





VAE
VAE
VAE模型
VAE公式推导
见知乎文章。
KL项的作用
KL loss类似于一个正则项,用于规范latent的范围,这也是与AE的最大区别。
VQ-VAE
VQ-VAE模型结构
前向时,Encoder出来的latent会与codebook中的code做最近邻,直接使用codebook中的code作为latent。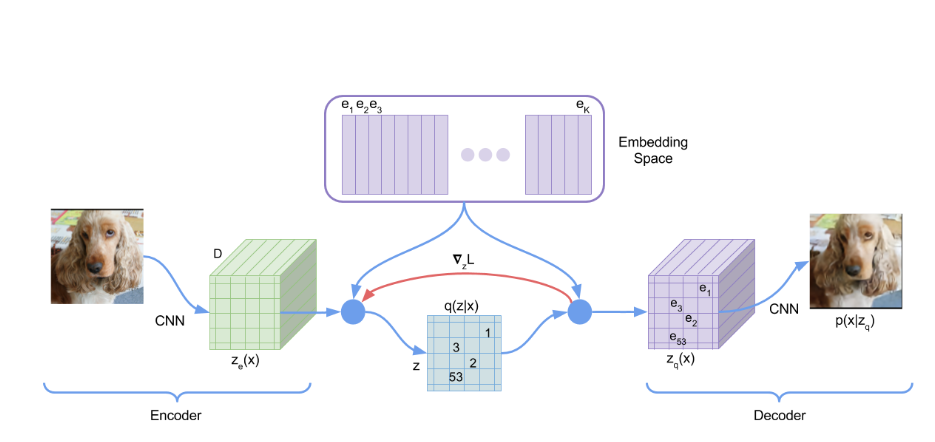
VQ-VAE实质上是AE,用来将图像进行压缩。如果要做到图像生成,可以使用PixelCNN来拟合离散的分布。(原文中做法)
VQ-VAE的优化目标
有三部分组成:reconstruction loss,VQ loss, commitment loss。
Reconstruction loss: 反向过程,encoder无法得到反传的梯度,这里采取的方法是将decoder的梯度复制到encoder。具体实现如下图。
即 L = x - decoder(z_e+(z_q-z_e).detach())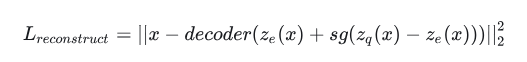
VQ loss:为了学习codebook,将codebook中的code与encoder的输出拉近。这一部分不反传给encoder。可以使用EMA算法实现。
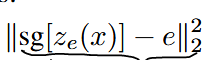
Commitment loss:Encoder和codebook的学习速度不同,为了不让encoder的输出偏离codebook太多,使用了commitment loss。这一部分不反传给codebook。
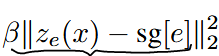
Encoder由Reconstruction loss和commitment loss优化,Decoder由Reconstruction loss优化,Codebook由VQ loss优化。
- VAE与VQ-VAE的区别
VAE是假设latent分布为高斯分布;VQ-VAE则是假设latent分布为类别分布。
GAN
GAN
GAN模型结构
生成器G,判别器D,先验分布Z(可以采用高斯噪声)。

GAN的损失函数
首先考虑判别器D,这是一个二分类问题,那么其损失函数为:
再考虑生成器G。G是要与D唱反调,那么G的目标就是最小化-L_D,即: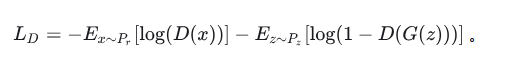 最终形成的损失函数,是如下的形式:
最终形成的损失函数,是如下的形式: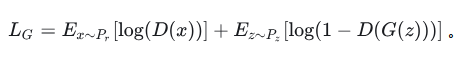 改进的版本如下:
改进的版本如下: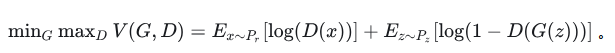 该损失函数可以证明其收敛性。(如果D对于所有的G都能够迅速变化为最优判别器,那么生成器G实际上是在最小化真实数据分布P_r与伪造数据分布P_f之间的JS散度)
该损失函数可以证明其收敛性。(如果D对于所有的G都能够迅速变化为最优判别器,那么生成器G实际上是在最小化真实数据分布P_r与伪造数据分布P_f之间的JS散度)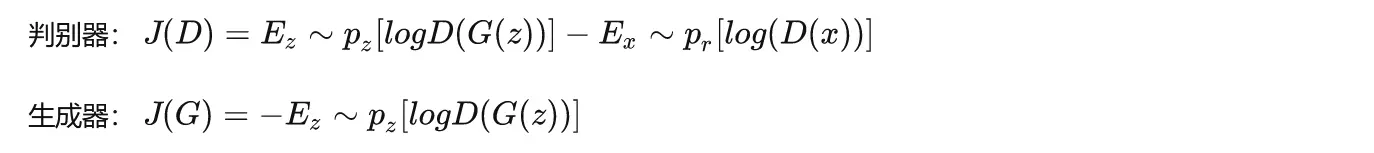
GAN的训练流程
每一轮更新中,(1)固定G,更新D;(2)固定D,更新G。

GAN的问题
- Mode collapse:生成器生成的图像都特别像。可能是数据集过小导致过拟合。
- Diminished gradient:判别器太强,导致gradients vanish使得生成器学不到新东西。
- 不收敛、经常过拟合、对超参数敏感。
WGAN与GAN的区别
除此之外还需要做梯度裁剪。
VQ-GAN
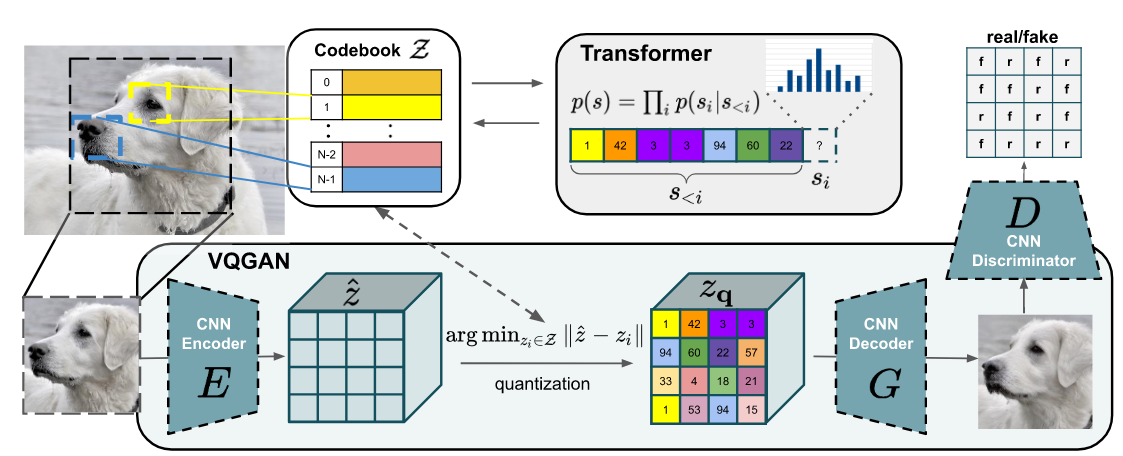
VQ-GAN与VQ-VAE的区别
- 将VQ-VAE中的先验生成器从PixelCNN改成了Transformer。
- 重建损失中将L2 loss换成了Perceptual loss。
- 在训练过程中使用PatchGAN的判别器加入对抗损失。
VQ-GAN的GAN部分训练过程
这一部分学习训练CNN Encoder,CNN Decoder和Codebook。
对于VQ部分,与VQ-VAE类似。将图片H* W* 3经过卷积后得到h* w* n的feature,与codebook进行最近邻后得到新的latent。这里将重建的L2 loss换成了Perceptual loss。
判别器使用了PatchGAN,这部分的loss为: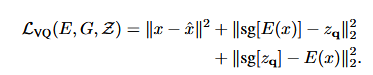 最后的优化目标为:
最后的优化目标为: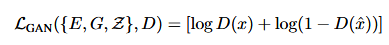
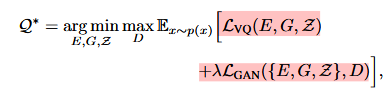
Perceptual loss是什么?

VQ-GAN的Transformer部分
这一部分训练Transformer作为先验分布来自回归地生成图像code,然后送给decoder得到生成的图像。训练过程与GPT训练过程类似,做Next-word-prediction;同时这里还进行了mask,所以不是传统的GPT训练方法。
Classifier Guidance
Classifier Guidance的推导

分类器是需要预训练的,训练数据和扩散模型的训练数据一致,且由于分类过程贯穿整个采样(i.e. t从T到0),因此分类器的训练数据还需要加上不同程度的噪音,来使得该分类器在噪音图片下依然可以起到引导作用。
s是一个大于1的系数。当s较大时,会更关注分类器,生成样本更符合y,但多样性更低,因此是一个保真度与多样性之间的trade-off。
DDPM中Classifier Guidance采样过程

DDIM中Classifier Guidance采样过程

Classifier Guidance的优点和缺点
优点: 不需要重新训练扩散模型,只需要在采样时根据分类器梯度修改采样的均值即可。
缺点:推理时每一步需要过分类器,速度较慢。
Classifier-free Guidance
CFG的推导

CFG的训练过程
训练时,Classifier-Free Guidance需要训练两个模型,一个是无条件生成模型,另一个是条件生成模型。但这两个模型可以用同一个模型表示,训练时只需要以一定概率将条件置空即可。
CFG的推理过程
推理时,需要同时得到cond和uncond的推理结果,按照上述公式对预测噪声进行线性外推。
其中,uncond也可以用negative prompt代替,这样可以实现不生成某些内容。
为什么需要两次推理分别得到cond和uncond?
通过线性外推方式,获得更多的生成多样性。
CFG的guidance_scale的作用
一般取7.5。guidance scale越大,生成的结果越倾向于输入条件,图像质量更高,多样性会下降;越小,多样性越大。
相比于Classifier Guidance的优点
- 不需要额外训练分类器。
- 更加灵活,因为它不依赖于特定的分类器,可以处理更广泛的条件。
- 采样时效率更高。
DPM,DPM++