





BLIP
BLIP的主要贡献
- 提出了一种Multimodal mixture of Encoder-Decoder(MED)的多模态预训练模式。
- 提出了一种Captioning and Filtering的Dataset Bootstrapping机制,对原始数据集进行清洗。
- 微调后在下游Image-text retrieval、Image captioning、VQA等任务上达到了SOTA。
BLIP的模型架构
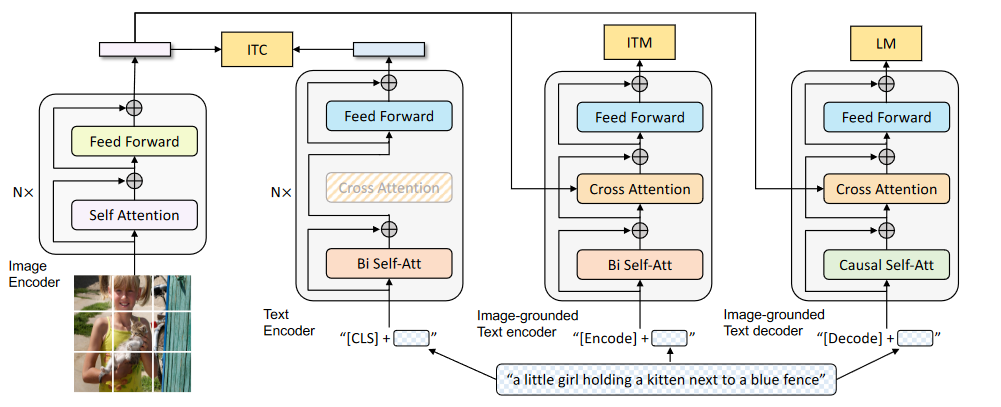
Unimodal Vision Encoder:采用的是在ImageNet-1k预训练的ViT(与LLaVa使用的不同)。
Unimodal Text Encoder:采用的是Bert-base,取[CLS] token的特征作为文本特征。
Image-grounded Text Encoder:采用Bert,在SA和FFN中间加上Cross Attention层,和图像特征交融。对于文本的输入,会在开头加上task-specific的[Encode]。
Image-grounded Text Decoder:将Image-grounded Text Encoder中的Bi Self-Att改为Causal Self-Att,同时也会和图像特征通过CA交融。会在开头加上[Decoder]表示序列起点,以及[EOS]表示序列终点。
后两部分除了Self-Att层不共享,其余部分参数共享。
BLIP的预训练目标
- Image-Text Contrastive Loss:将文本和图像在特征空间对齐,使用的是InfoNCE。实现方式上采用了ALBEF中的Momentum encoder。
- Image-Text Matching Loss:学习文本和图像之间的细粒度匹配,使用的是BCE loss。实现方式上采用了ALBEF中的Hard negative mining策略,即对于一个batch中用于更高对比相似度的负样本,更容易被选择来计算loss。
- Language-modeling loss:以自回归的方式进行极大似然估计,使用的是CE loss。计算时候使用了0.1的label smoothing。
BLIP的CapFilt机制
为了对含有噪声的Alt-text对进行过滤清洗,人工标注部分数据集得到高质量文本-图像对,然后分别微调得到一个Filter和一个Captioner,对原数据集进行重Caption与过滤,得到更高质量数据集再重新预训练MED。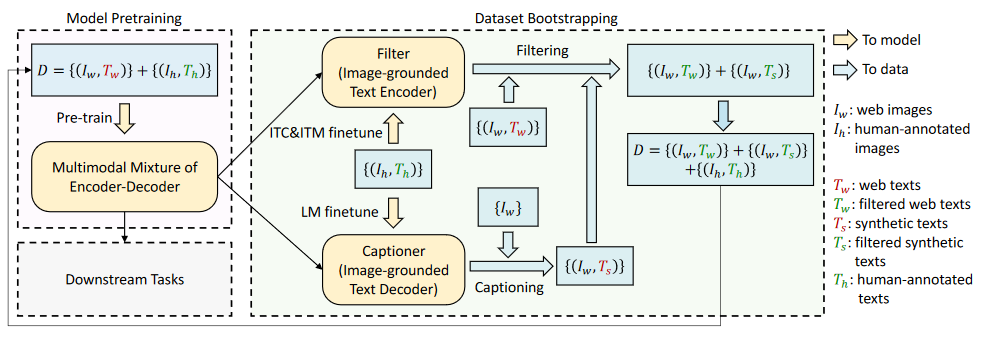
BLIP是如何微调的?
- Image-Text Retrieval:对预训练模型使用ITC和ITM loss,在COCO和Flickr30K上进行微调。
- Image Captioning:在COCO上使用LM loss进行微调。
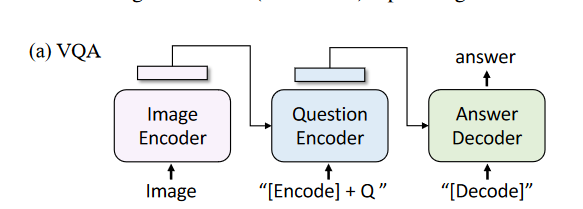
- VQA:如下图,使用LM loss微调。
- NLVR:略。
- VisDial:略。
BLIP预训练使用的数据集
预训练数据集为:
- Conceptual Captions
- SBU Captions
- COCO
- Visual Genome
还引入了噪声更大的Conceptual 12M;还尝试了额外的Web数据集LAION.
BLIP2
BLIP2与BLIP的区别
- BLIP2使用预训练的LLM。
- BLIP2引入了Q-former作为预训练视觉模型与LLM之间的桥梁,大大减少了预训练的训练参数与训练成本。
BLIP2的模型架构
由一个冻结的Vision Encoder,一个冻结的LLM,一个Q-Former和一个FC的Connector组成。其中在预训练过程中,Vision encoder和LLM始终冻结。其中Vision Encoder采用了两种 (1) CLIP-ViT-L/14 (2) EVA-CLIP-VIT-g/14。LLM有两种:(1) Decoder-based的OPT (2)Encoder-Decoder-based FlanT5。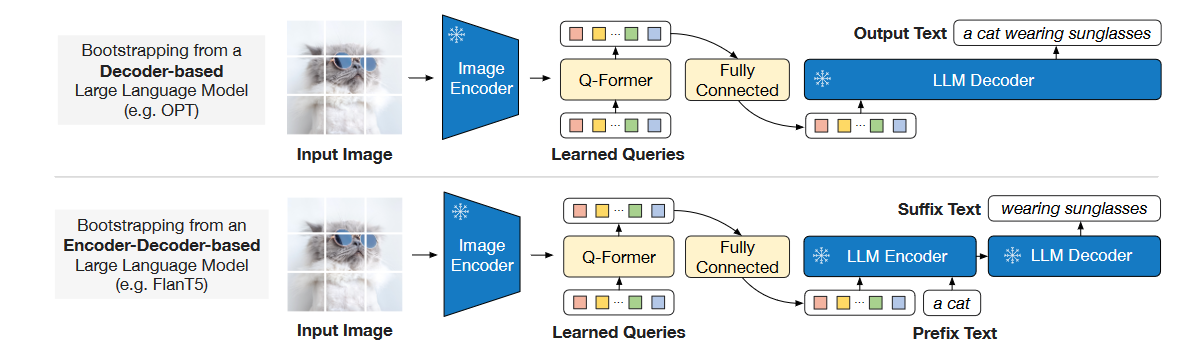 Q-former 由两个Transformer子模块组成,两部分共享Self-attention层。Image transformer通过Cross attention与图片特征交互,Text transformer可以通过Self attention从可学习Queries获取视觉特征。根据预训练任务的不同,Self-attention的mask也会不同。Q-former的权重由预训练的BERT-base初始化来,而Cross attention部分随机初始化。BLIP-2中使用了32个Queries,每个维度768,这远小于提取到的图像特征(32x768 << 257x1024)。
Q-former 由两个Transformer子模块组成,两部分共享Self-attention层。Image transformer通过Cross attention与图片特征交互,Text transformer可以通过Self attention从可学习Queries获取视觉特征。根据预训练任务的不同,Self-attention的mask也会不同。Q-former的权重由预训练的BERT-base初始化来,而Cross attention部分随机初始化。BLIP-2中使用了32个Queries,每个维度768,这远小于提取到的图像特征(32x768 << 257x1024)。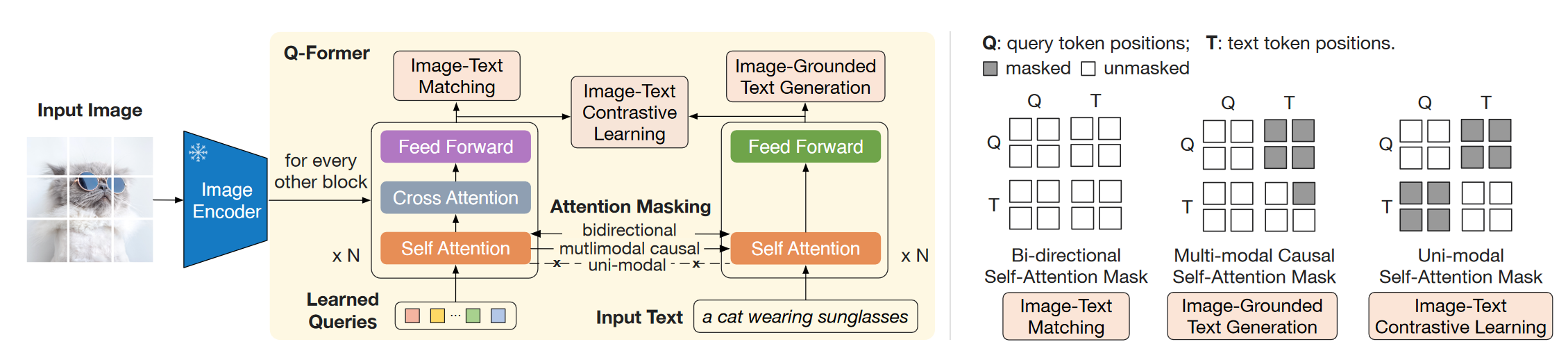
BLIP2的预训练过程
由两阶段组成:第一阶段Vision-language表征学习,第二阶段Vision-to-language生成学习。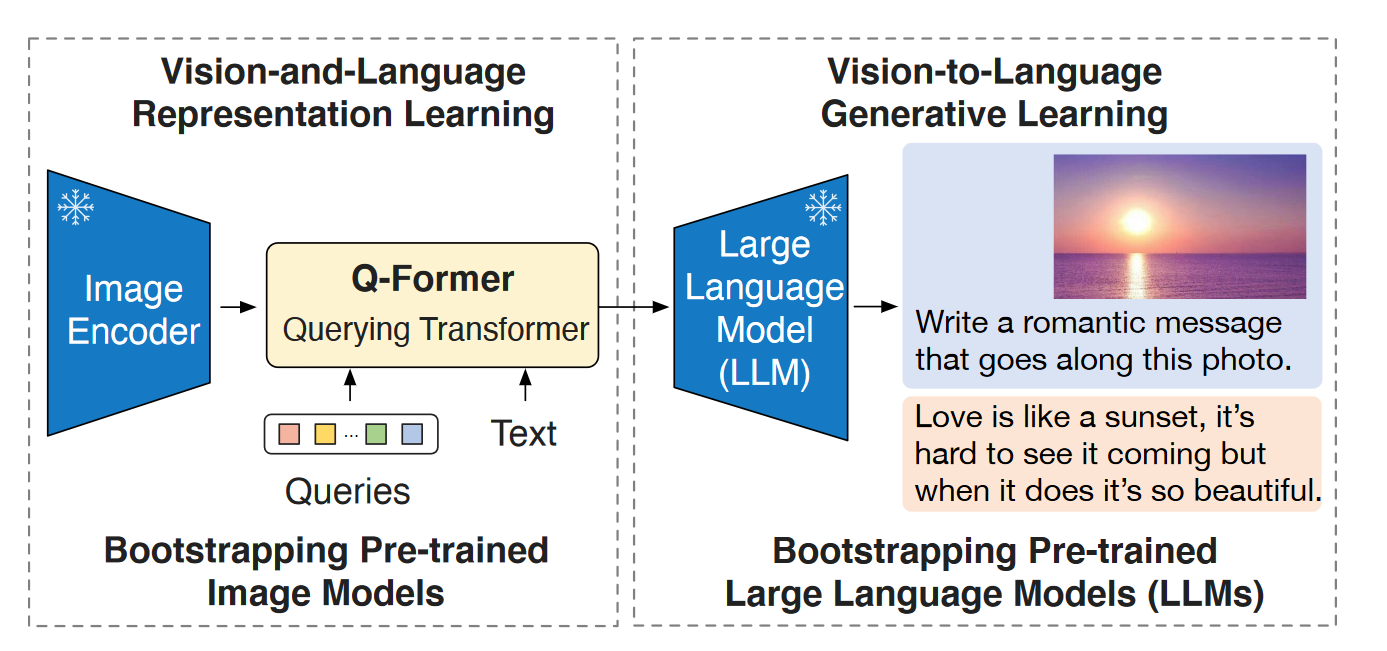
(1) 第一阶段:表征学习,将冻结的Image encoder和可学习的Q-former连在一起,同时优化三种优化目标。
- Image-Text Contrastive Learning:对齐文本与图像,最大化两者之间的互信息。这一部分采用的是Image transformer输出的Query representation和Text transformer输出的[CLS] token。由于Queries有32个,因此这里会每个计算相似度然后取最高的作为Image-Text similarity。为了避免信息泄露,这里采用的是Unimodal self-attention mask。
- Image-grounded Text Generation:训练Q-former根据图像生成文本。由于text transformer不能直接和视觉特征交互,因此首先由Queries提取视觉信息,然后通过Self attention传递给text token。这里采用了Multimodal causal Self-attention mask。同时也会将开头的[CLS] token更换为[DEC]。
- Image-Text Matching:对文本和图像进行更细粒度的对齐。这里采用了Bi-directional Self-attention mask,因此输出的query embedding能够捕获多模态信息。然后将query embedding输入二分类头获得logit后进行average得到输出的matching score。
(这一部分实现原理是:attenion时把query和text 拼接起来输入到一个self-attention模块,然后通过mask控制query和text之间的交互,然后attention之后再把query和text分开进行后面的操作,所以实际上是同一个Bert模型。参考BLIP2官方代码)
(2) 第二阶段:视觉到语言生成学习。将Q-former和冻结的LLM连接,并通过FC对齐query embedding和text embedding的维度。然后将投影过的query embeddings附加在text input embedding的前面,作为Soft Visual Prompt,为LLM提供有用的视觉信息并去除无关的视觉信息。这里进行了两种LLM的实验,对于Decoder-based使用LM loss,对于Encoder-decoder的使用Prefix LM loss。
BLIP2预训练使用的数据集
和BLIP一样使用下面6个数据集,图片加起来约为129M.
- Conceptual Captions
- SBU Captions
- COCO
- Visual Genome
- 噪声更大的Conceptual 12M
- 额外的Web数据集LAION400M的一部分。
BLIP2是如何微调的?
Image Cptioning:用”A photo of”作为初始输入给LLM,使用LM loss训练。保持LLM冻结,更新Q-former和Image encoder的参数。
VQA:保持LLM冻结,更新Q-former和Image encoder的参数。 使用Open-ended answer generation loss微调。同时额外为Q-former注入question信息,能够指导Q-former在cross attention层聚焦于更含信息的区域。
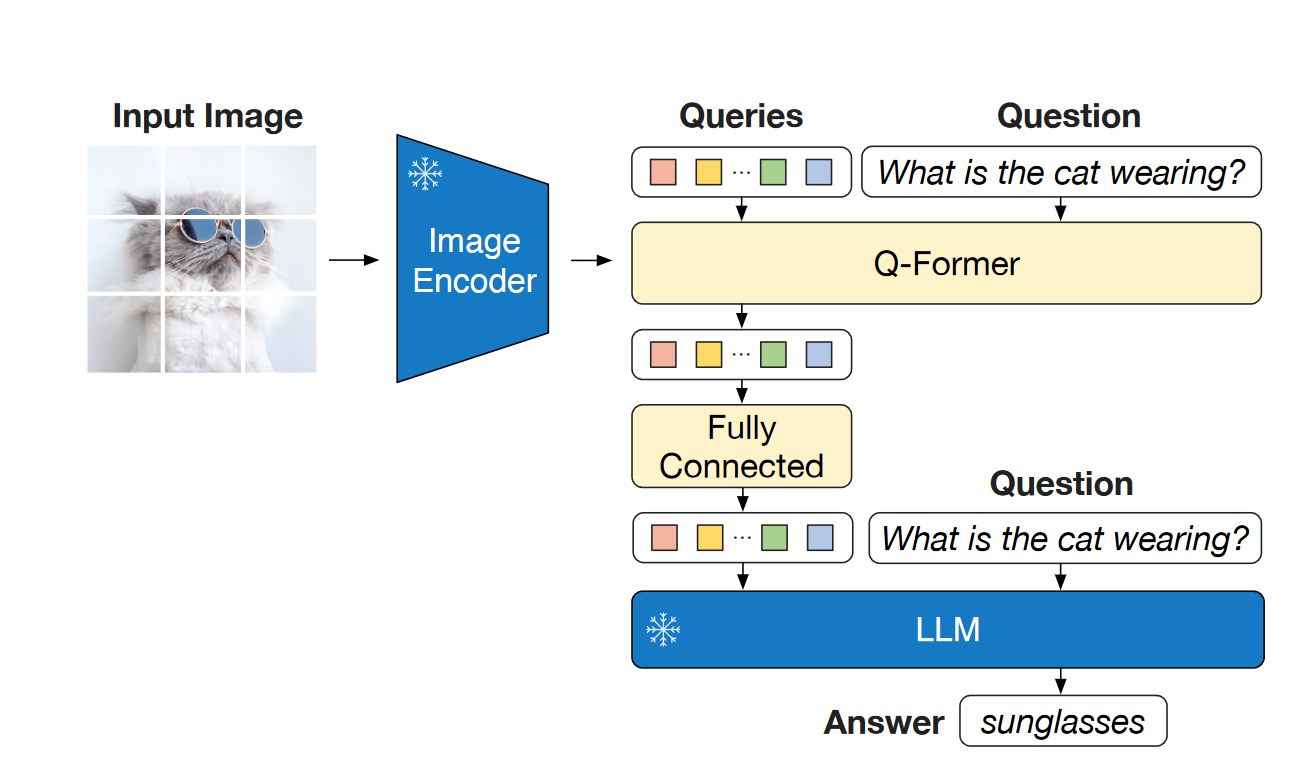
Image-Text Retrieval:直接在第一阶段预训练模型上微调。同时微调Image encoder和Q-former。推理时,先根据Image-text feature similarity选出128个candidate,然后根据成对的Image-text matching scores进行重排序。
BLIP-2的局限性
LLM 一般具备 In-Contet Learning 的能力,但是在 In-Context VQA 的场景下,BLIP-2 没观察到好的结果。对于这种上下文学习能力的缺失,作者把原因归结为预训练数据集中的每个数据只包含一个图像-文本对,导致 LLM 无法从中学习单个序列中多个图像-文本对之间的相关性。
BLIP-2 的图文生成能力不够令人满意,可能是 LLM 知识不准确带来的。同时 BLIP-2 继承了冻结参数的 LLM 的风险,比如输出攻击性语言,传播社会偏见。解决的办法是指令微调,或者过滤掉有害的数据集。
BLIP-2生成的caption一般比较简短,这与训练数据集有关。
Q-former作用?
图文对齐、维度压缩。
可学习的Query作用是什么?
- 从视觉信息中提取与文本最相关的信息。
- 使得提取出的信息能够被LLM理解
Q-former和MLP的优劣在哪里?
(1) Q-former会导致视觉token的有损压缩,会把任意长度的visual token转译成32个token,丢失部分空间信息。
(2) Q-former相比于MLP参数量更大,收敛更慢,小数据量不如MLP,大数据量对比MLP也没有优势。
InstructBLIP
BLIP3(xGen-MM)
BLIP3的模型结构
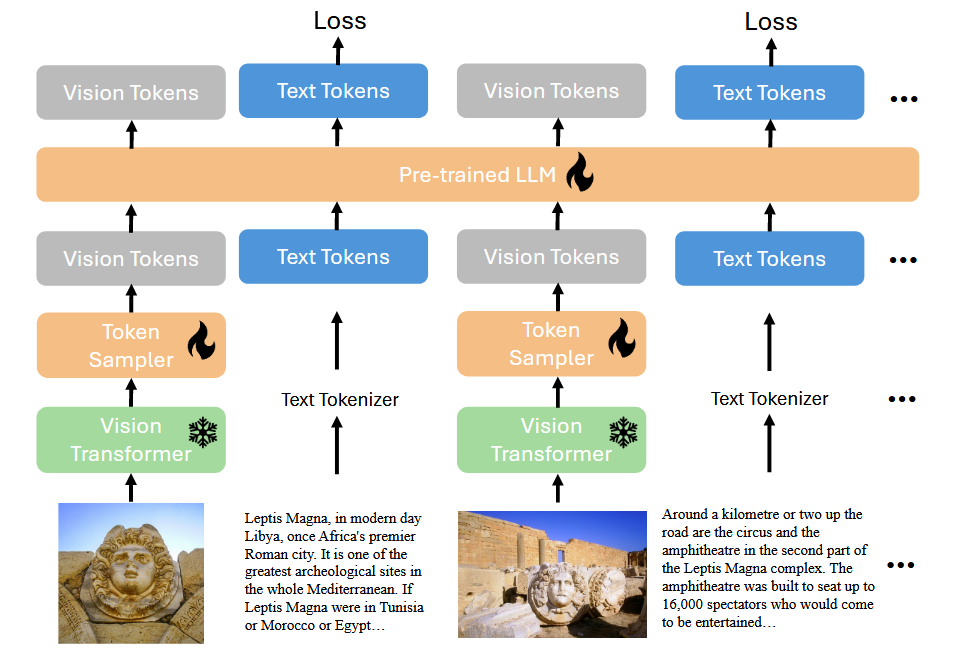
Vision encoder采用了SigLIP,Adaptor使用了Flamingo的perceiver resampler,LLM使用了Phi3-mini。
同时,采用了LLaVa-v1.5中的Any-Res策略(动态分辨率),将高分辨率图片切分成patch过后,分别进行encoding后拼接,同时将downsize的原图也进行encoding后接在后面。然后分别将每个patch过resampler,concat之后作为visual prompt。
在所有阶段中,Vision encoder冻结,只训练resampler和LLM。
BLIP3的训练recipe
- Pre-training:不再使用(ITC,ITG,ITM),统一使用Next token prediction作为loss。预训练时图像分辨率为384x384,这与SigLIP对齐。使用的数据集包括:图文交错数据集;高质量Caption和OCR数据集;高质量Visual Grounding数据集;其他公共数据集的混合。只训练resampler和LLM。
- SFT:这一阶段采用Any-Res策略进行动态分辨率的输入。使用的数据集包括:单图的Visual instruction数据(对话,Captioning,VQA,OCR等),以及只有文本的instruction数据。SFT了一个epoch。只训练resampler和LLM。
- Interleaved Multi-Image SFT:同样使用Any-Res策略。使用的数据集包括:单图和多图的Visual instruction数据。这样能够提高模型的in-context能力以及多图推理能力。只训练resampler和LLM。
- Post-training:有两步后训练:第一步使用DPO提高模型的helpfulness和visual faithfulness;第二步使用safety fine-tuning提高模型的harmlessness。这两步都是用LoRA仅训练LLM backbone。