





LLaVa
LLaVa数据集的构建
根据COCO中的caption和bbox,可以利用language-only GPT-4,对其进行In-context learning来生成三种instruction data.
- Conversation: 多轮对话,根据caption中的每一部分,生成一个人不断提问某张图片的instruction数据。
- Detailed description:详细描述,由原始caption生成详细的描述。
- Complex reasoning:对图片中内容的一些复杂推理。
LLaVa收集了158K的instruction-following数据,包括58K的conversations,23K的detailed description,77K的complex reasoning。(LLaVa-Instruct-158K)
LLaVa的结构
vision encoder采用预训练的CLIP-ViT-L/14,取最后一层或倒数第二层特征;language decoder采用Vicuna。视觉与文本之间的对齐通过一层线性层对齐。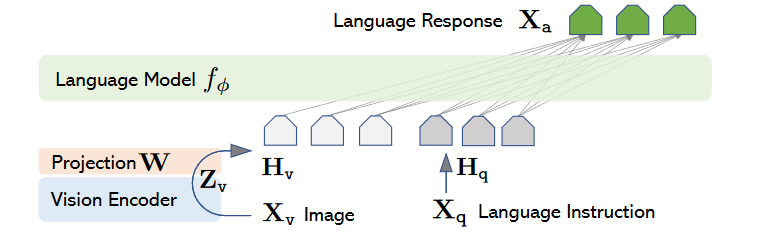
LLaVa训练过程
- 第一阶段:特征对齐预训练。训练数据为过滤后的595K对CC3M.每个图片文本对被视为单轮对话数据(即response为图片的caption)。该过程中冻结Vision encoder和LLM,仅训练Projector。
- 第二阶段:端到端SFT。这一过程中将Vision encoder冻结,训练LLM和projector。有两种场景的微调:多模态聊天机器人,使用前面采集的三种response作为训练数据,训练过程中均匀采样;SicenceQA,对于给定的问题提供完整的推理过程和选择的答案,训练数据以单轮对话形式输入。
LLaVa实验设置

LLaVa-v1.5
LLaVa1.5的改进
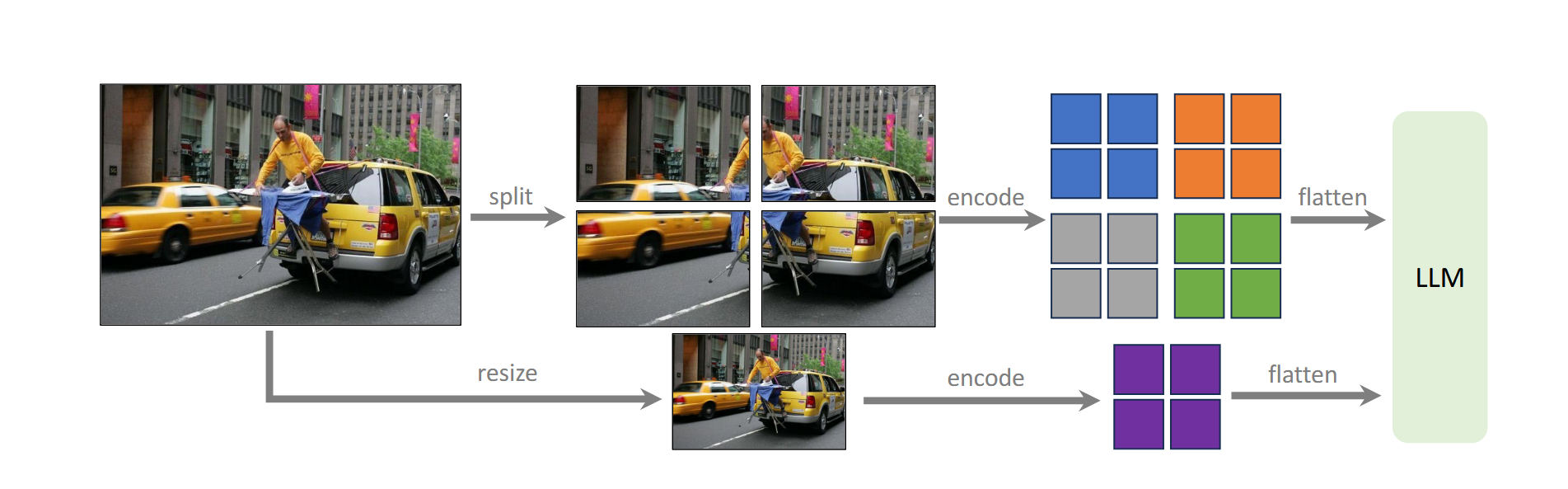
- 结构改进:(1)Projector换成了2层MLP,Vision encoder变成了CLIP-ViT-L-336px,LLM升级为Vicuna1.5。(2)LLaVa-v1.5-HD版本增加了对高分辨率图片的支持,将高分辨率分成多个grid分别输入原始encoder,然后concat起来获得视觉信息。
- 数据改进:
- 增加了具有简单响应格式提示词的学术导向的VQA数据集,其中简单格式响应提示词例如:Answer the question using a single word or phrase,主要是为了配合数据集简短的答案,避免歧义。
- 预训练数据集使用LAION/COC/SBU的子集,共558K;instruction数据集共665K,在1.0基础上增加了ShareGPT数据集、学术导向的VQA数据集、OCR数据集、Region-level的VQA数据集。
LLaVa1.5存在的限制
- (HD版本)使用全图补丁,增加了训练时间。同时视觉重采样器中引入了更多的可训练参数,当训练数据数量有限时可能不能有效收敛。
- 不能处理多图,缺少In-context learning能力,因为缺少这样的指令微调数据,以及上下文长度的限制。
- 在一些特定领域效果不佳。
- 依旧存在幻觉和错误信息。
LLaVa-NEXT(20240130)
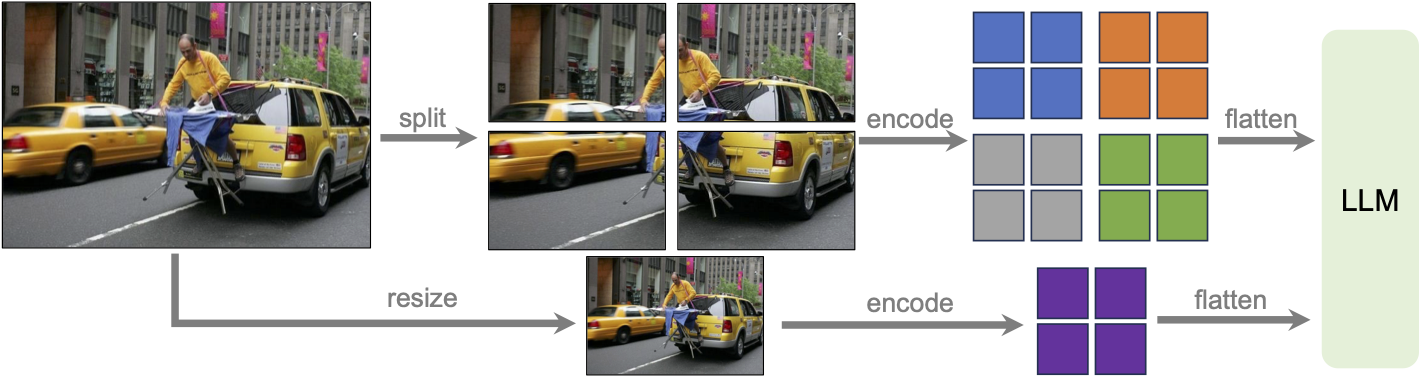
- 使用Any-Res增加更大的输入分辨率:三种aspect ratio:672x672,336x1344,1344x336。能够捕捉更多的视觉细节。
- 更好的Visual reasoning和OCR能力:使用的高质量的User Instruct数据,包括LAION-GPT-V和ShareGPT-4V;使用多模态的表格/文档数据。
- 对于更多场景的视觉对话能力:拥有更好的world knowledge和逻辑推断能力。
LLaVa-NEXT(20240525)
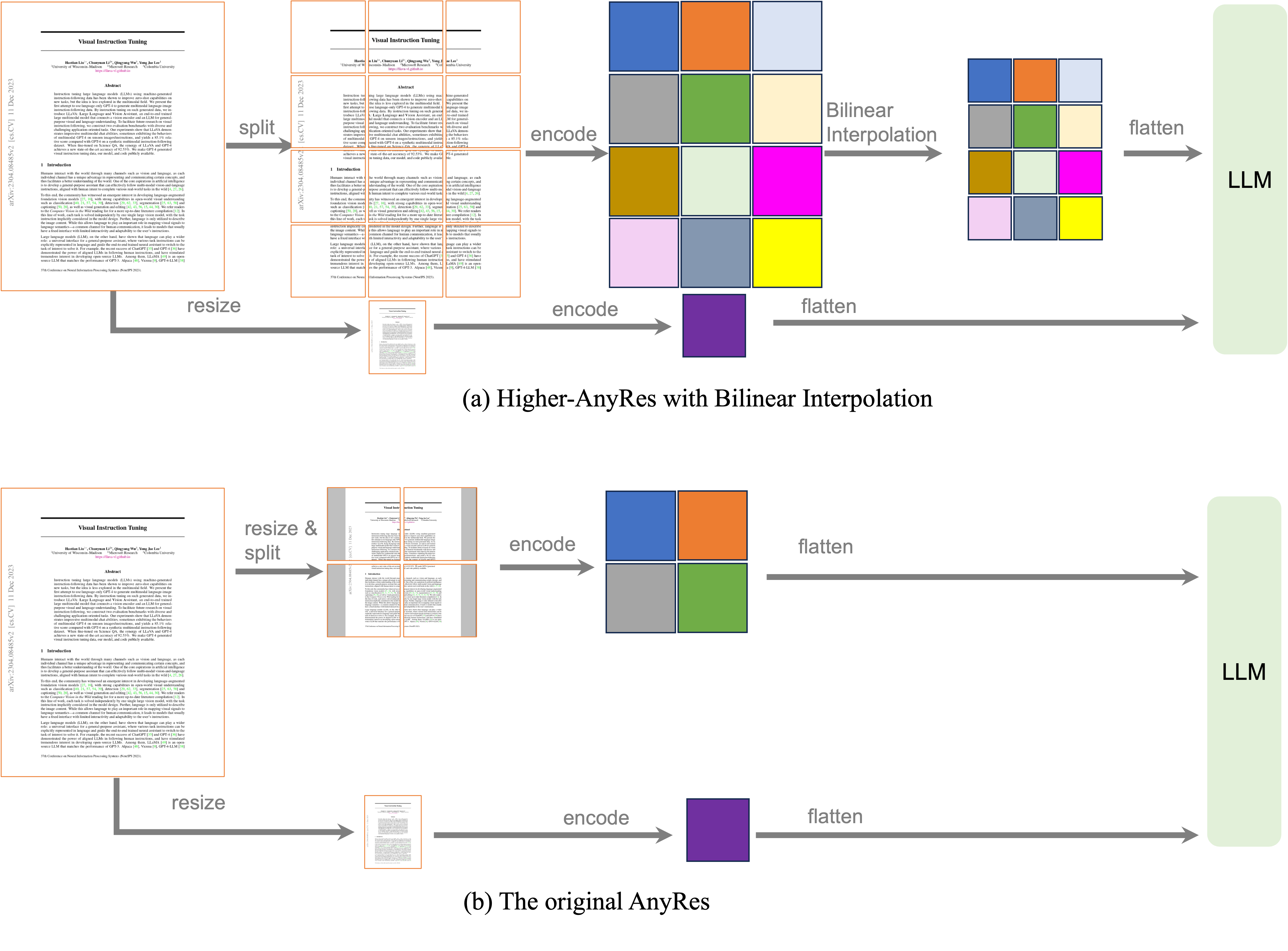
模型结构:scaling LLM比scaling Vison Encoder更有效提升模型性能。视觉信息的提升主要受分辨率、特征空间token数的限制。选用SigLIP-SO400M-ViT作为vision encoder,Qwen-1.5 0.5B作为LLM。Connector还是2层带ReLu的MLP。
视觉表征:使用更多的grid,以及双线性插值。
训练策略:
Stage 1-Text-image alignment:使用Public data和Web data做特征对齐。
Stage 1.5-High-Quality Knowledge Learning:使用更高质量的数据集强化VLM的知识。包括Re-captioned detailed description data,Document/OCR data,ShareGPT4V Chinese detailed caption。
Stage 2-Visual Instruction Tuning:与之前的一致。