





Flamingo
Flamingo的贡献
- 桥接预训练好的视觉模型和语言模型
- 可以处理任意交错的图文对数据
- 可以同时以图像和视频数据作为输入
Flamingo实现了多模态领域的Few-shot learning(in-context learning)能力,即多模态领域的GPT-3。
Flamingo模型结构
通过Perceiver Resampler和Gated Xatten-dense,与新插入到LM中的层计算Cross-attention,从而将视觉信息注入的LM的生成过程中。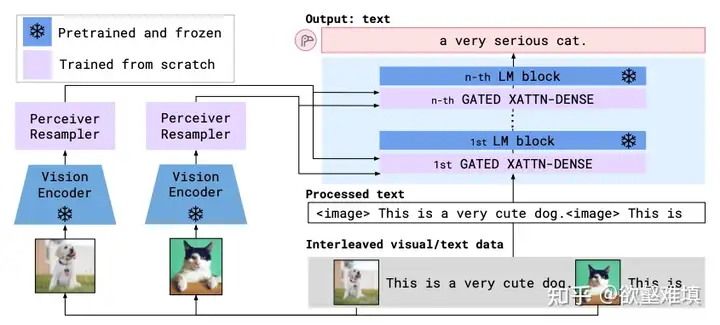
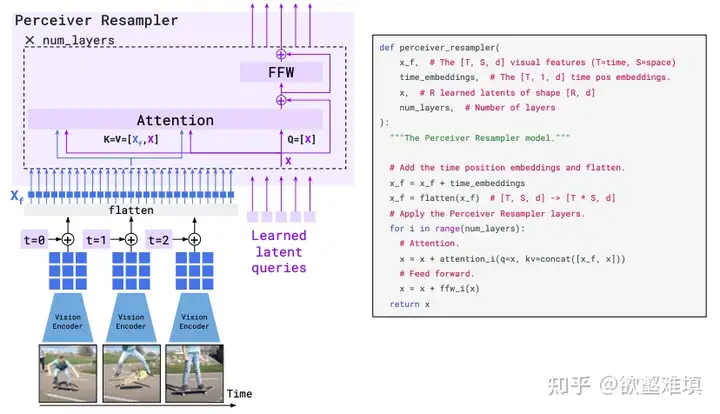
Perceiver Resampler:
1. 可以接收任意多个的视频帧(如果是图像,可以视作是单帧视频),经过视觉编码器提取特征,加上time embedding 之后全部展平,得到一个视觉 token 序列. 2. 同时有一个可学习的固定长度的latent query序列。 3. 计算CA时,Q是learnable query,KV是query和image feature拼接起来的。(这里和Q-former区别,Q-former是Q是query,KV是视觉feature) 4. 通过该模块,将视觉特征转成了少量低维度的query embedding。
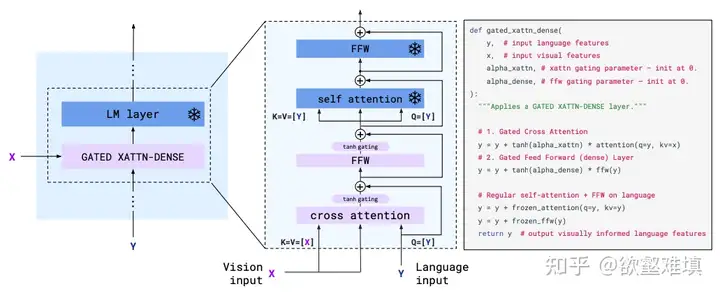
Gated Xattn Dense
将固定长度的视觉 query 注入到语言模型。在预训练好的 LM 的各层交替地插入一些随机初始化的CA。Gated门控,指的是在每一新插入的层之后的残差链接之前添加一个 tanh gating,即tanh(a),其中a是一个可学习的标量值,初始值为 0,从而保证初始化时的输出与原 LM 一致。
- Flamingo的输入以及训练数据
Flamingo的few-show能力来自交错图文对。训练数据中每次最多输入5个交错的图文对。
MiniGPT-4
MiniGPT-4模型结构
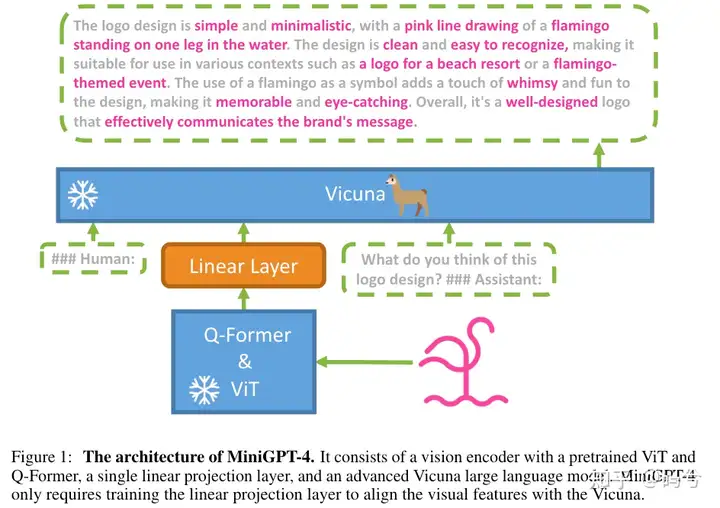
视觉部分: BLIP2中预训练的ViT-G/14和Q-former;
LLM部分:Vicuna
模态对齐:一个Linear Projection Layer
所有过程中,LLM和视觉部分都冻结,仅训练Linear Projection。MiniGPT-4训练过程
第一阶段预训练,模态对齐。使用Conceptual Caption、SBU和LAION等数据集训练,仅训练Linear Projection。经过第一阶段的pretrain,作者发现了一些模型很难产生连贯的语言输出的例子,而且会输出一些重复的单词或句子、支离破碎的句子或无关的内容。
第二阶段微调,与人类对话对齐。在构建的包含3500对<图片,Instruction,Answer>数据集上进行微调。仅训练Linear Projection。MiniGPT-4数据集构建
- 从Conceptual Caption中采样5000张图片,让第一阶段的模型去输出详细的描述。如果模型输出的token不够80个token,就使用continue命令让模型一直输出,直到产生足够的图片描述。
- 数据后处理,使用ChatGPT对图像描述进行纠错,然后人工核验数据。最终从5000条数据中得到3500条高质量训练数据。
VILA
VILA的贡献
- 预训练时解冻LLM可以模型的in-context learning能力。
- 使用图文交错的数据进行预训练对于VLM的多图推理能力和in-context能力有提升,同时能保持住LLM本身的能力。
- SFT时使用混合的text-instruction data和visual-instruction data不仅能够弥补在text-only task上的损失,还能提高VLM task的准确率。
VILA的训练过程
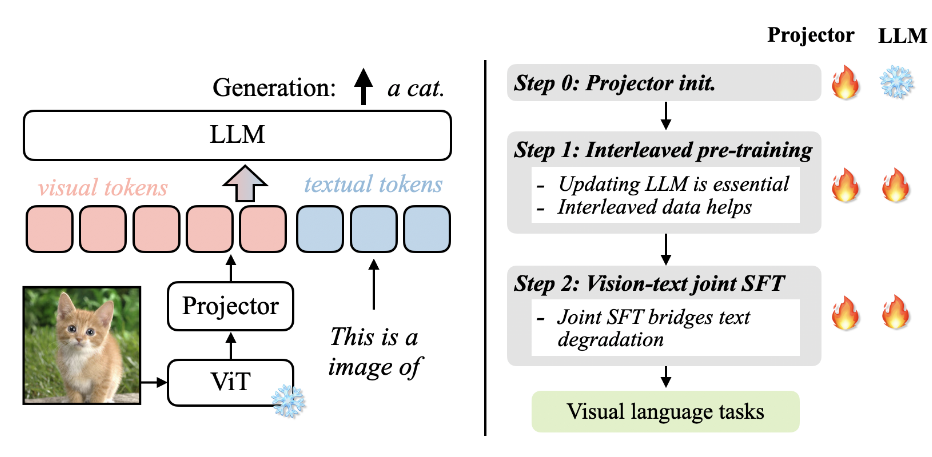
- 初始化Projector:使用image-caption对初始化Projector,冻结LLM,训练Projector。
- VL预训练:使用图文交错数据(MMC4)和图文对数据(COYO)作图文对齐,同时训练Projector和LLM。
- Visual instruction-tuning:使用FLAN风格的visual instruction数据与text instruction数据混合训练,同时训练LLM和Projector。