





Qwen-VL
Qwen-VL的模型架构
LLM:使用Qwen-7B初始化
Vision Encoder:采用OpenCLIP-ViT-bigG-14
Adapter:Position-aware VL Adapter。- 该adapter包含一个随机初始化的单层cross-attention模块,该模块使用一组可训练的embedding作为query向量,使用视觉编码器输出的图像特征作为key、value。
- 另外,考虑到位置信息对细粒度图像理解的重要性,2D绝对位置编码被结合到cross-attention的query-key pairs中,以减轻压缩过程中位置细节的潜在损失。
作用:(1)对图片token数压缩,压缩到固定长度256;(2)同时与LLM文本模态对齐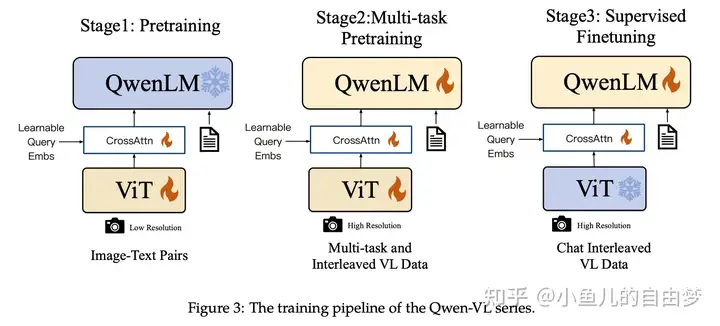
Qwen-VL的输入和输出
输入:
- 文本输入。
- 图像输入:与其他MLM一样。(由
和</img>将图片token框起来)
- bbox输入:为了增强模型对细粒度视觉理解和定位的能力,Qwen-VL的训练涉及区域描述、问题和检测的数据形式。对于任何给定的边界框,会进行归一化处理 (在[0,1000)范围内),并转换为指定的字符串格式:”(X_{topleft},Y_{topleft}),(X_{bottomright},Y_{bottomright})”。该字符串作为文本被token化,不需要额外的位置词汇表。为了区分检测字符串和常规文本字符串,在边界框字符串的开头和结尾添加两个特殊token (
和 )。另外,为了适当地将边界框与其对应的描述词或句子相关联,引入了另一组特殊token (和),标记边界框所指的内容。
Qwen-VL的训练过程
训练由三个阶段组成,见上图。
Stage 1:预训练。使用清洗后的图文对,原始有5B的数据,清洗后有1.4B。此阶段冻结LLM,训练视觉编码器和Adapter,输入分辨率224。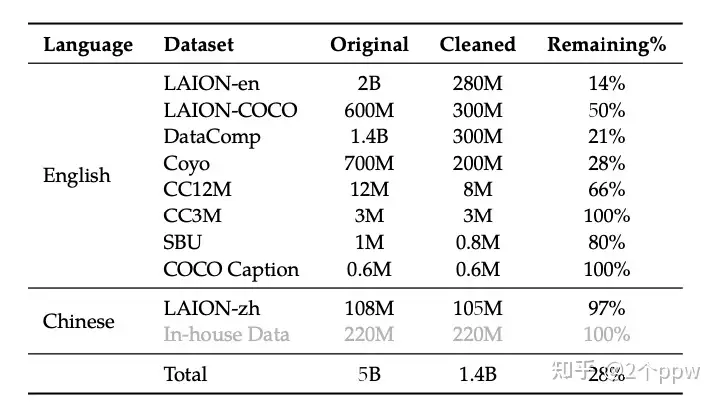
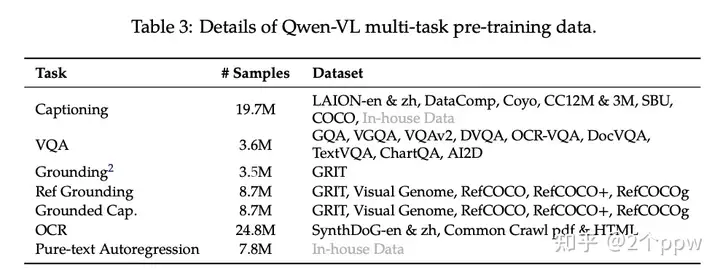
Stage 2:多任务预训练。使用更好的图文对数据以及图文交错数据,包括captioning、VQA、Grounding、OCR等。此阶段所有部分都要训练。使用更大分辨率448.
Stage 3:SFT。采用多模态数据(图文对和图文交错)和纯文本数据混合微调,得到350K指令微调数据,以增强其遵循指令和对话能力,得到Qwen-VL-Chat(数据中有多图数据,能够有多图对话的能力)。此阶段冻结视觉编码器,训练LLM和Adapter。这样的好处是,减弱文本能力的遗忘。