





DALL-E 1
- DALL-E 1的模型架构
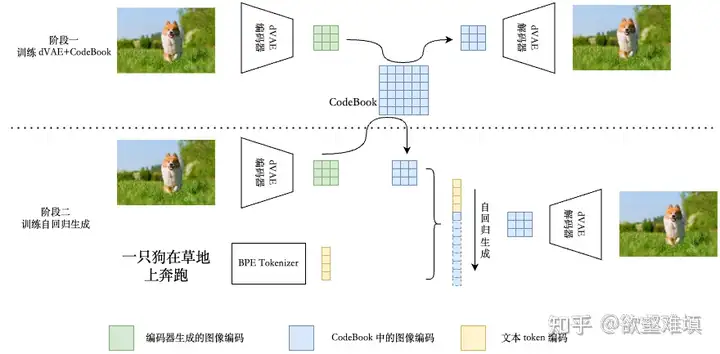
第一阶段,训练一个VQVAE。第二阶段,训练一个自回归的prior模型,这里用的是decoder-only的Transformer(与VQGAN很像,但是这里将文本作为prefix预置条件,实现了Text-conditional生成)
DALL-E 2(unCLIP)
DALL-E 2的模型结构
共由三部分组成,预训练的CLIP,prior模型,decoder模型。之所以叫unCLIP,是因为这里是和CLIP反过来的,将Image embedding还原成图片。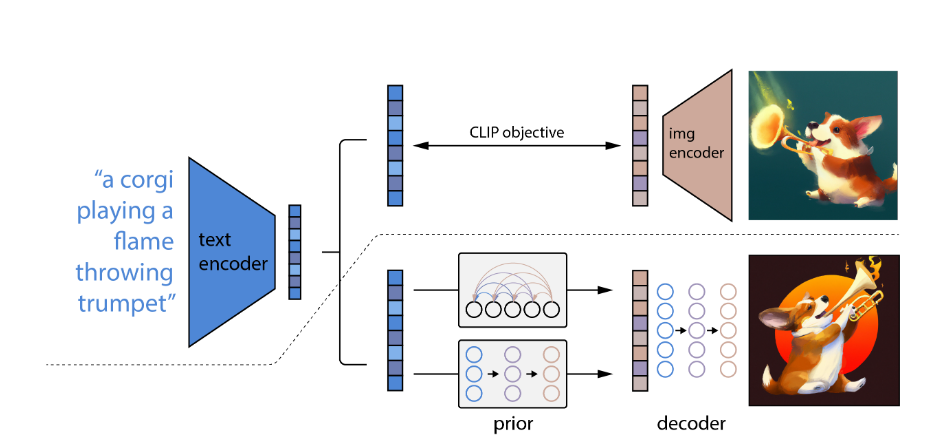
DALL-E 2训练过程
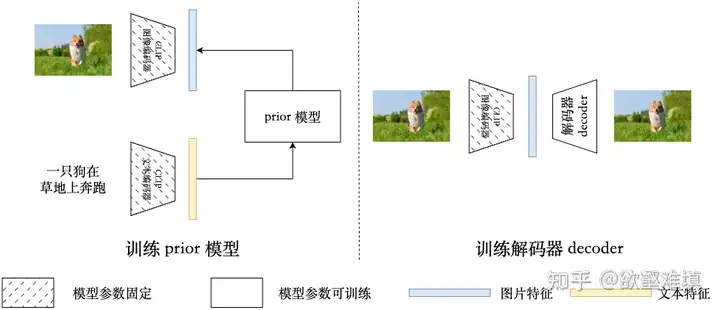
- 在图文对上预训练CLIP模型,之后一直是冻结的。
- 训练Prior模型,由文本embedding还原得到对应的图片embedding。实现上使用了两种结构:(1)自回归Prior。(2)扩散模型prior。最终选用了扩散模型Prior。
- 训练Decoder模型,由CLIP图片embedding解码为真实的图片(因此叫unCLIP)。生成分辨率为64*64,为了生成高清大图,还训练了两个扩散模型的超分模型,上采样到 256 * 256和1024 * 1024.
DALL-E 3
- DALL-E 3主要贡献
对图文数据集recaptioning,即训练一个 captioner 模型,来为图片生成更完整的文本描述。用这种合成的(synthetic)图像文本对数据集,来训练文生图模型,prompt following 能力显著提升。