





Textual Inversion
Texual Inversion做的事情
给定3-5张某个主体的图片,冻结T2I模型,通过优化一个pseudo-word的embedding来使得模型学会生成该主体。在2张V100上优化了5000个steps。
Textual Inversion的优化流程
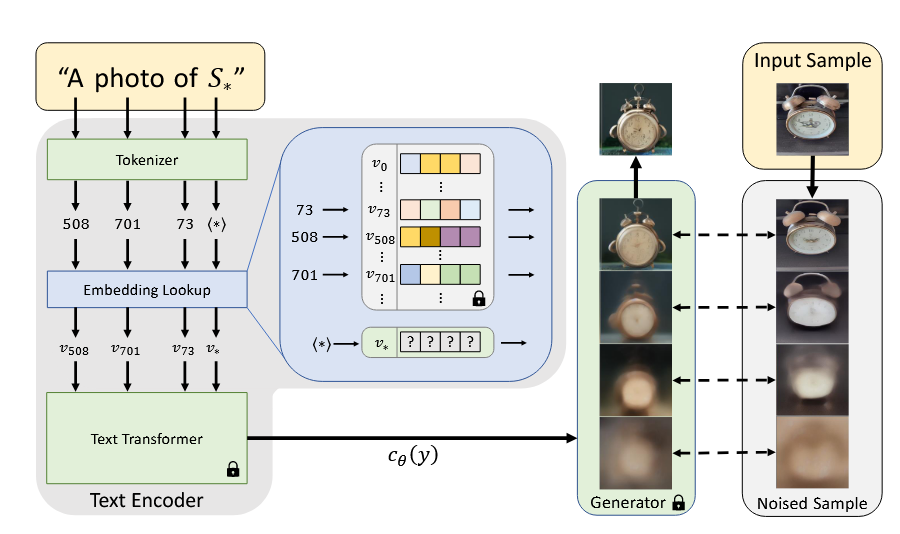
将placeholder的embedding vector设置为可学习的embedding(使用其coarse description的token进行初始化),将输入图片的prompt设置为”A photo of S*”,”A rendition of S*”等。然后使用LDM的reconstruction loss(去噪损失)对该embedding进行优化。(注意,该优化过程中,除了此可学习embedding,其他所有参数冻结)
DreamBooth
DreamBooth做的事情
给定3-5张某个主体的图片,通过微调T2I模型,使得模型能够生成该主体的图片,同时保持原有类别的生成能力。在单张A100上微调SD约需要5min。
DreamBooth的微调流程
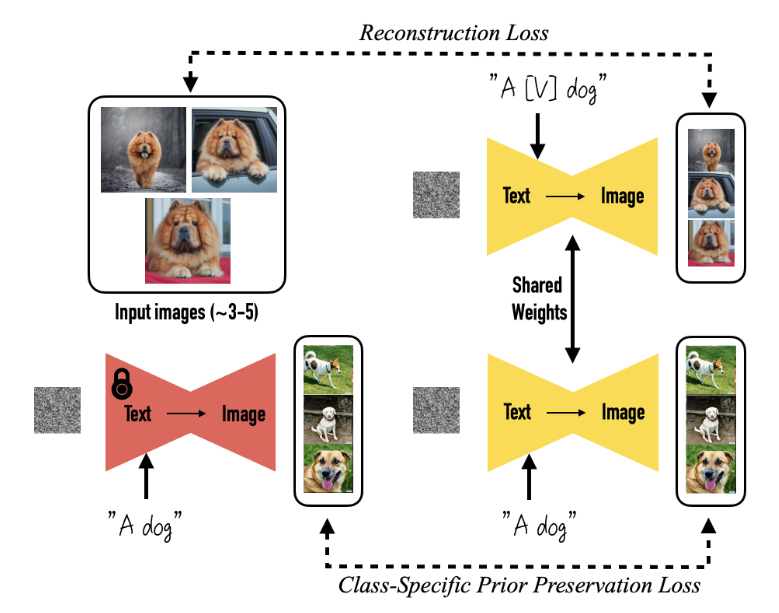
对于输入主体的照片,为其打上标签“a [identifier] [class noun]”,其中identifier是词汇表中的rare tokens,class是一个粗粒度的描述主体类别的词。
接下来微调SD的所有层(实际应用起来,同时微调文本编码器效果会更好),但是这样会造成language drift(忘记原来的类别如何生成),并且生成多样性降低。采取的办法是除了reconstruction loss之外,还使用了class-specific preservation loss。具体做法是:从原始SD中生成一些“A [class noun]”的样本,然后将这些sample加入训练数据来同时微调SD。通过这个loss可以避免few-shot微调之后忘记原本属于该class的信息。
Custom Diffusion
Custom Diffusion做的事情
给定4-5张主体图片,对模型进行较少参数的微调使得SD能够生成对应主体的图片。同时能够支持多主体的定制化生成。
Custom Diffusion对于单概念的微调

Custom Diffusion对于模型的微调有三个方面:
- 对于文本编码,会和Textual Inversion一样引入一个新token与对应的mebedding,同时在该token后加上通用类的名字。训练时,会同时优化这个embedding。
- 对于UNet部分,只微调每个Cross attention中的KV矩阵,这些参数量只占了整个UNet的5%。
- 对于language drift问题的解决,从LAION-400M中选取了与text prompt高相似度的图片,作为正则集(与DreamBooth类似)。
Custom Diffusion对于多概念的组合
- 联合训练。将两种概念的数据集直接进行联合训练。
- 合并优化。在已有两个单概念的模型之后,可以通过优化合成目标的方式,仅优化KV矩阵,得到优化之后的组合概念模型。
Custom Diffusion与Textual Inversion/DreamBooth的关系
- Custom Diffusion与Textual Inversion类似,会在文本嵌入中加入一个可学习的embedding。
- Custom Diffusion与DreamBooth类似,会有正则集来防止language drift,也会微调UNet。区别在于,Custom Diffusion只微调Cross attention中得KV矩阵,而DreamBooth微调所有;Custom Diffusion得正则集是直接选取得,而DreamBooth的是模型提前生成的。
BLIP-Diffusion
BLIP-Diffusion做的事情?
给定一张照片,无需finetune得到subject representation,然后用于Personalization;同时,也支持对subject进行few-shot的finetune。
BLIP-Diffusion的做法
使用了两阶段的预训练策略,第一阶段使得模型产生text-aligned image representation;第二阶段是subject representation learning的过程。
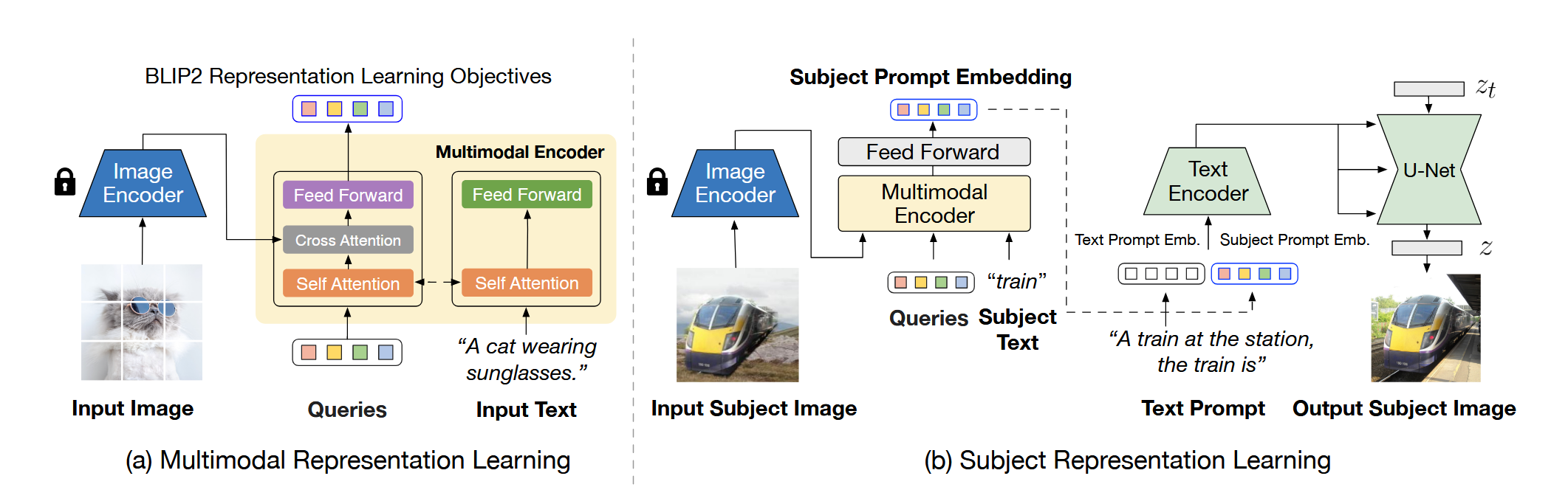
Stage 1:Multimodal Representation Learning with BLIP-2
第一阶段与BLIP2的预训练一样,使用多目标损失来训练Q-former,区别在于使用的可学习query个数只有16个。
Stage 2: Subject Representation Learning
将Q-former的结果经过FFN后,附加在text embedding的最后作为visual prompt。同时,使用的文本prompt template为”[text prompt] ,the [subject text] is [subject prompt]”
同时,为了将subject的学习与background的学习解耦,对于训练数据集的构建,是将图片中的subject保留,背景使用随机背景,然后将改变之后的图输入,原图作为目标。
训练时,冻结image encoder,然后同时训练Q-former、SD的text encoder和U-Net。
FastComposer
FastComposer做的事情?
给定一张照片,无需test time的微调,能够生成定制化的图片,同时保持一定的文本可编辑性。与Fine-tuning-based方法相比,速度更快且不需要额外存储。同时,FastComposer支持多主体的图像生成。
FastComposer提出的challenge
- 之前的Personalization方法大多基于微调,耗时。
- 多主体生成过程中的Identity Blending问题:当文本中出现多个个体的,他们的ID会因为Attention中注意到text的每个token而出现混杂。
- 在进行Personalization后,可能出现模型不遵循文本prompt的现象。
FastComposer中对Cross-attention的解释
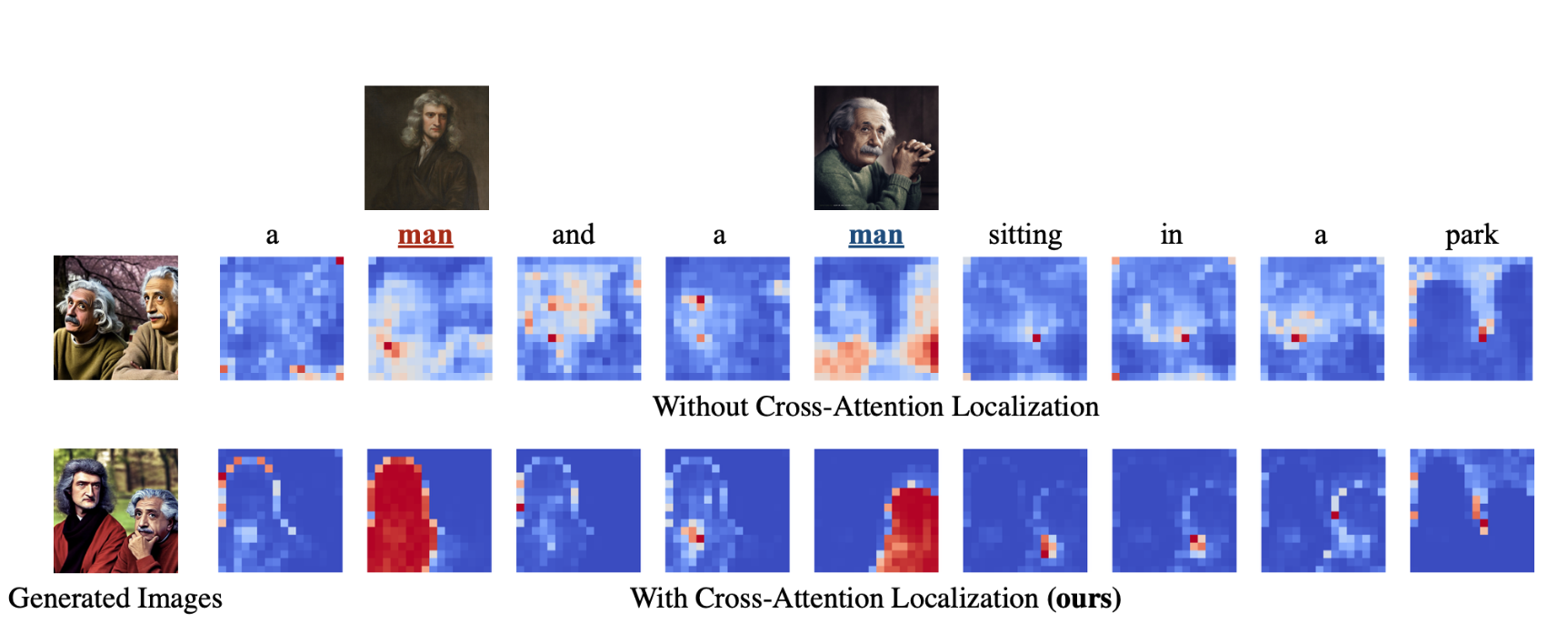
假设A为cross attention得到的Attention score(即softmax(qk)),则A[i,j,k]表示从k-th token到(i,j)位置的latent pixel的信息流。当某个像素更注意到某个token时,该值应该更大。
FastComposer的原理
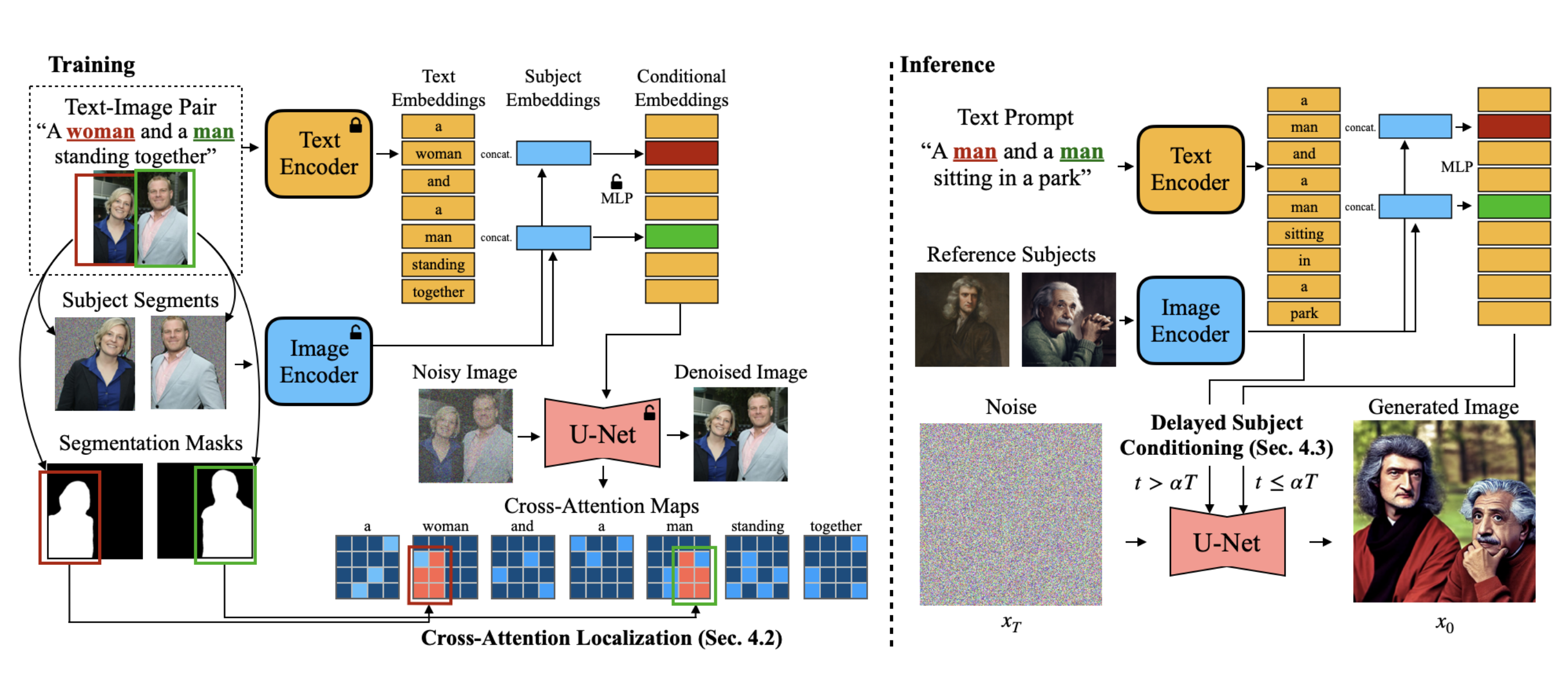
Tuning-Free Subject-Driven Image Generation
为了达到Tuning-free的目的,这里采用的是augmented的text embedding。
具体来说,给定文本Prompt,Reference Image,指定Subject在prompt中的token id,首先将文本和Reference Image分别过CLIP encoders。对于包含主体词的word embedding,将它的embedding和visual feature相连后输入给MLP,得到增强后的文本 embedding。
……………………………………..
训练时,使用denoising loss训练Image encoder的最后两层,MLP模块以及U-Net。
为了训练这一部分,作者创建了一个subject-augmented的图文对数据集,会将主体与对应文本的token对应。同时,训练的时候会将主体的背景使用随机噪声,防止模型对于主体背景的过拟合。
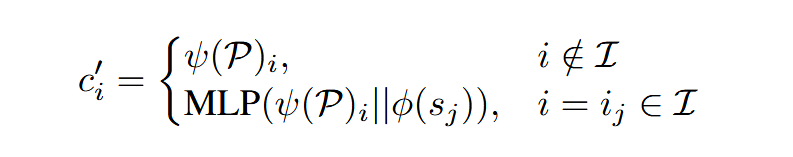
Localizing Cross-Attention Maps with Subject Segmentation Masks
作者认为,正确的Cross attention map,应该让对应主体的token在主体的instance seg mask处分数高,而不是散布在整张图片。因此,在训练的时候会在Cross attention这里加上一个Regularization项。该项只在训练时使用,推理时不使用。
……………………………………..
使用的方法是使用reference主体的seg mask来定位cross attention map。A_i=[:,:,i]表示第i个subject token的cross attention map,m_j表示第j个subject token。使用m_j来监督A_ij,使用Balanced L1 loss。最终,FastComposer的训练目标由denoising loss和localization loss组成。其中,localization loss只对Unet的中间5个block使用,因为它们包含更多的语义信息。
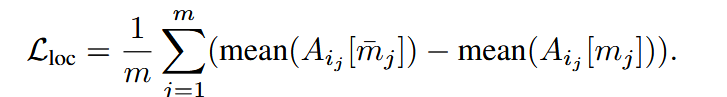
Delayed Subject Conditioning
直接使用augmented text representation可能导致图片很像subject但忽视文字引导。这是因为图片的layout是在去噪早期形成的,而一直的subject augmentation会导致模型忽视文本instruction。
…………………………………..
因此采用延迟主体条件,即只在去噪过程的后期使用augmented text embedding,而在前期layout形成过程中,只是用text-only prompt。这在identity preservation和editability间达到了平衡。其中c指原始的text embedding,c’指使用reference image增强过的text embedding。\alpha通常取[0.6,0.8]
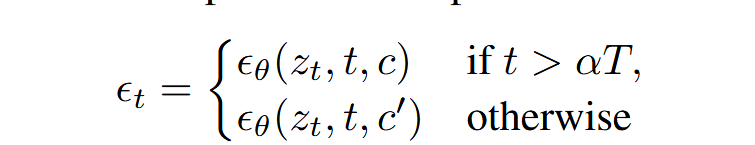
- FastComposer的流程。
训练过程:使用主体增强的图文对数据集。
- 文本prompt过Text encoder得到text embedding;每个Subject的图片部分过Image Encoder得到Subject image embedding。
- 将Subject embedding与对应token的embedding相连后过MLP得到增强后的text embedding。
- 过U-Net,且对中间5个block的cross attention map会使用Localazation loss监督。
- 对去噪后的图像使用denoising loss。
推理过程:用户输入主体referene照片,以及文本prompt(主体分先后顺序,使用man img来进行标记subject token)。
- 文本prompt过text encoder得到text embedding;图片过Image encoder得到Subject embedding。
- Subject embedding与Subject token embedding相连后过MLP得到增强的text embedding。
- 输入UNet进行去噪。
- 若使用Delayed Subject Conditioning,则去噪前期不增强text embedding,使用原始text embedding。
IP-Adapter
IP-Adapter做了什么事情?
IP(Image Prompt),即生成图片时使用图片作为prompt。IP-Adapter可以在冻结原模型的情况下,为模型注入Image prompt,使得生成图片拥有image prompt的内容和风格;并且同时能够保留text prompt的能力。模型轻量化,仅包含22M参数。同时,IP-Adapter也与其他adpater兼容,例如ControlNet。
在推理时,给定一张图片,不需要对模型进行test time微调,能生成与图片内容一致(但ID可能不一致)或者风格的图片。
IP-Adapter的模型结构
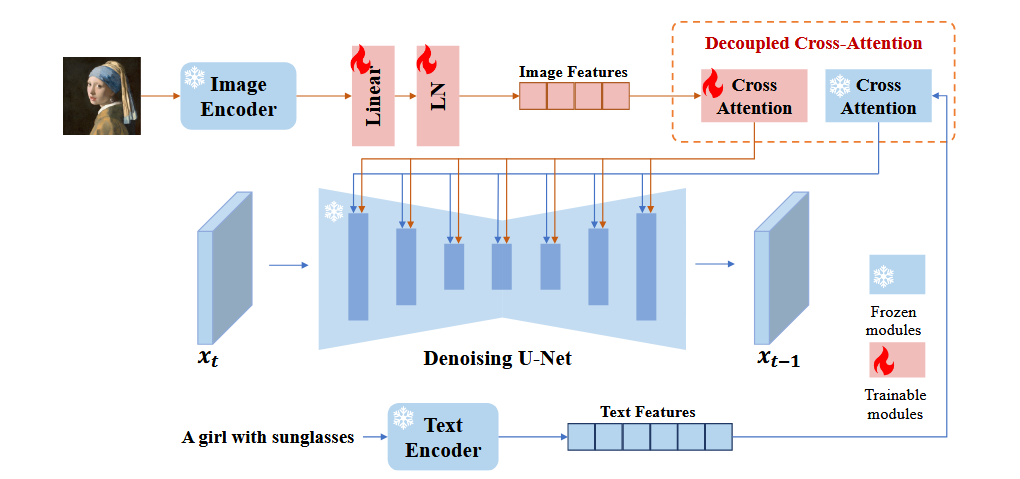
- 包含了一个冻结的CLIP image encoder,一个可训练的linear和LN,提取image promt的feature并将维度调整至与text feature的维度一样。
- 在SD的Unet的每个cross attention层都会额外添加一个cross attention。这个cross attention的query以及W_q都与text的cross attention一致,不同的部分是kv输入的image prompt,以及W_k,W_v也不同。因此在这一部分,可训练的参数是W_k,W_v。然后将image cross-attention和text cross-attention相加,继续传回Unet。
IP-Adapter的训练与推理
训练:训练数据使用了大规模图文对数据。可训练模块只有上面所述的模块(Linear,LN,UNet所有Cross attention中的KV矩阵),其中SD始终保持冻结。为了支持CFG,以0.05概率丢掉文本,以0.05概率同时丢掉文本和image prompt。
推理:在text cross-attention和image cross-attention相加时,可以以一定的权重加上image feature。当仅有image prompt时,权重设为1。使用50步的DDIM采样器,guidance scale设为7.5。
PhotoMaker
PhotoMaker做的事情
给定几张照片,在test time无需微调,生成高保真ID和具有可编辑性的图片。同时,还可以支持ID之间的混合。
PhotoMaker的做法
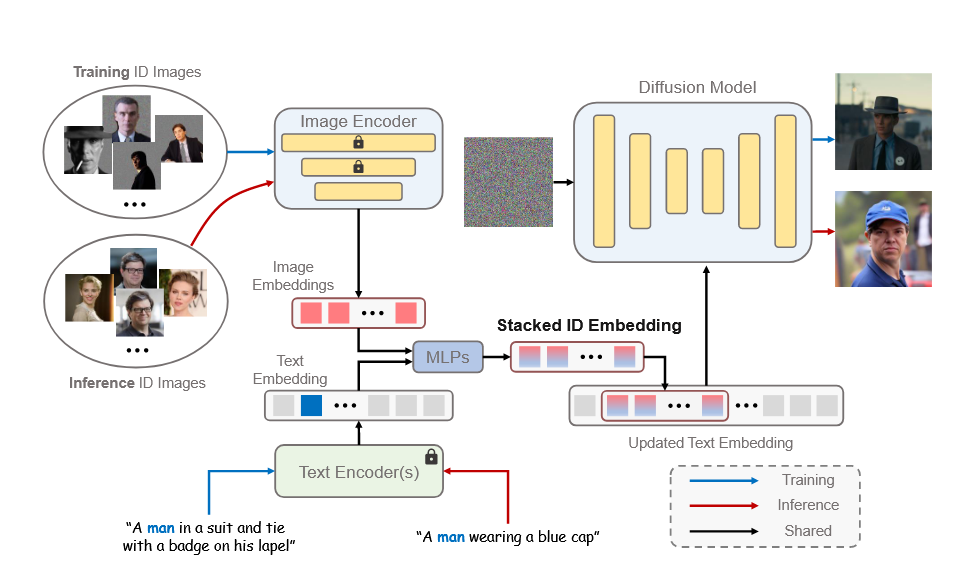
- Stacked ID Embedding
与FastComposer类似,会将背景加上噪声,减少噪声的影响。将每张图片过CLIP后过Porjection得到stacked ID embedding。这一过程中,可训练参数是CLIP encoder的最后几层以及Projection layer。使用Masked Diffusion loss。
- Stacking
将上面的stacked ID embedding与class word(man,woman)的word embedding过两层MLP得到fused embedding。然后将class word的embedding替换为fused embedding。(注意到这里会将ID embedding和word融合,因此可以用boy和man来生成不同age的)。
- Merging
为了达到更好的ID customization,会在每个cross attention层加上额外的LoRA权重。
PhotoMaker数据集的构建流程
- Image Downloading
- Face detection&Filtering
- ID Verification
- Cropping & Segmentation
- Captioning & Marking
InstantID
InstantID做的事情
给定一张照片,在test time无需微调,生成高保真ID和具有可编辑性的图片。同时,不需要训练SD的参数,这使得与其他模块如LoRA,ControlNet等兼容。
InstantID的做法
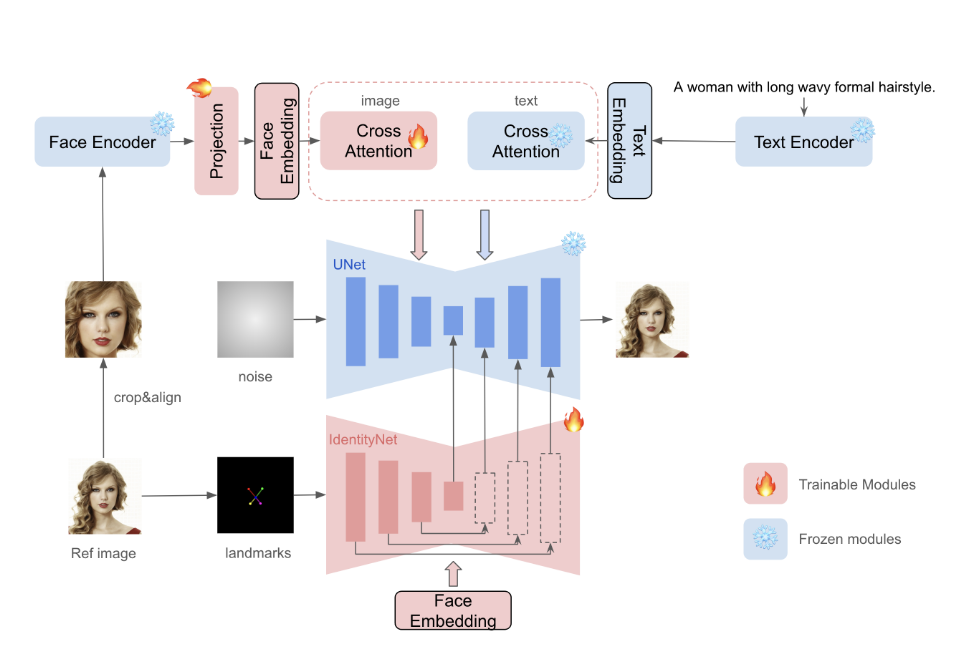
- ID Embedding:IP-Adapter等方法对于图像特征的提取使用CLIP,但这是比较广泛的语义信息,不适合人脸。因此这里使用Face Encoder来提取Face Embedding。
- Image Adapter:与IP-Adapter类似,会有一个decoupled cross attention,区别在于这里输入的是ID Embedding。
- IdentityNet:利用一个类似ControlNet的结构,输入Input是五个脸部的landmarks(可以使用landmarks控制生成脸部姿态),条件为ID embedding,给生成过程添加空间控制,可以达到高保真的目的。
综上,简单来说就是IP-Adapter+Face controlNet。
训练时,只训练Image Adapter、IndentityNet部分,其余部分冻结。使用的是denoising loss。
推理时,可以控制adapter和identitynet的强度(见IP-Adapter)。
StoryMaker
StoryMaker做的事情
给定一张单个主体或多个主体的照片,无需微调生成能够保持ID的图片,同时保持其衣服、发型的一致性。(Holistic consistency)
StoryMaker的做法
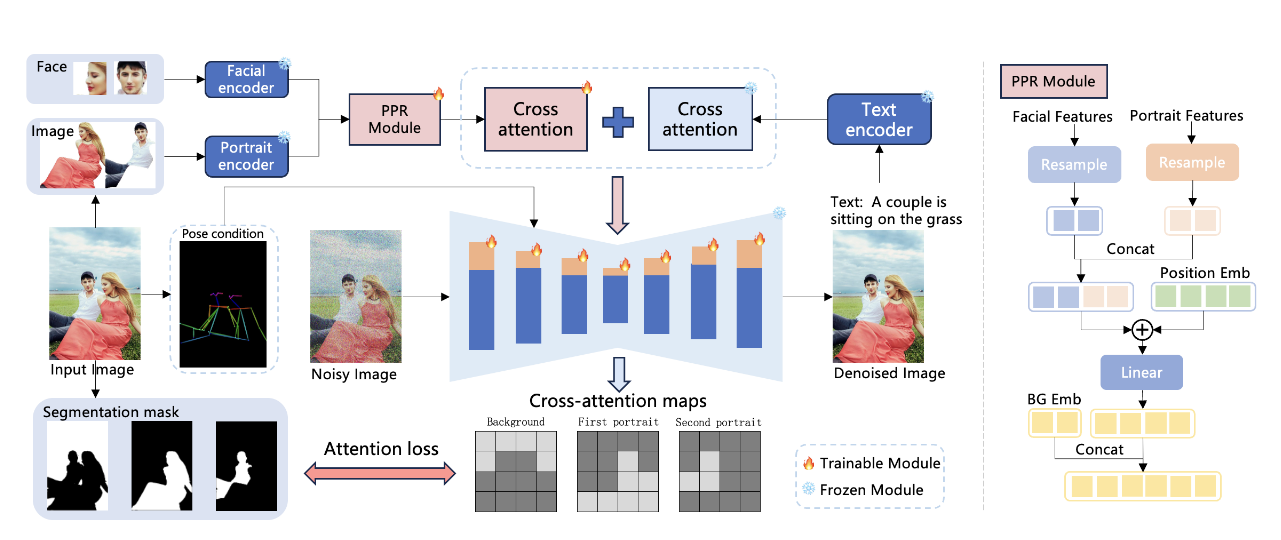
- Reference Extraction
对于输入的reference,会分为脸部和身体进行提取。
对于脸部,使用ArcFace检测脸部并提取facial embeddings。对于衣服、头发等,将characeter切割出来,然后使用CLIP vision encoder进行特征提取。
- Reference Information Refinement by Positional-aware Perceiver Resampler
对于两部分feature,会分别有两个resampler进行特征变换(即Linear+LN)。其中脸部的resampler使用IP-Adapter-FaceID初始化,身体的使用IP-Adapter初始化。
之后将两部分concat并使用Position ebedding,以区分不同的characters。同时,为了区分背景,会引入一个可学习的background embedding,concatt到最终的embedding上。具体见图上。
- Decoupled Cross-attention
与IP-Adapter一样,会使用decoupled cross-attention将feature注入到Unet中。
- Traing with LoRA
为了增强ID的一致性、保真性和质量,和IP-Adapter-FaceID一样,在每个cross attention层会加上额外的LoRA权重进行训练。
- Pose Decoupling from Character Images
单独在character图片上训练可能导致网络过拟合到reference的pose。因此将pose从图片中解耦,在训练时候使用Pose-Controlnet,将图片的pose作为条件输入。推理时,可以使用controlnet,也可以不使用。
- Loss Constraints on Cross-attention Maps with Masks
为了防止多个主体和背景之间交错现象,使用mask来对cross attention map进行正则化(与FastComposer类似)。这里的做法是对每个主体以及background分别计算cross-attention map loss。(来自Break-a-scene的cross-attention loss)
最终训练的loss是denoising loss和Cross attention map loss。
