SD 1.x
SD中的VAE。
重构损失:L1 loss,Perceptual loss,对抗损失:Patch-based GAN loss,正则化:KL loss.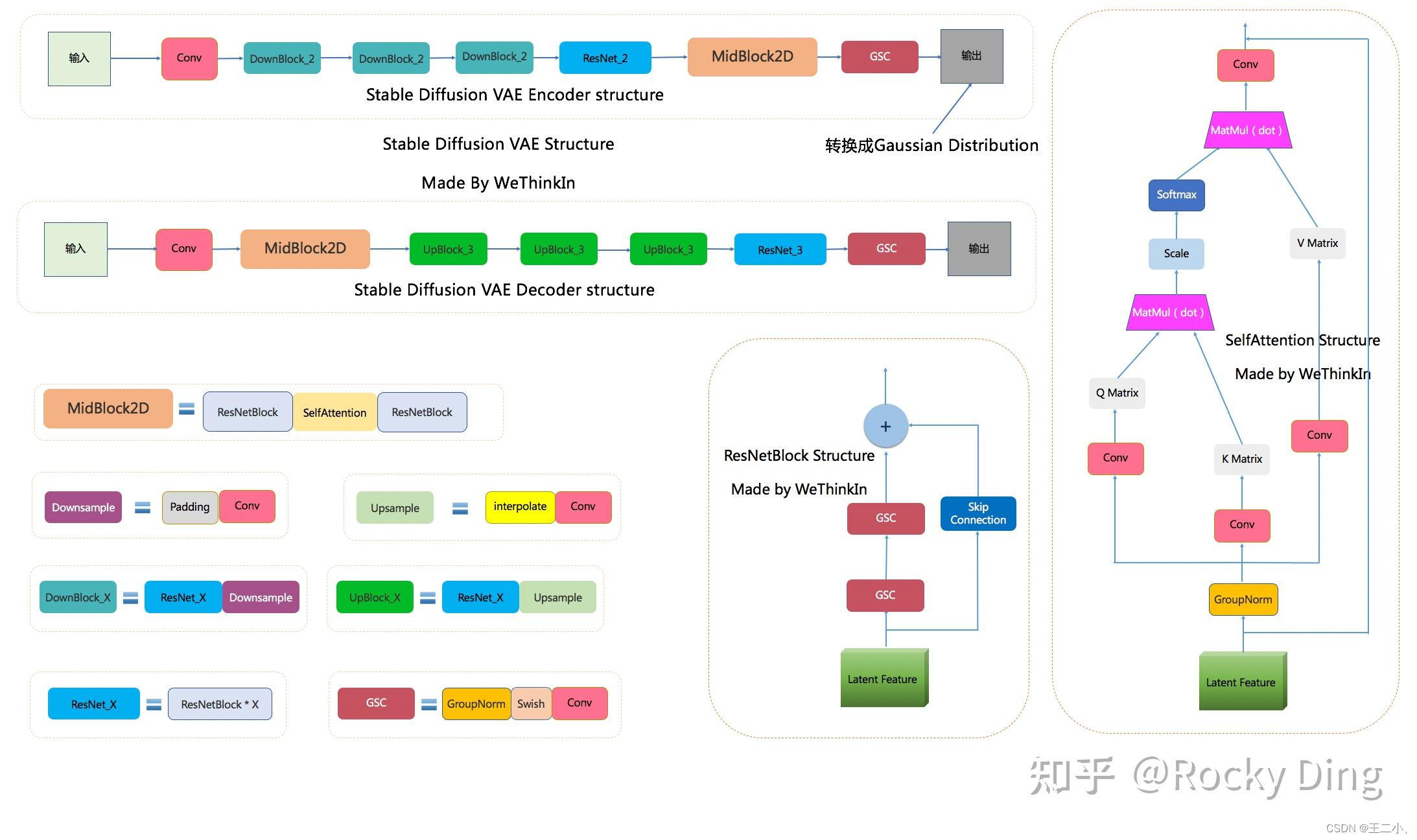
为了避免latent太过无序,使用正则项对latent space进行规范。原文中使用了两种:(1)KL-reg,但权重设置得很小(过强的正则化会导致生成的图像模糊);(2)VQ-reg,使用很大的codebook。
SD中的VAE不具有生成功能,主要起的是压缩作用。
H * W * 3 –> H/8 * W/8 * 4
SD中VAE与普通VAE的区别
这里的KL只是起了规范latent的作用。而且原文中设置的KL设置的极小。(ELBO中过强的正则化会导致生成的图像模糊)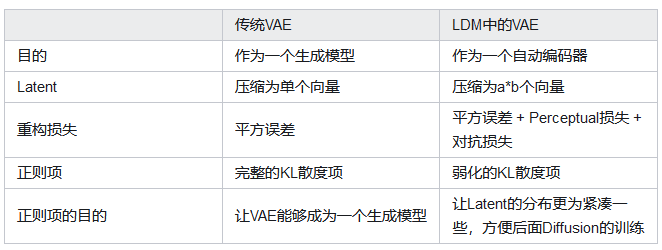
SD中scale_factor的作用
虽然VAE模型使用了KL正则化,但是由于KL正则化的权重系数非常小,实际生成的Latent特征的标准差依旧存在比较大的情况,因此使用一种rescaling方法强化正则效果。在VAE得到latent之后,需要将latent乘上一个scaling_factor,再送入Unet。这个的作用是:不同Autoencoder训练得到的latent space可能不同,使用scaling_factor将其归一到Unit Variance上,这对于UNet的学习有好处。解码时,将Unet去噪得到的latent除以该scaling_factor。
scaling_factor的计算,是使用数据集中第一个batch数据中Latent特征的标准差。
1 | # encode and decode the image latents with vae |
- SD的U-Net结构及与DDPM中U-Net的区别。其中时间步t在ResBlock中过线性层后与x相加;文本c在SpatialTransformer的cross attention中与flatten的x交互。Unet中的连接方式是直接concat。
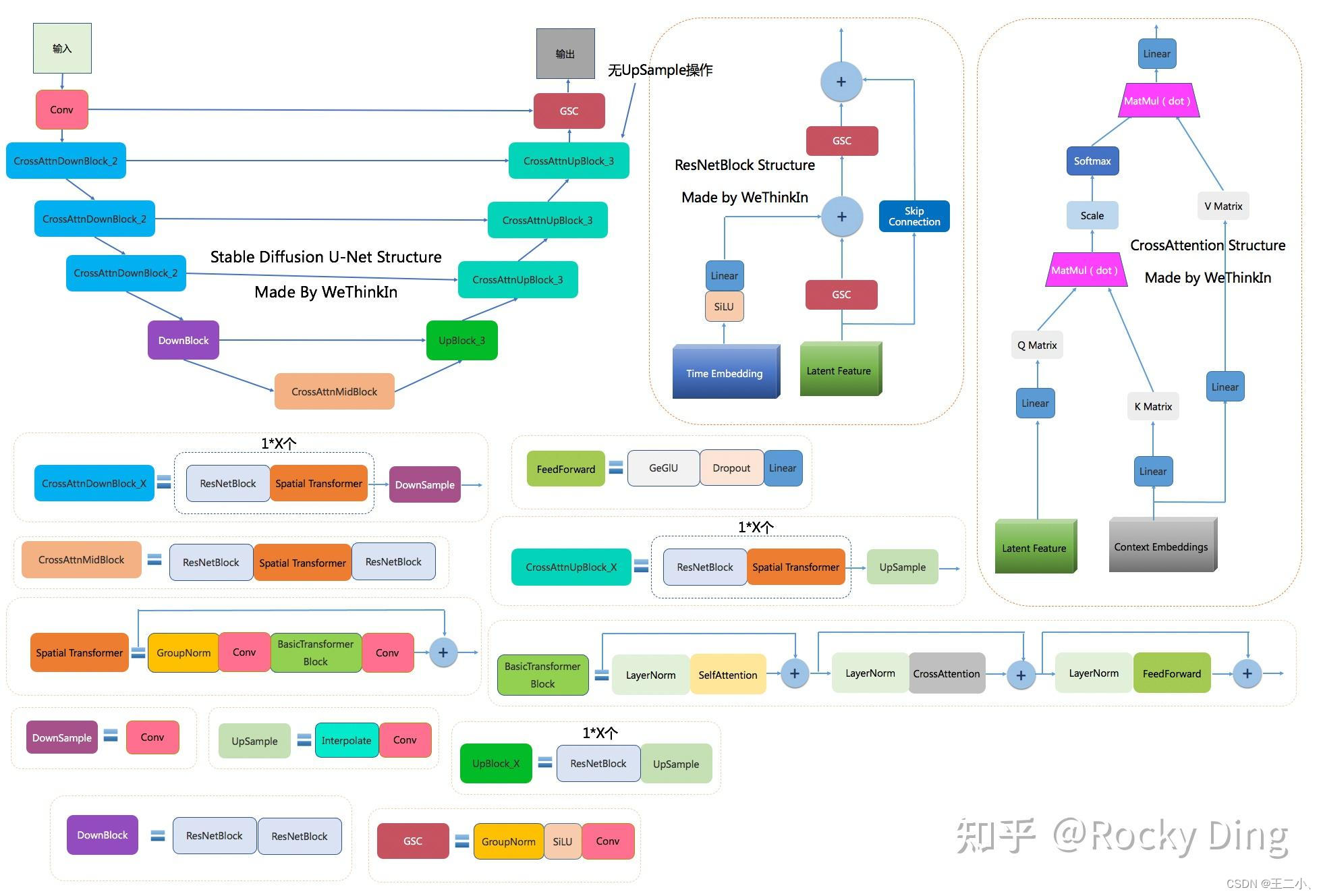
区别:(1)DDPM中是自注意力模块,而SD中替换成Transformer block。
(2) DDPM中自注意力仅在较深的几层,而SD中每个层都有Transformer block。
SD的训练过程
训练:首先预训练Autoencoder,然后训练LDM(LDM恢复的是latent)。
SD的生成结果评估指标
IS(Inception Score):用分类模型评测样本集的“类别确定性”和“类别多样性”,越大越好。用了一个图像分类网络来评估生成图片的质量。这个分类网络是在 ImageNet 数据集上训的,一共有1000类。
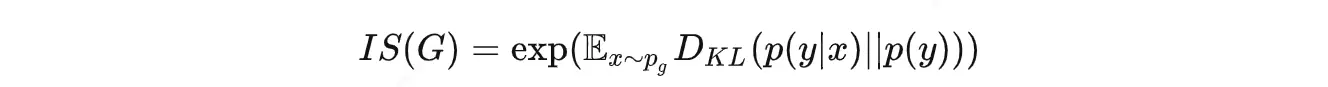
- 清晰度上:把一张生成的图像喂给分类模型,让模型输出最后一层的1000维向量,如果图像更清晰,那么分类的置信度会很高,其中的某个值会更接近1,其他值更接近0,这个1000维向量的熵就会更低。
- 多样性上:生成5000张图片给分类模型去分类,如果图像更多样,那么分出来的类型会更均匀,总体接近均匀分布,熵更高。
IS指标就是在计算这两个熵的KL散度(可以简单理解为一种距离),图像越清晰、多样性约高,前一个熵越低,后一个熵越高,KL散度越大,所以 IS 指标越大表示生成的效果越好。
缺点: 评测方式的前提是,图像生成所用的训练图片必须得是与分类模型训练数据相同,否则这种评测方式就是有问题的。
FID(Fréchet Inception Distance):用两个分布的期望和方差,计算两个分布的距离,越小越好。
- 用一个去掉分类头的分类模型推理出生成图像和真实图像的特征层(一般是2048维).
- 假设两个数据的特征层都服从正态分布
- 用上面这个公式计算两个分布的均值和协方差的“距离”
缺点:没法衡量是否过拟合的问题。
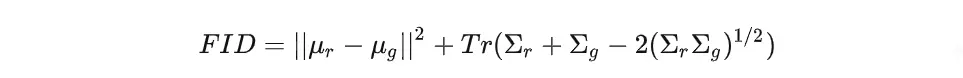
CLIP score:计算prompt与生成图片的cos相似度。用于评测遵守prompt的程度。
R-precision:对提取的图像和文本特征之间的检索结果进行排序,来衡量文本描述和生成的图像之间的视觉语义相似性。
SD 2.x
- SD 2.x与SD 1.x最主要区别
Text Encoder时使用了更大的CLIP ViT-H/14,且使用倒数第二层的特征(SD 1.x使用的是倒数第一层)
SD 2.x使用了v-prediction,见下图
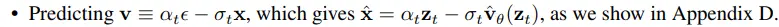
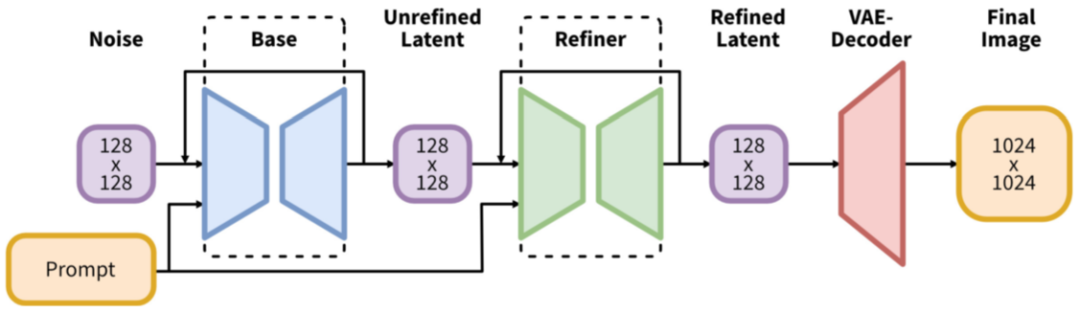
SD-XL
SD-XL与SD 1.x的区别
增加一个 Refiner 模型,用于对图像进一步地精细化。分辨率可以达到1024x1024。
SDXL-Base使用 CLIP ViT-L 和 OpenCLIP ViT-bigG 两个 text encoder,将两个encoder的倒数第二成embedding相连起来作为text embedding。
训练方式上:(1)以图像大小作为条件。提出将原始图像分辨率作用于 U-Net 模型,并提供图像的原始长和宽(csize = (h, w))作为附加条件。 (2) 以裁剪参数作为条件。将裁剪的左上坐标(top, left)作为条件输入模型,和 size 类似。(3)基于多尺度分辨率训练。
SD-XL-turbo的改进
引入蒸馏技术,以便减少 LDM 的生成步数,提升生成速度。