





DiT
DiT的主要结构
DiT是从LDM改进而来的,将LDM中的U-Net替换为Transformer,VAE仍然使用Stable Diffusion的。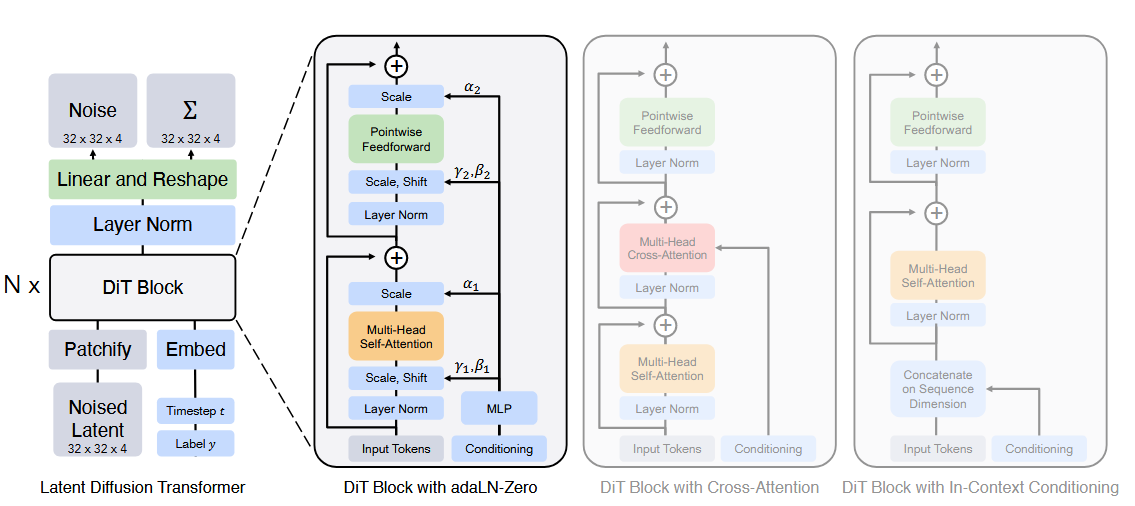
最后一个DiT block之后,将tokens decode为output noise prediction和covariance prediction。
DiT的Patchify过程
与ViT的一样,使用卷积将压缩后的z切分成一个一个的token,并嵌入位置信息。
DiT的不同条件注入机制
- In-context conditioning:将去噪时间步和条件c作为额外两个token附在输入序列前;最后一个block之后再将它们移除。
- Cross-attnetion:将去噪时间步和条件c连接成一个长度为2的序列,在原始transformer block中插入cross attention并注入条件。
- adaLN:将原始layerNorm替换为adaLN,即从t和c中回归得到scale和shift。
- adaLN-Zero:将每个ResBlock初始化为identity function。同时除了回归scale和shift外,同时在每个Residual connection前回归dimension-wise scale的参数。
AdaLN的实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class AdaLayerNorm(nn.Module):
def __init__(self, embedding_dim: int, num_embeddings: int):
super().__init__()
self.emb = nn.Embedding(num_embeddings, embedding_dim)
self.silu = nn.SiLU()
self.linear = nn.Linear(embedding_dim, embedding_dim * 2)
self.norm = nn.LayerNorm(embedding_dim, elementwise_affine=False)
def forward(self, x: torch.Tensor, timestep: torch.Tensor) -> torch.Tensor:
emb = self.linear(self.silu(self.emb(timestep)))
scale, shift = torch.chunk(emb, 2)
x = self.norm(x) * (1 + scale) + shift # 用 timestep 进行 affine
return x