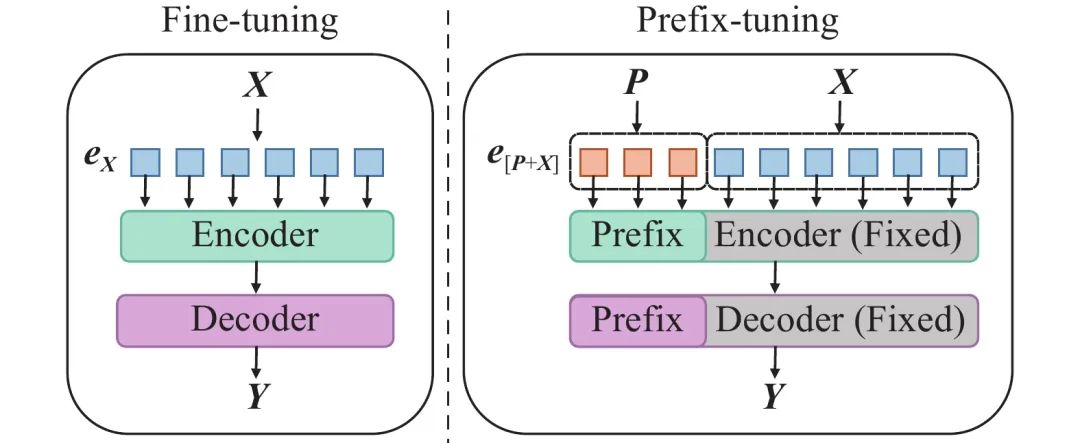
 主要适配NLG任务。
主要适配NLG任务。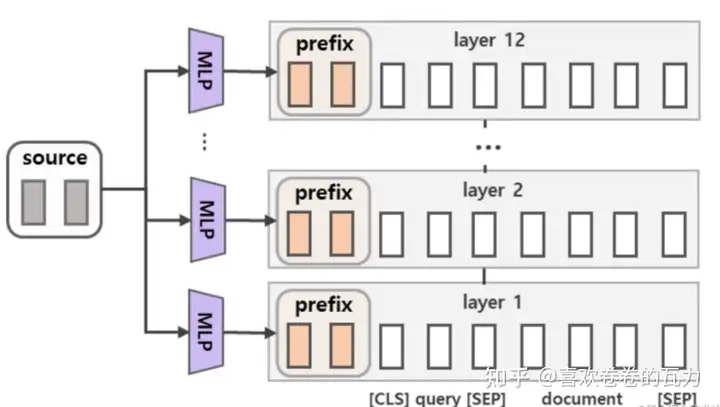
Prompt tuning
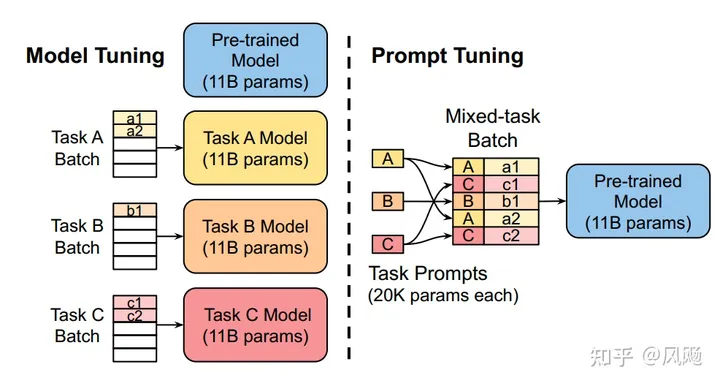
- Prompt tuning原理
该方法可以看作是 Prefix Tuning 的简化版本,它给每个任务定义了自己的Prompt,然后拼接到数据上作为输入,但只在输入层加入prompt tokens,并且不需要加入 MLP 进行调整来解决难训练的问题。 它在预训练语言模型的输入中添加可学习的嵌入向量作为提示。这些提示被设计成在训练过程中更新,以引导模型输出对特定任务更有用的响应。同时,Prompt Tuning 还提出了 Prompt Ensembling,也就是在一个批次(Batch)里同时训练同一个任务的不同 prompt(即采用多种不同方式询问同一个问题),这样相当于训练了不同模型。
P-tuning
P-tuning V1原理
目的:使GPT适配NLU任务;避免人工设计prompt。
做法:该方法将Prompt转换为可以学习的Embedding层,并用MLP+LSTM的方式来对Prompt Embedding进行一层处理。相比Prefix Tuning,P-Tuning加入的可微的virtual token,但仅限于输入层,没有在每一层都加;另外,virtual token的位置也不一定是前缀,插入的位置是可选的。这里的出发点实际是把传统人工设计模版中的真实token替换成可微的virtual token。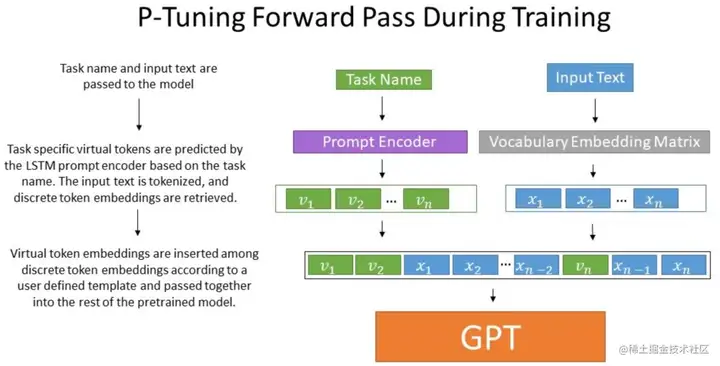
P-tuning V2原理
方法:该方法在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层,这带来两个方面的好处:(1)更多可学习的参数(从P-tuning和Prompt Tuning的0.01%增加到0.1%-3%),同时也足够参数高效。(2)加入到更深层结构中的Prompt能给模型预测带来更直接的影响(如Prefix tuning).具体做法基本同Prefix Tuning,可以看作是将文本生成的Prefix Tuning技术适配到NLU任务中.
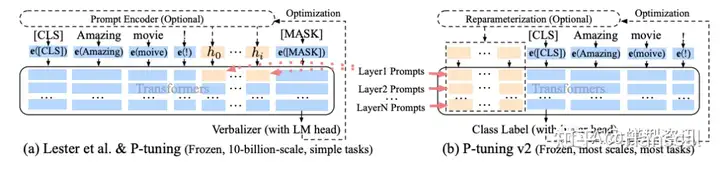
P-tuning V1/V2的区别。
参见上图。可以简单的将 P-Tuning 认为是针对 Prompt Tuning 的改进, P-Tuning v2 认为是针对 Prefix Tuning 的改进。
Attention优化
Scaled dot-product attention的时间和空间复杂度都是O(n^2)的,当n较大时,会是很大的占用。
Sparse attention
将空洞注意力与局部注意力相结合,使得既可以学到局部的特性,又可以学到远程稀疏的相关性。使得大部分元素为0,时间与空间复杂度下降为O(kn)。但是其是对标准attention的近似。
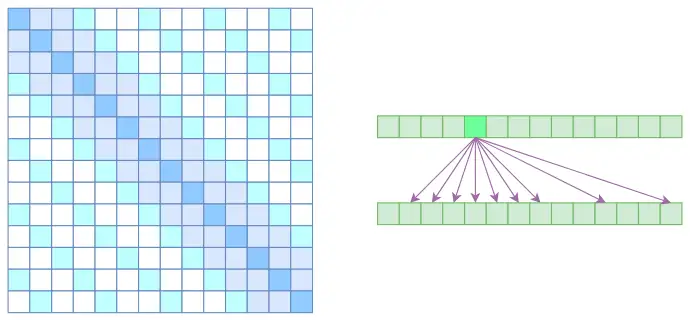
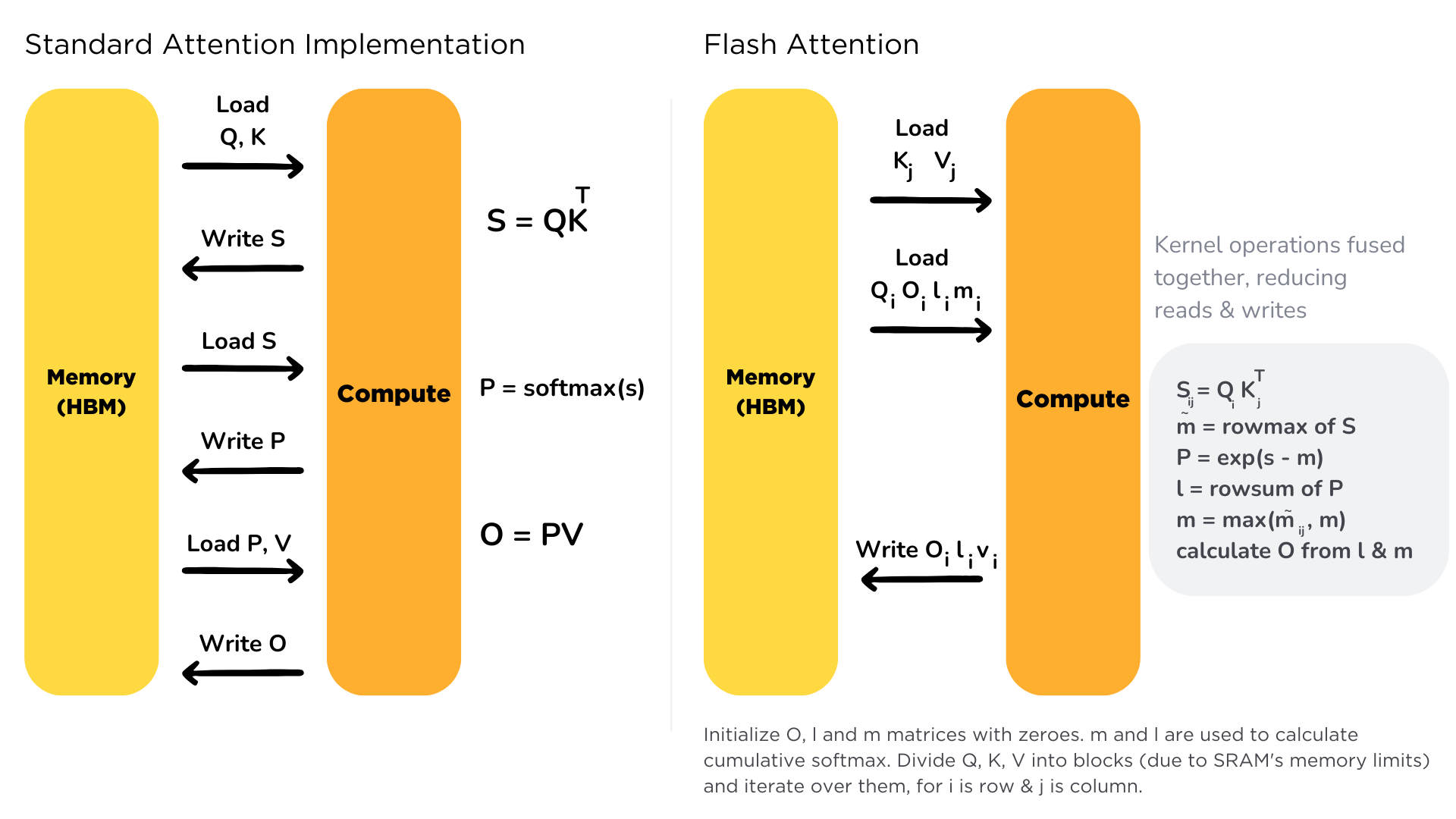
Flash attention
Flash Attention v1原理
原理:减小MAC。
大部分的Efficient transformer的目标都是减少FLOPs。Flash Attention的目标是降低MAC(Memory Access cost),代价是增加了FLOPs. Flash attention是一种精准的优化策略,没有近似损失。
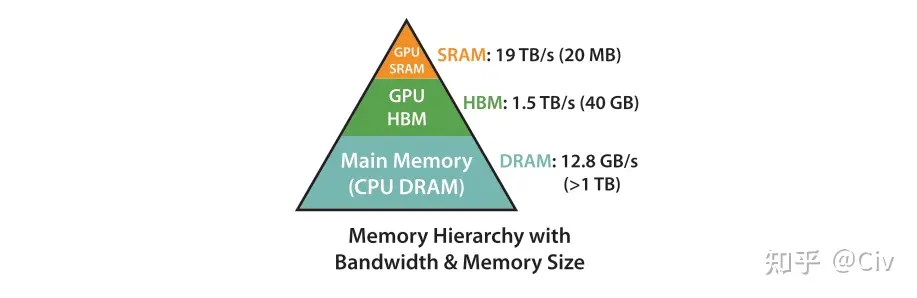
GPU的存储由SRAM和HBM组成。SRAM的读写速度远大于HBM,但其存储空间远小于HBM。
为了减少对HBM的读写,Flash attention将参与计算的矩阵进行分块送进SRAM,来提高整体读写速度。对于Flash attention来说,矩阵分块计算不是难事,重要的是Softmax值的计算——这里采用的是增量计算,具体请参考知乎文章及下列伪代码:
Flash Attention v1与Transformer的MAC分析。
标准Transformer的MAC次数:
第一行,读Q,K的MAC次数位2Nd,写S的MAC次数为N^2。
第二行,读S的MAC次数为N^2,写P的MAC次数为N^2。
第三行,读P的MAC次数为N^2,读V的MAC次数为Nd,写O的MAC次数为Nd。
上述总MAC开销为4Nd+4N^2,复杂度为O(Nd+N^2)。
Flash attention v1的MAC开销:
上述伪代码中,一次完整的内循环需要读取完整的Q,MAC开销为Nd。
外循环的次数为T_c次,即T_c = 4dN/M,可知开销为O(N^2 * d^2 * M^-1)。因为M(100KB)通常远远大于d(几K),所以Flash attention的MAC远小于标准attention。
Flash attention能够将标准的self-attention的计算速度提升2至4倍。
KV cache
KV cache的适用范围。
适用于Decoder-only的LLM的推理过程(每一个token的输出只依赖于它自己以及之前的输出);并且每次新添加token作为输入后,原token的输入输出不会变。(一旦输入预处理层不满足KVCache的条件,后续transformer层的输入(即预处理层的输出)就发生了改变,也将不再适用于KVCache。)
KV cache的工作原理。
思想:以空间换时间,减少重复计算。将FLOPs从O(n2)降低到O(n)。
Decoder-only的attention,每次附加上新的token后,下一个token的生成只依赖于当前token的query以及所有token的key和value。因此在推理的自回归过程中,我们只需要计算当前token的qkv,然后将它的kv与之前的kv进行concat后计算attention score即可,其他部分是不变的。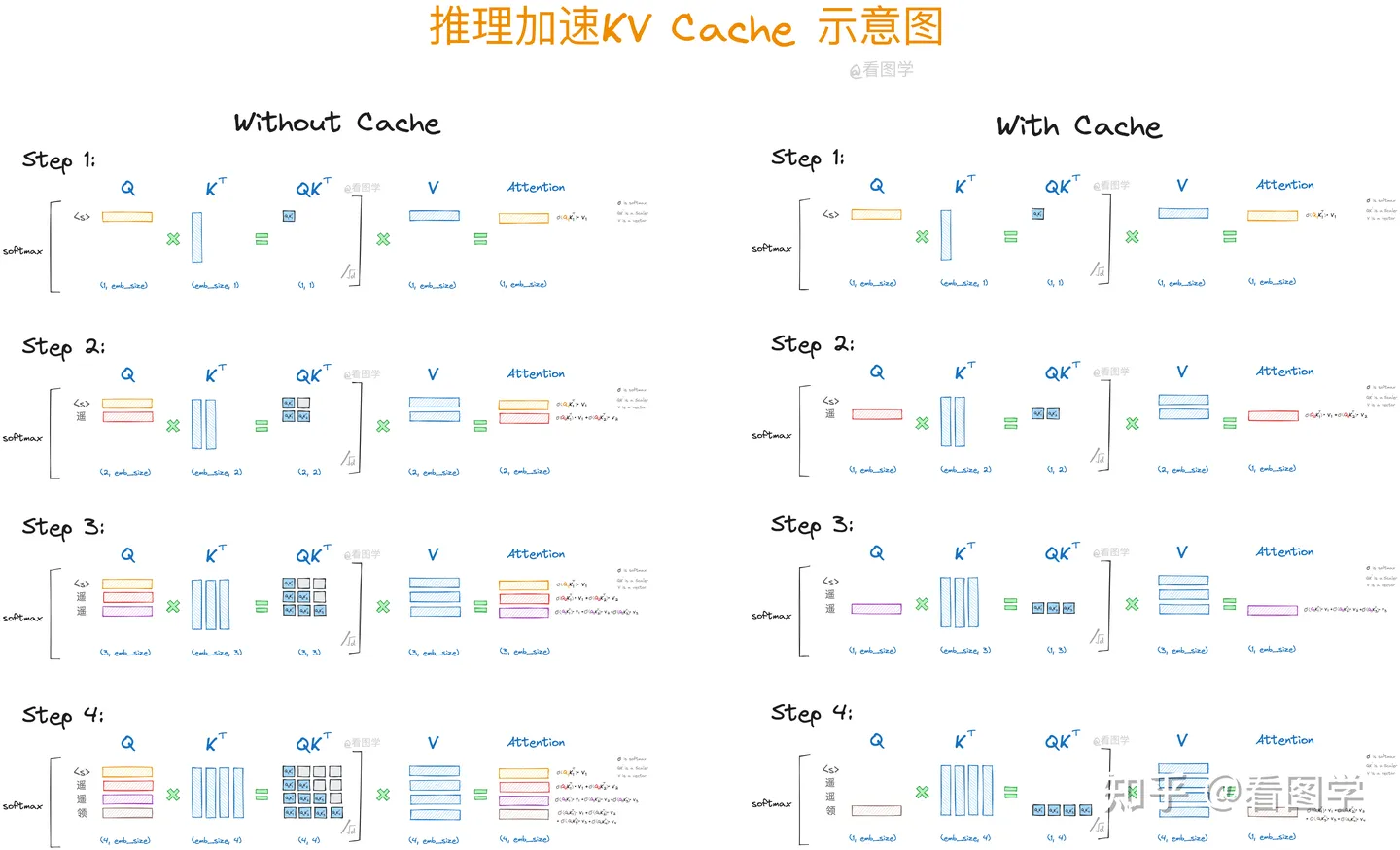
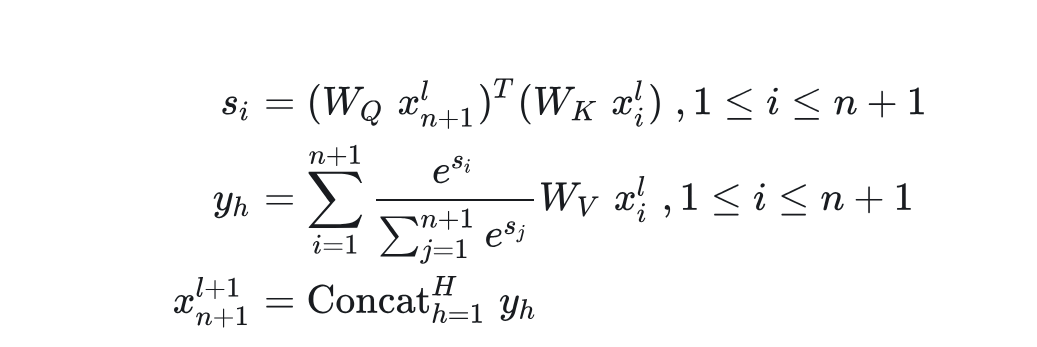
KV cache占用内存大小
假设Transformer有n_layers层,每个多头注意力层有n_heads个头,维度为d_head,需要为K和V都缓存一份;最大上下文长度为n_context,精度为n_bytes,推理的批量为batch_size。
则KV cache需要的内存大小为2 * n_layers * n_heads * d_head *n_context * n_bytes * batch_size。
为什么是KV cache而不是Q cache?
因为下一个token只取决于最新token的Q和所有token的KV(因果性),每一次用的Q都是最新的。
Multi Query Attention(MQA)与Group Query Attention(GQA)
MQA的动机及原理
动机:KV cache中对于多头,每个头都会有一个K,V矩阵。因此KV cache较大。
原理:MQA让所有头之间共享同一份K和V矩阵,从而大大减少KV参数量和cache量。这样在decoder上推理时,可以大大减少KV cache大小。能提高 30%-40% 的吞吐。
GQA的原理
将query分为N组,每个组共享一个K和V矩阵。
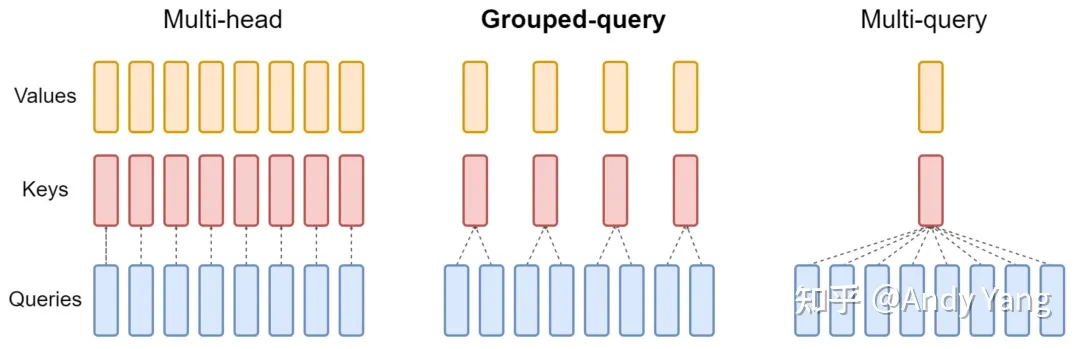
MQA和GQA的共同原理
降低了从内存中读取的数据量,所以也就减少了计算单元等待时间,提高了计算利用率;
KV cache 变小了 head_num 倍,也就是显存中需要保存的 tensor 变小了,空出来空间就可以加大 batch size,从而又能提高利用率。
RAG
- RAG流程
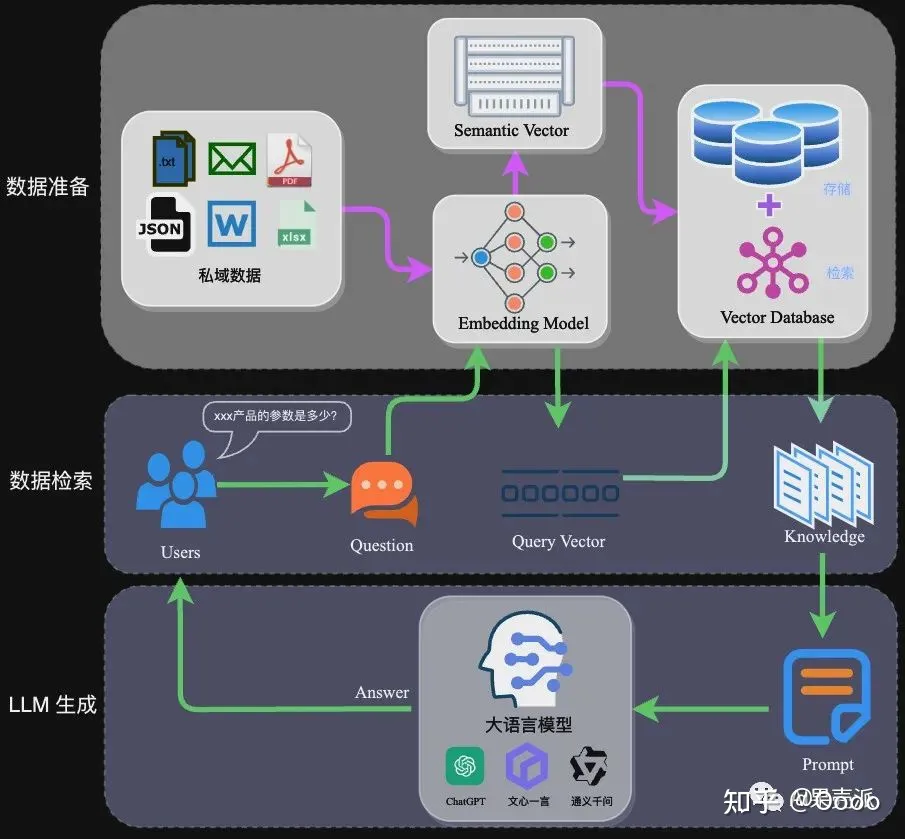
其他
FP32,FP16,BF16
FP32:1位符号,8位指数,23位尾数。
FP16:1位符号,5位指数,10位尾数。
BF16:1位符号,8位指数,7位尾数。BF16提供了与FP32相同的动态范围,但精度低于FP32和FP16。如何计算训练大模型需要的显存?
- 模型参数:如果模型有P个参数,使用FP32保存的话,需要4P字节的显存。
- 梯度:大小与模型参数相同。使用FP32保存的话,需要4P字节的显存。
- 优化器状态:Adam需要保存参数的一阶和二阶矩估计。因此显存翻倍,使用FP32保存的话,需要4P*2=8P字节的显存。
- 激活和中间变量:前向传播和反向传播过程中的激活值和中间变量也需要存储,这与批量大小(batch size)和序列长度有关。这些是动态的显存。
Encoder-only,Decoder-only,Encoder-Decoder的几种模型
Encoder-only:BERT,RoBERTa。通常用于需要理解输入数据但不生成输出的任务,如文本分类、问答系统和命名实体识别。
Decoder-only:GPT,OPT,LlAMA。通常用于文本生成任务,如语言建模、文本摘要和对话系统。
Encoder-Decoder:Transformer,T5,Flan-T5。适用于需要将输入序列转换为输出序列的任务,如机器翻译、文本摘要和问答系统。Tokenizer的种类和区别
PPO,DPO及其他强化学习算法
混合精度训练