





CLIP
CLIP模型结构
Image Encoder有两种架构:一种是ResNet50,将全局平均池化替换为注意力池化;第二种是ViT(Pre-norm)。
Text Encoder实际上是GPT-2架构,即Transformer decoder,将文本用[SOS]和[EOS]括起来,取[EOS]上的feature过一层Linear作为文本特征。CLIP训练时的损失函数
InfoNCE,一种用于自监督学习的特征表示学习损失函数。
公式:,N是样本的数量,q是查询样本的编码,k是与查询样本对应的正样本或负样本的编码。
目的:最大化正样本对相似度,最小化负样本对相似度。CLIP的loss中为什么是加上两部分的CE?
仅优化I(i,t)是最大化单向的互信息,CLIP的目标是学习联合分布,因此是两项之和,即每一项在一个方向上最大化互信息。
CLIP训练的伪代码

CLIP训练代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27image_embeds = vision_outputs[1]
image_embeds = self.visual_projection(image_embeds)
text_embeds = text_outputs[1]
text_embeds = self.text_projection(text_embeds)
# normalized features
image_embeds = image_embeds / image_embeds.norm(p=2, dim=-1, keepdim=True)
text_embeds = text_embeds / text_embeds.norm(p=2, dim=-1, keepdim=True)
# cosine similarity as logits
logit_scale = self.logit_scale.exp()
logits_per_text = torch.matmul(text_embeds, image_embeds.t()) * logit_scale
logits_per_image = logits_per_text.t()
loss = None
if return_loss:
loss = clip_loss(logits_per_text)
def contrastive_loss(logits: torch.Tensor) -> torch.Tensor:
return nn.functional.cross_entropy(logits, torch.arange(len(logits), device=logits.device))
def clip_loss(similarity: torch.Tensor) -> torch.Tensor:
caption_loss = contrastive_loss(similarity)
image_loss = contrastive_loss(similarity.t())
return (caption_loss + image_loss) / 2.0CLIP损失函数中温度系数的作用
温度系数的作用是调节对困难样本的关注程度:越小的温度系数越关注于将本样本和最相似的其他样本分开
如果温度系数设的越大,logits分布变得越平滑,那么对比损失会对所有的负样本一视同仁,导致模型学习没有轻重。
如果温度系数设的过小,logits分布会很尖锐,则模型会越关注特别困难的负样本,但其实那些负样本很可能是潜在的正样本,这样会导致模型很难收敛或者泛化能力差。CLIP的位置编码,如何外推?
CLIP的text encoder是GPT2,因此使用的Learable Positional Encoding,是绝对位置编码。理论上不能外推,但也许可以将超过长度的部分随机初始化然后微调。
CLIP少样本微调
Linear Probe
Encoder的embedding后接分类头,进行微调。
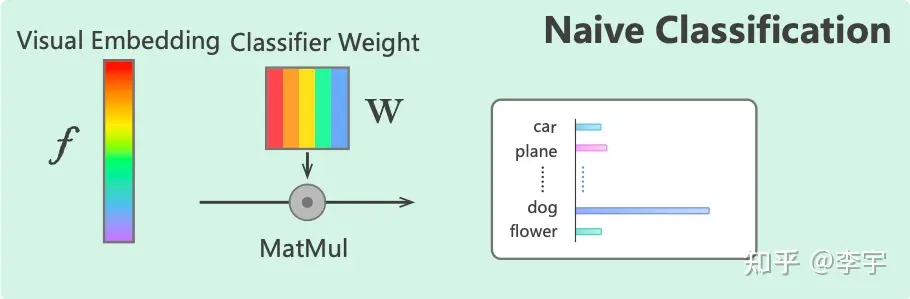
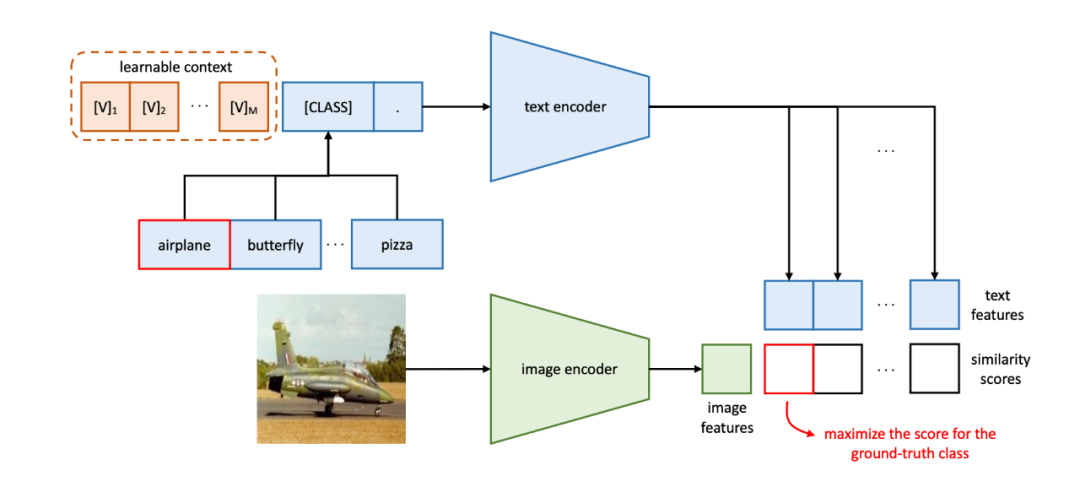
Context Optimization
针对CLIP中直接使用"A photo of"作为prompt可能不是最优的,CoOp提出使用可学习的token embedding,让模型自己调优prompt(可使用前人总结的prompt做初始化)。
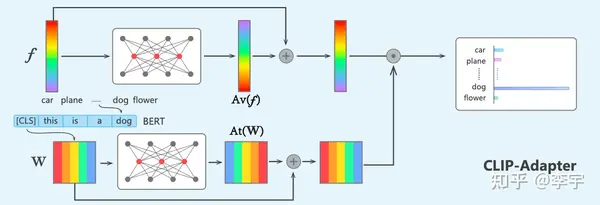
CLIP-Adapter
相较于CoOp,CLIP-Adapter的训练方式更加轻量化,只有两个残差连接的MLP。将两部分按照一定比例进行blend。(为什么要用残差连接?为了保留CLIP的原始能力)(为什么不全参微调?容易Over-fit以及catastrophic forgetting。)
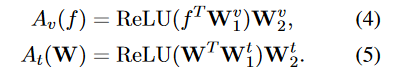
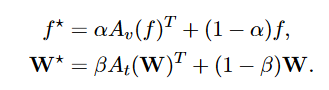
SigLIP
SigLIP的主要改进点
CLIP的对比学习损失InfoNCE,需要对一整个batch内的sample求L2 norm,这对多机不友好;并且性能也受到batch size大小的限制。
SigLIP提出使用每一对之间的sigmoid loss来作为学习目标,这样在概念上不受到batch size的限制;其次,也能通过一种高效的实现方式来对多卡通信速度进行提升。
SigLIP的损失项以及训练伪代码
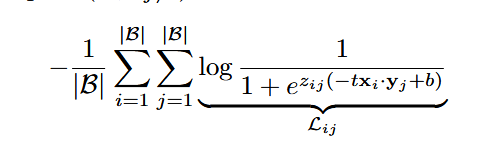
其中当为正样本对时,z为1;为负样本对时,z为-1。b是一个可学习的偏置项,其使用原因是训练样本中大部分为负样本对,需要在训练初期纠正这种偏置。t为可学习的温度参数。

SigLIP如何在多卡之间减少gather开销?

每次计算本卡上batch size的loss,然后每次互相交换text embeddings,最后将每个chunk的loss相加。