





正在更新中……
秋招在即,用这篇博客记录一下算法岗求职过程中的一些必备知识汇总。
CLIP
CLIP模型结构
Image Encoder有两种架构:一种是ResNet50,将全局平均池化替换为注意力池化;第二种是ViT(Pre-norm)。
Text Encoder实际上是GPT-2架构,即Transformer decoder,将文本用[SOS]和[EOS]括起来,取[EOS]上的feature过一层Linear作为文本特征。CLIP训练时的损失函数
InfoNCE,一种用于自监督学习的特征表示学习损失函数。
公式:,N是样本的数量,q是查询样本的编码,k是与查询样本对应的正样本或负样本的编码。
目的:最大化正样本对相似度,最小化负样本对相似度。CLIP训练的伪代码

CLIP训练代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27image_embeds = vision_outputs[1]
image_embeds = self.visual_projection(image_embeds)
text_embeds = text_outputs[1]
text_embeds = self.text_projection(text_embeds)
# normalized features
image_embeds = image_embeds / image_embeds.norm(p=2, dim=-1, keepdim=True)
text_embeds = text_embeds / text_embeds.norm(p=2, dim=-1, keepdim=True)
# cosine similarity as logits
logit_scale = self.logit_scale.exp()
logits_per_text = torch.matmul(text_embeds, image_embeds.t()) * logit_scale
logits_per_image = logits_per_text.t()
loss = None
if return_loss:
loss = clip_loss(logits_per_text)
def contrastive_loss(logits: torch.Tensor) -> torch.Tensor:
return nn.functional.cross_entropy(logits, torch.arange(len(logits), device=logits.device))
def clip_loss(similarity: torch.Tensor) -> torch.Tensor:
caption_loss = contrastive_loss(similarity)
image_loss = contrastive_loss(similarity.t())
return (caption_loss + image_loss) / 2.0CLIP损失函数中温度系数的作用
温度系数的作用是调节对困难样本的关注程度:越小的温度系数越关注于将本样本和最相似的其他样本分开
如果温度系数设的越大,logits分布变得越平滑,那么对比损失会对所有的负样本一视同仁,导致模型学习没有轻重。
如果温度系数设的过小,则模型会越关注特别困难的负样本,但其实那些负样本很可能是潜在的正样本,这样会导致模型很难收敛或者泛化能力差。CLIP的位置编码,如何外推?
CLIP的text encoder是GPT,因此使用的Learable Positional Encoding,是绝对位置编码。理论上不能外推,但也许可以将超过长度的部分随机初始化然后微调。
CLIP少样本微调
Linear Probe
Encoder的embedding后接分类头,进行微调。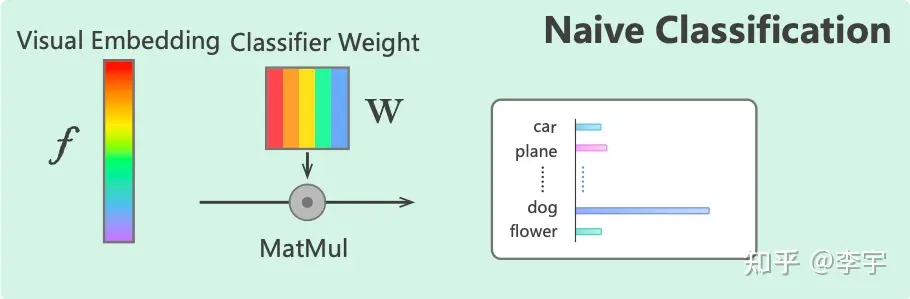
Context Optimization
针对CLIP中直接使用"A photo of"作为prompt可能不是最优的,CoOp提出使用可学习的token embedding,让模型自己调优prompt(可使用前人总结的prompt做初始化)。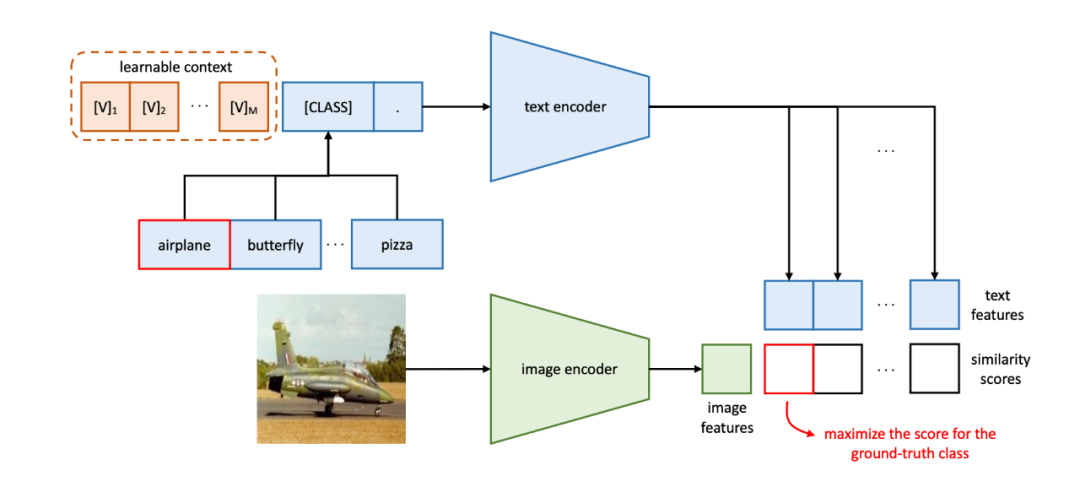
CLIP-Adapter
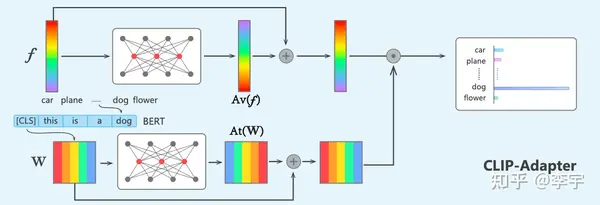
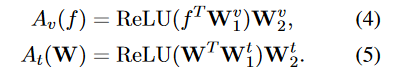 相较于CoOp,CLIP-Adapter的训练方式更加轻量化,只有两个残差连接的MLP。将两部分按照一定比例进行blend。(为什么要用残差连接?为了保留CLIP的原始能力)(为什么不全参微调?容易Over-fit。)
相较于CoOp,CLIP-Adapter的训练方式更加轻量化,只有两个残差连接的MLP。将两部分按照一定比例进行blend。(为什么要用残差连接?为了保留CLIP的原始能力)(为什么不全参微调?容易Over-fit。)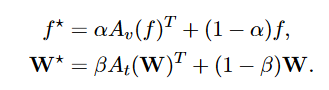
Flamingo
Flamingo的贡献
- 桥接预训练好的视觉模型和语言模型
- 可以处理任意交错的图文对数据
- 可以同时以图像和视频数据作为输入
Flamingo实现了多模态领域的Few-shot learning(in-context learning)能力,即多模态领域的GPT-3。
Flamingo模型结构
通过Perceiver Resampler和Gated Xatten-dense,与新插入到LM中的层计算Cross-attention,从而将视觉信息注入的LM的生成过程中。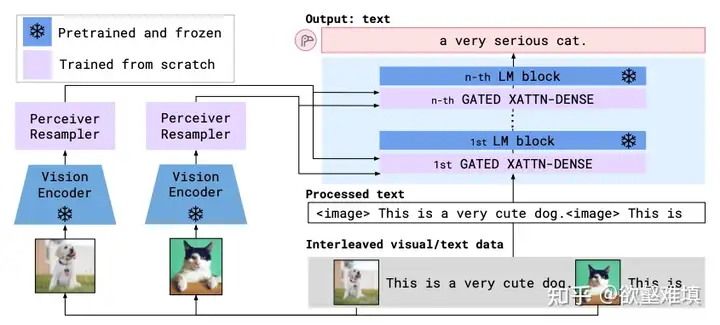
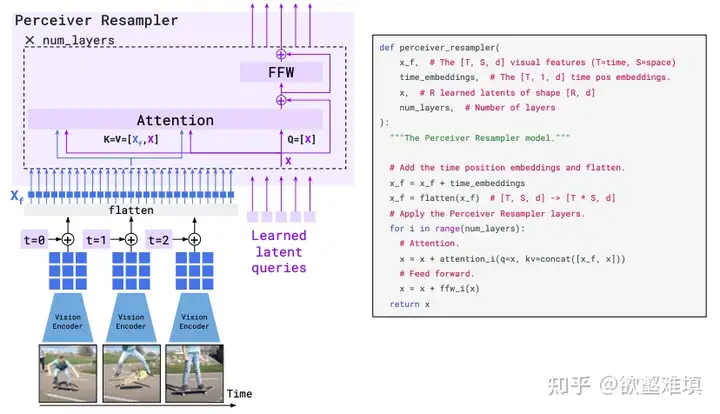
Perceiver Resampler:
1. 可以接收任意多个的视频帧(如果是图像,可以视作是单帧视频),经过视觉编码器提取特征,加上time embedding 之后全部展平,得到一个视觉 token 序列. 2. 同时有一个可学习的固定长度的latent query序列。 3. 计算CA时,Q是learnable query,KV是query和image feature拼接起来的。(这里和Q-former区别,Q-former是Q是query,KV是视觉feature) 4. 通过该模块,将视觉特征转成了少量低维度的query embedding。
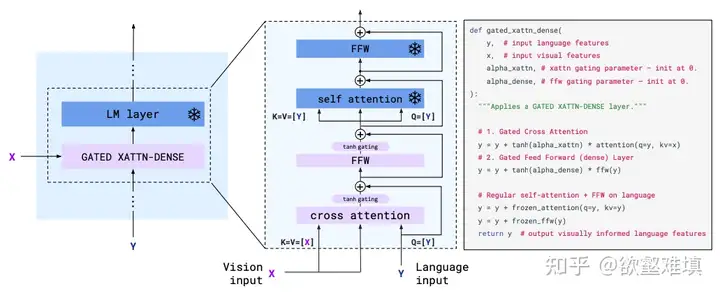
Gated Xattn Dense
将固定长度的视觉 query 注入到语言模型。在预训练好的 LM 的各层交替地插入一些随机初始化的CA。Gated门控,指的是在每一新插入的层之后的残差链接之前添加一个 tanh gating,即tanh(a),其中a是一个可学习的标量值,初始值为 0,从而保证初始化时的输出与原 LM 一致。
BLIP系列
BLIP
BLIP的主要贡献
- 提出了一种Multimodal mixture of Encoder-Decoder(MED)的多模态预训练模式。
- 提出了一种Captioning and Filtering的Dataset Bootstrapping机制,对原始数据集进行清洗。
- 微调后在下游Image-text retrieval、Image captioning、VQA等任务上达到了SOTA。
BLIP的模型架构
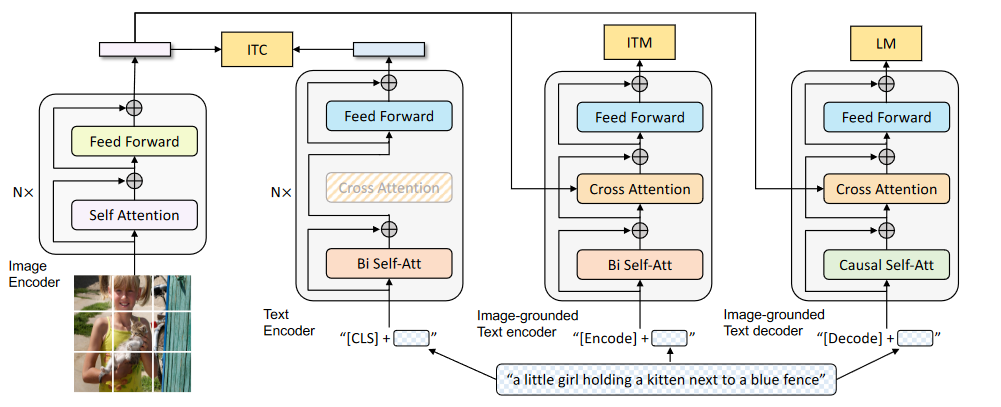
Unimodal Vision Encoder:采用的是在ImageNet-1k预训练的ViT(与LLaVa使用的不同)。
Unimodal Text Encoder:采用的是Bert-base,取[CLS] token的特征作为文本特征。
Image-grounded Text Encoder:采用Bert,在SA和FFN中间加上Cross Attention层,和图像特征交融。对于文本的输入,会在开头加上task-specific的[Encode]。
Image-grounded Text Decoder:将Image-grounded Text Encoder中的Bi Self-Att改为Causal Self-Att,同时也会和图像特征通过CA交融。会在开头加上[Decoder]表示序列起点,以及[EOS]表示序列终点。
后两部分除了Self-Att层不共享,其余部分参数共享。
BLIP的预训练目标
- Image-Text Contrastive Loss:将文本和图像在特征空间对齐,使用的是InfoNCE。实现方式上采用了ALBEF中的Momentum encoder。
- Image-Text Matching Loss:学习文本和图像之间的细粒度匹配,使用的是BCE loss。实现方式上采用了ALBEF中的Hard negative mining策略,即对于一个batch中用于更高对比相似度的负样本,更容易被选择来计算loss。
- Language-modeling loss:以自回归的方式进行极大似然估计,使用的是CE loss。计算时候使用了0.1的label smoothing。
BLIP的CapFilt机制
为了对含有噪声的Alt-text对进行过滤清洗,人工标注部分数据集得到高质量文本-图像对,然后分别微调得到一个Filter和一个Captioner,对原数据集进行重Caption与过滤,得到更高质量数据集再重新预训练MED。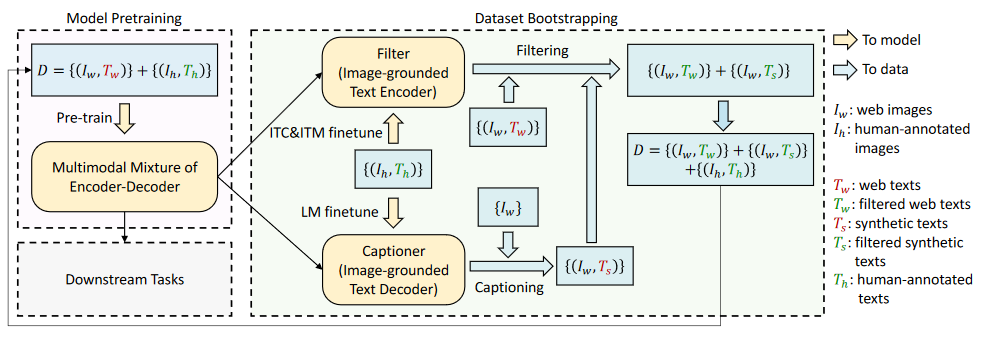
BLIP是如何微调的?
- Image-Text Retrieval:对预训练模型使用ITC和ITM loss,在COCO和Flickr30K上进行微调。
- Image Captioning:在COCO上使用LM loss进行微调。
- VQA:如下图,使用LM loss微调。
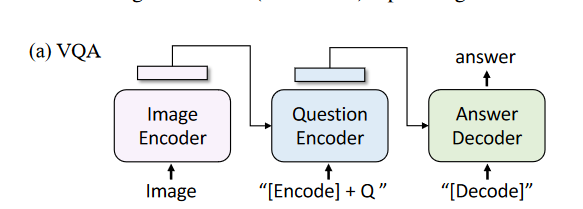
- NLVR:略。
- VisDial:略。
BLIP预训练使用的数据集
预训练数据集为:
- Conceptual Captions
- SBU Captions
- COCO
- Visual Genome
还引入了噪声更大的Conceptual 12M;还尝试了额外的Web数据集LAION.
BLIP2
BLIP2与BLIP的区别
- BLIP2使用预训练的LLM。
- BLIP2引入了Q-former作为预训练视觉模型与LLM之间的桥梁,大大减少了预训练的训练参数与训练成本。
BLIP2的模型架构
由一个冻结的Vision Encoder,一个冻结的LLM,一个Q-Former和一个FC的Connector组成。其中在预训练过程中,Vision encoder和LLM始终冻结。其中Vision Encoder采用了两种 (1) CLIP-ViT-L/14 (2) EVA-CLIP-VIT-g/14。LLM有两种:(1) Decoder-based的OPT (2)Encoder-Decoder-based FlanT5。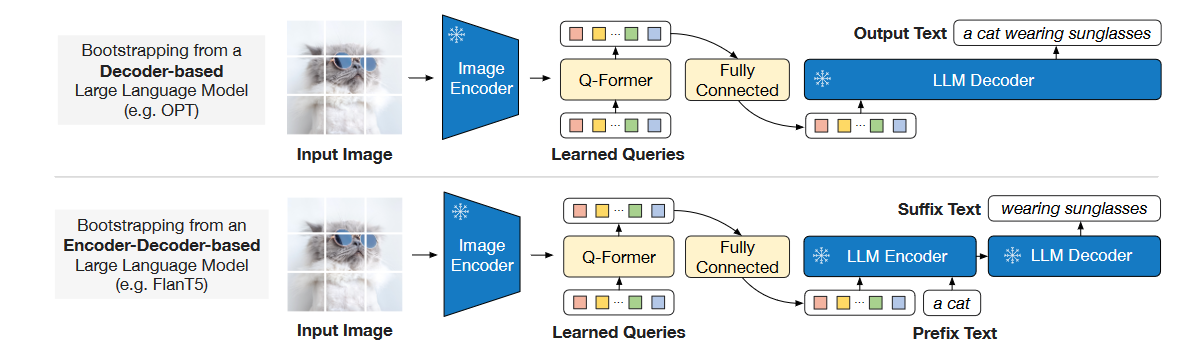 Q-former 由两个Transformer子模块组成,两部分共享Self-attention层。Image transformer通过Cross attention与图片特征交互,Text transformer可以通过Self attention从可学习Queries获取视觉特征。根据预训练任务的不同,Self-attention的mask也会不同。Q-former的权重由预训练的BERT-base初始化来,而Cross attention部分随机初始化。BLIP-2中使用了32个Queries,每个维度768,这远小于提取到的图像特征(32x768 << 257x1024)。
Q-former 由两个Transformer子模块组成,两部分共享Self-attention层。Image transformer通过Cross attention与图片特征交互,Text transformer可以通过Self attention从可学习Queries获取视觉特征。根据预训练任务的不同,Self-attention的mask也会不同。Q-former的权重由预训练的BERT-base初始化来,而Cross attention部分随机初始化。BLIP-2中使用了32个Queries,每个维度768,这远小于提取到的图像特征(32x768 << 257x1024)。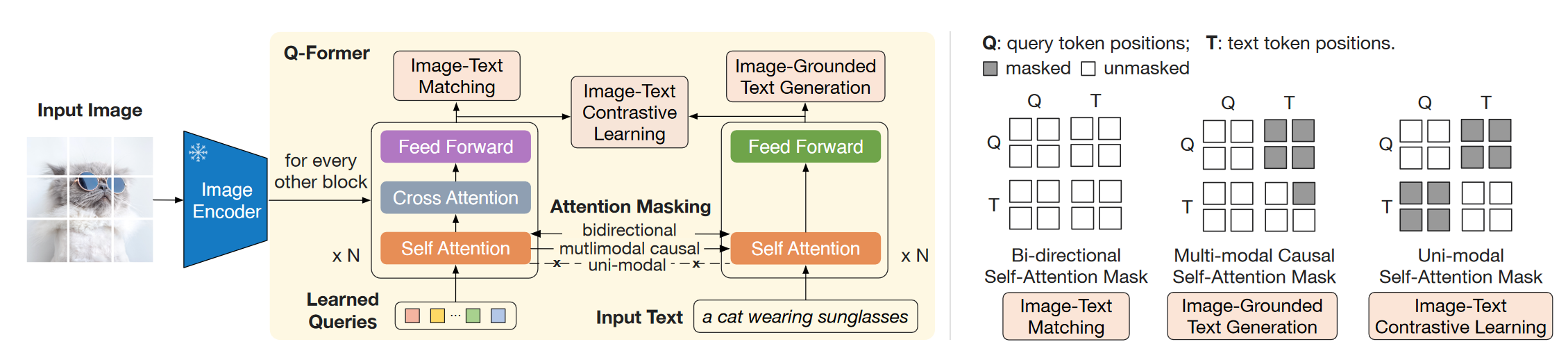
BLIP2的预训练过程
由两阶段组成:第一阶段Vision-language表征学习,第二阶段Vision-to-language生成学习。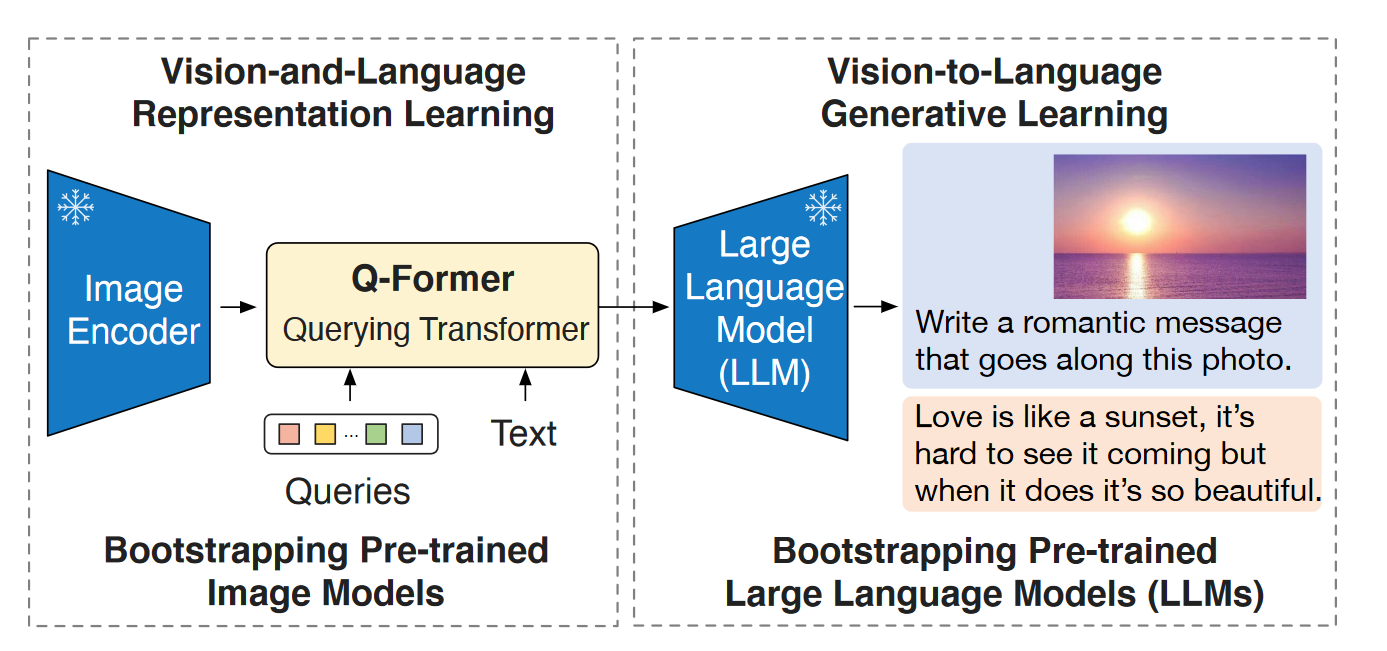
(1) 第一阶段:表征学习,将冻结的Image encoder和可学习的Q-former连在一起,同时优化三种优化目标。
- Image-Text Contrastive Learning:对齐文本与图像,最大化两者之间的互信息。这一部分采用的是Image transformer输出的Query representation和Text transformer输出的[CLS] token。由于Queries有32个,因此这里会每个计算相似度然后取最高的作为Image-Text similarity。为了避免信息泄露,这里采用的是Unimodal self-attention mask。
- Image-grounded Text Generation:训练Q-former根据图像生成文本。由于text transformer不能直接和视觉特征交互,因此首先由Queries提取视觉信息,然后通过Self attention传递给text token。这里采用了Multimodel causal Self-attention mask。同时也会将开头的[CLS] token更换为[DEC]。
- Image-Text Matching:对文本和图像进行更细粒度的对齐。这里采用了Bi-directional Self-attention mask,因此输出的query embedding能够捕获多模态信息。然后将query embedding输入二分类头获得logit后进行average得到输出的matching score。
(这一部分实现原理是:attenion时把query和text 拼接起来输入到一个self-attention模块,然后通过mask控制query和text之间的交互,然后attention之后再把query和text分开进行后面的操作,所以实际上是同一个Bert模型。参考BLIP2官方代码)
(2) 第二阶段:视觉到语言生成学习。将Q-former和冻结的LLM连接,并通过FC对齐query embedding和text embedding的维度。然后将投影过的query embeddings附加在text input embedding的前面,作为Soft Visual Prompt,为LLM提供有用的视觉信息并去除无关的视觉信息。这里进行了两种LLM的实验,对于Decoder-based使用LM loss,对于Encoder-decoder的使用Prefix LM loss。
BLIP2预训练使用的数据集
和BLIP一样使用下面6个数据集,图片加起来约为129M.
- Conceptual Captions
- SBU Captions
- COCO
- Visual Genome
- 噪声更大的Conceptual 12M
- 额外的Web数据集LAION400M的一部分。
BLIP2是如何微调的?
Image Cptioning:用”A photo of”作为初始输入给LLM,使用LM loss训练。保持LLM冻结,更新Q-former和Image encoder的参数。
VQA:保持LLM冻结,更新Q-former和Image encoder的参数。 使用Open-ended answer generation loss微调。同时额外为Q-former注入question信息,能够知道Q-former在cross attention层聚焦于更含信息的区域。
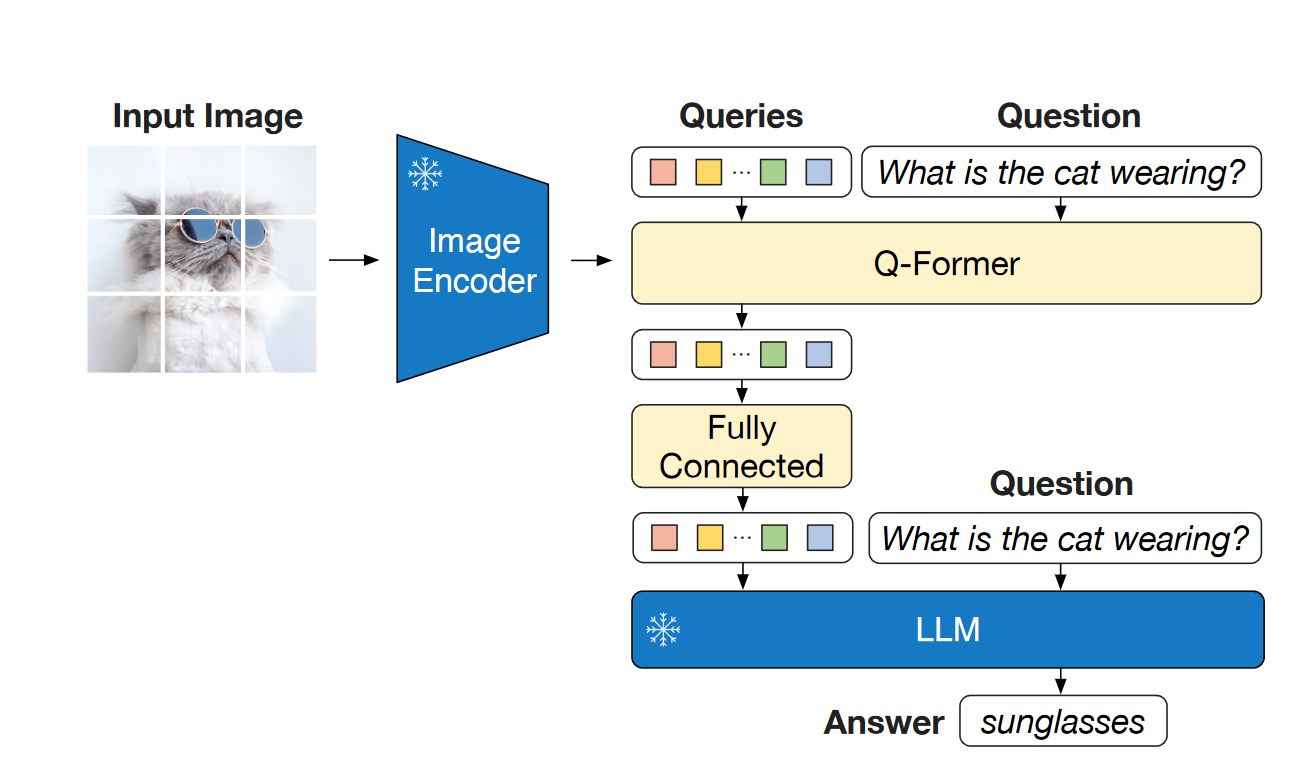
Image-Text Retrieval:直接在第一阶段预训练模型上微调。同时微调Image encoder和Q-former。推理时,先根据Image-text feature similarity选出128个candidate,然后根据成对的Image-text matching scores进行重排序。
BLIP-2的局限性
LLM 一般具备 In-Contet Learning 的能力,但是在 In-Context VQA 的场景下,BLIP-2 没观察到好的结果。对于这种上下文学习能力的缺失,作者把原因归结为预训练数据集中的每个数据只包含一个图像-文本对,导致 LLM 无法从中学习单个序列中多个图像-文本对之间的相关性。
BLIP-2 的图文生成能力不够令人满意,可能是 LLM 知识不准确带来的。同时 BLIP-2 继承了冻结参数的 LLM 的风险,比如输出攻击性语言,传播社会偏见。解决的办法是指令微调,或者过滤掉有害的数据集。
Q-former作用?
图文对齐、维度压缩。
可学习的Query作用是什么?
- 从视觉信息中提取与文本最相关的信息。
- 使得提取出的信息能够被LLM理解
Q-former和MLP的优劣在哪里?
(1) Q-former会导致视觉token的有损压缩,会把任意长度的visual token转译成32个token,丢失部分空间信息。
(2) Q-former相比于MLP参数量更大,收敛更慢,小数据量不如MLP,大数据量对比MLP也没有优势。
InstructBLIP
LLaVa系列
LLaVa
LLaVa数据集的构建
根据COCO中的caption和bbox,可以利用language-only GPT-4生成三种instruction data.
- Conversation: 多轮对话,根据caption中的每一部分,生成一个人不断提问某张图片的instruction数据。
- Detailed description:详细描述,由原始caption生成详细的描述。
- Complex reasoning:对图片中内容的一些复杂推理。
LLaVa收集了158K的instruction-following数据,包括58K的conversations,23K的detailed description,77K的complex reasoning。
LLaVa的结构
vision encoder采用预训练的CLIP-ViT-L/14,取最后一层或倒数第二层特征;language decoder采用Vicuna。视觉与文本之间的对齐通过一层线性层对齐。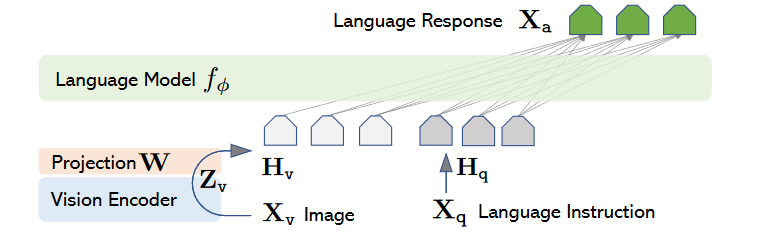
LLaVa训练过程
- 第一阶段:特征对齐预训练。训练数据为过滤后的595K对CC3M.每个图片文本对被视为单轮对话数据(即response为图片的caption)。该过程中冻结Vision encoder和LLM,仅训练Projector。
- 第二阶段:端到端微调。这一过程中将Vision encoder冻结,训练LLM和projector。有两种场景的微调:多模态聊天机器人,使用前面采集的三种response作为训练数据,训练过程中均匀采样;SicenceQA,对于给定的问题提供完整的推理过程和选择的答案,训练数据以单轮对话形式输入。
LLaVa实验设置

LLaVa-v1.5
LLaVa1.5的改进
- 结构改进:Projector换成了2层MLP,Vision encoder变成了CLIP-ViT-L-336px,LLM升级为Vicuna1.5。LLaVa-v1.5-HD版本增加了对高分辨率图片的支持,将高分辨率分成多个grid分别输入原始encoder,然后concat起来获得视觉信息。
- 数据改进:
- 增加了具有简单响应格式提示词的学术导向的VQA数据集,其中简单格式响应提示词例如:Answer the question using a single word or phrase,主要是为了配合数据集简短的答案,避免歧义。
- 预训练数据集使用LAION/COC/SBU的子集,共558K;instruction数据集共665K,在1.0基础上增加了ShareGPT数据集、学术导向的VQA数据集、OCR数据集、Region-level的VQA数据集。
LLaVa1.5存在的限制
- 使用全图补丁,增加了训练时间。
- 不能处理多图,因为缺少这样的指令微调数据,以及上下文长度的限制。
- 在一些特定领域效果不佳。
- 依旧存在幻觉和错误信息。
MiniGPT-4
MiniGPT-4模型结构
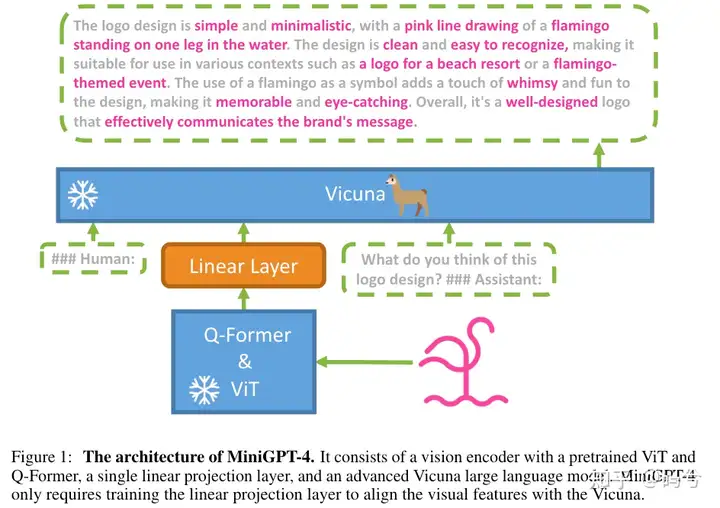
视觉部分: BLIP2中预训练的ViT-G/14和Q-former;
LLM部分:Vicuna
模态对齐:一个Linear Projection Layer
所有过程中,LLM和视觉部分都冻结,仅训练Linear Projection。MiniGPT-4训练过程
第一阶段预训练,模态对齐。使用Conceptual Caption、SBU和LAION等数据集训练,仅训练Linear Projection。经过第一阶段的pretrain,作者发现了一些模型很难产生连贯的语言输出的例子,而且会输出一些重复的单词或句子、支离破碎的句子或无关的内容。
第二阶段微调,与人类对话对齐。在构建的包含3500对<图片,Instruction,Answer>数据集上进行微调。仅训练Linear Projection。MiniGPT-4数据集构建
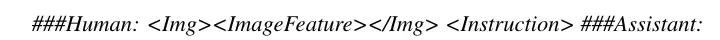
- 从Conceptual Caption中采样5000张图片,让第一阶段的模型去输出详细的描述。如果模型输出的token不够80个token,就使用continue命令让模型一直输出,直到产生足够的图片描述。
- 数据后处理,使用ChatGPT对图像描述进行纠错,然后人工核验数据。最终从5000条数据中得到3500条高质量训练数据。
Qwen-VL系列
Qwen-VL
Qwen-VL的模型架构
LLM:使用Qwen-7B初始化
Vision Encoder:采用OpenCLIP-ViT-bigG-14
Adapter:Position-aware VL Adapter。- 该adapter包含一个随机初始化的单层cross-attention模块,该模块使用一组可训练的embedding作为query向量,使用视觉编码器输出的图像特征作为key、value。
- 另外,考虑到位置信息对细粒度图像理解的重要性,2D绝对位置编码被结合到cross-attention的query-key pairs中,以减轻压缩过程中位置细节的潜在损失。
作用:(1)对图片token数压缩,压缩到固定长度256;(2)同时与LLM文本模态对齐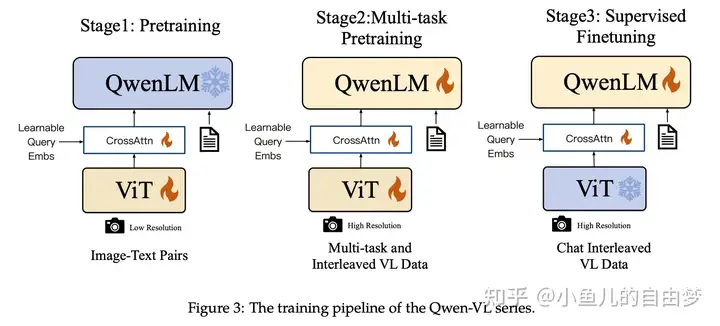
Qwen-VL的输入和输出
输入:
- 文本输入。
- 图像输入:与其他MLM一样。
- bbox输入:为了增强模型对细粒度视觉理解和定位的能力,Qwen-VL的训练涉及区域描述、问题和检测的数据形式。对于任何给定的边界框,会进行归一化处理 (在[0,1000)范围内),并转换为指定的字符串格式:”(X_{topleft},Y_{topleft}),(X_{bottomright},Y_{bottomright})”。该字符串作为文本被token化,不需要额外的位置词汇表。为了区分检测字符串和常规文本字符串,在边界框字符串的开头和结尾添加两个特殊token (
和 )。另外,为了适当地将边界框与其对应的描述词或句子相关联,引入了另一组特殊token (和),标记边界框所指的内容。
Qwen-VL的训练过程
训练由三个阶段组成,见上图。
Stage 1:预训练。使用清洗后的图文对,原始有5B的数据,清洗后有1.4B。此阶段冻结LLM,训练视觉编码器和Adapter,输入分辨率224。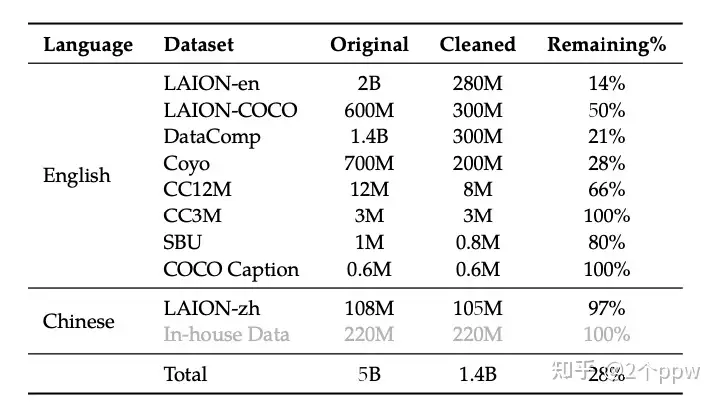
Stage 2:多任务预训练。使用更好的图文对数据,包括captioning、VQA、Grounding、OCR等。此阶段所有部分都要训练。使用更大分辨率448.
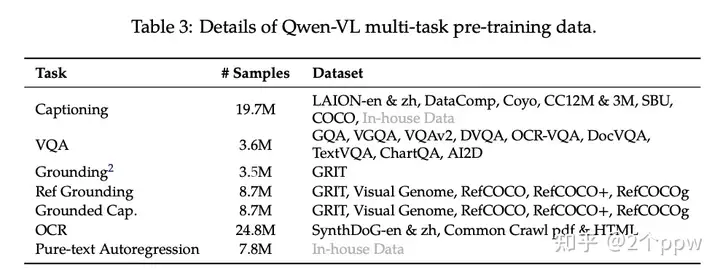
Stage 3:SFT。采用多模态数据和纯文本数据混合微调,得到350K指令微调数据,以增强其遵循指令和对话能力,得到Qwen-VL-Chat(数据中有多图数据,能够有多图对话的能力)。此阶段冻结视觉编码器,训练LLM和Adapter。这样的好处是,减弱文本能力的遗忘。
Qwen-VL2
Qwen2-VL相对于Qwen1的改进主要体现在以下几个方面:
- 增强的图像理解能力:Qwen2-VL显著提高了模型理解和解释视觉信息的能力,为关键性能指标设定了新的基准 。
- 高级视频理解能力:Qwen2-VL具有卓越的在线流媒体功能,能够以很高的精度实时分析动态视频内容 。
- 集成的可视化agent功能:Qwen2-VL现在无缝整合了复杂的系统集成,将Qwen2-VL转变为能够进行复杂推理和决策的强大可视化代理 。
- 扩展的多语言支持:Qwen2-VL扩展了语言能力,以更好地服务于多样化的全球用户群,使Qwen2-VL在不同语言环境中更易于访问和有效 。
- 模型结构:Qwen2-VL实现了动态分辨率支持(Naive Dynamic Resolution support),能够处理任意分辨率的图像,而无需将其分割成块,从而确保模型输入与图像固有信息之间的一致性 。
- Multimodal Rotary Position Embedding:通过将original rotary embedding分解为代表时间和空间(高度和宽度)信息的三个部分,M-ROPE使LLM能够同时捕获和集成1D文本、2D视觉和3D视频位置信息 。
- 模型效果:Qwen2-VL-7B在文档理解任务(例如DocVQA)和通过MTVQA评估的图像多语言文本理解方面表现出色,建立了非常优秀的性能 。
- 视频支持:Qwen2-VL增加了对视频的支持,能够理解长视频,并将其用于基于视频的问答、对话和内容创作等应用中 。
- Visual Agent能力:Qwen2-VL提升了function call以及Agent能力,能够与环境实现交互,进行复杂任务的执行 。
其它
多模态的发展路径
双塔型:CLIP,Prefix型:ViLT->多模态的GPT-3:Flamingo,先对齐再融合:ALBEF,多任务预训练:BLIP->使用LLM:BLIP-2,LLaVa,Instruct-BLIP,Qwen-VL等->全模态:ImageBind
多模态模型支持的任务类型
- Image-Text Retrieval
- Image Captioning
- Visual Question Answering, VQA
- Natural Language Visual Reasoning, NLVR
- Visual Dialogue
对比学习的本质是在解决什么问题,目的是什么?
本质上是自监督学习,即学习一个编码器,此编码器对同类数据进行相似的编码,并使不同类的数据的编码结果尽可能的不同。使模态间的互信息最大化。