





训练显存
FP32,FP16,BF16
FP32:1位符号,8位指数,23位尾数。
FP16:1位符号,5位指数,10位尾数。
BF16:1位符号,8位指数,7位尾数。BF16提供了与FP32相同的动态范围,但精度低于FP32和FP16。如何计算训练大模型需要的显存?
- 模型参数:如果模型有P个参数,使用FP32保存的话,需要4P字节的显存。
- 梯度:大小与模型参数相同。使用FP32保存的话,需要4P字节的显存。
- 优化器状态:Adam需要保存参数的一阶和二阶矩估计。因此显存翻倍,使用FP32保存的话,需要4P*2=8P字节的显存。
- 激活和中间变量:前向传播和反向传播过程中的激活值和中间变量也需要存储,这与批量大小(batch size)和序列长度有关。这些是动态的显存。
解决训练显存不够的几种办法。
- 减小batchsize。通过减小中间激活值来减少显存占用量。
- 使用混合精度训练。
- 梯度累积(Gradient accumulation):在多个小批次(mini-batches)上累积梯度,然后一次性更新模型参数。这样可以在不增加显存消耗的情况下,模拟更大的批次大小,从而提高训练速度和模型性能(可以证明与大batchsize训练效果完全等价:只需要将每次计算出的loss除以一个accumulation step,就能保证最后的梯度一致)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14optimizer.zero_grad()
for i, (inputs, labels) in enumerate(zip(mini_batches, mini_targets)):
outputs = model(inputs)
loss = criterion(outputs, labels)
loss = loss / accumulation_steps
# 反向传播,累积梯度
loss.backward()
# 每 accumulation_steps 步进行一次参数更新
if (i + 1) % accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad() - 梯度检查点(Gradient checkpointing):在反向传播时重新计算中间层的激活值,而不是在整个训练过程中都保持它们。这样可以大大减少显存占用,但可能会增加一些计算成本。(前向传播过程中,以torch.no_grad()方式运行,不保存中间激活;反向时,检索保证的输入和函数,然后计算梯度)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import torch
import torch.nn as nn
import torch.utils.checkpoint as checkpoint
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.layer1 = nn.Linear(100, 200)
self.layer2 = nn.Linear(200, 200)
self.layer3 = nn.Linear(200, 100)
def forward(self, x):
x = checkpoint.checkpoint(self.layer1, x) # 在第一层使用梯度检查点
x = checkpoint.checkpoint(self.layer2, x) # 在第二层使用梯度检查点
x = self.layer3(x) # 第三层不使用梯度检查点
return x- Parameter Efficient Finetuning。
- ZeRO-Offload:将未使用的数据暂时卸载到CPU或不同的设备中,然后在需要时再将其读回,参数动态地从 GPU -> CPU, CPU -> GPU 进行转移,从而节省 GPU 内存。这个想法的一个具体实现是ZeRO,它将参数、梯度和优化器状态分割到所有可用的硬件上,并根据实际需要再将它们具体化。
混合精度训练
使用混合精度训练,内存占用更少,计算更快(不少GPU都有对fp16计算的优化)。
FP16存在的问题:
- 数据溢出:容易上溢或者下溢。
- 舍入误差。
解决办法:
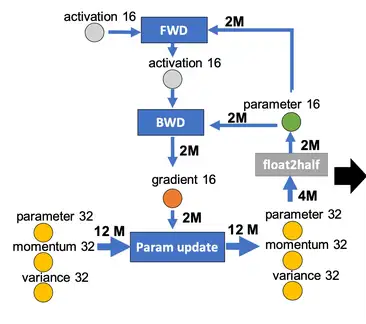
FP32权重备份:用于解决舍入误差。weights, activations, gradients 等数据在训练中都利用FP16来存储,同时拷贝一份FP32的weights,用于更新。
这主要是因为,权重=旧权重+lr*梯度,而lr * 梯度往往很小,使用fp16相加会有舍入误差。,在训练过程中,内存中占据大部分的基本都是 activations 的值(动态内存)。特别是在batchsize 很大的情况下, activations 更是特别占据空间(一般为静态内存的3-4倍),因此使用fp16可以大大减少显存占用。Loss Scale:主要为了解决fp16下溢的问题。训练到了后期,梯度会特别小(特别是激活函数饱和段的梯度),fp16会产生下溢现象。
对计算出来的loss进行scale,由于链式法则的存在,loss上的scale也会作用到梯度上。这样,scaled-gradient 就可以一直使用 fp16 进行存储了。只有在进行更新的时候,才会将 scaled-gradient 转化为 fp32,同时将scale抹去。精度累加:主要是为了减少加法过程中的舍入误差,保证精度不损失。在某些模型中,fp16矩阵乘法的过程中,需要利用 fp32 来进行矩阵乘法中间的累加(accumulated),然后再将 fp32 的值转化为 fp16 进行存储。即利用fp16进行乘法和存储,利用fp32来进行加法计算。
具体步骤:
- 维护一个 FP32 数值精度模型的副本
- 在每个iteration
- 拷贝并且转换成 FP16 模型
- 前向传播(FP16 的模型参数),此时 weights, activations 都是 FP16
- loss 乘 scale factor s
- 反向传播(FP16 的模型参数和参数梯度), 此时 gradients 也是 FP16
- 参数梯度乘 1/s
- 利用 FP16 的梯度更新 FP32 的模型参数
1 | # Pytorch中amp(automatic mixed precision)示例 |
并行训练
数据并行
数据并行原理
模型一台设备装得下,所以同一个模型同时用多份数据分开来训练。
同一个batch的数据分成多个部分,每个部分分配到一个设备上,每台设备上持有一个完整的模型副本。每台设备在分配的数据上进行训练;在反向传播后,模型的梯度将会进行聚合(All reduce),以便在不同设备上的模型参数保持同步。
主要方案:Ring All-reduce(无master节点)和Parameter server(有master节点)。Ring All-reduce是以环形的方式传递梯度,减小时延;Parameter server则是有一个master节点和多个worker节点。
Pytorch中DP的原理
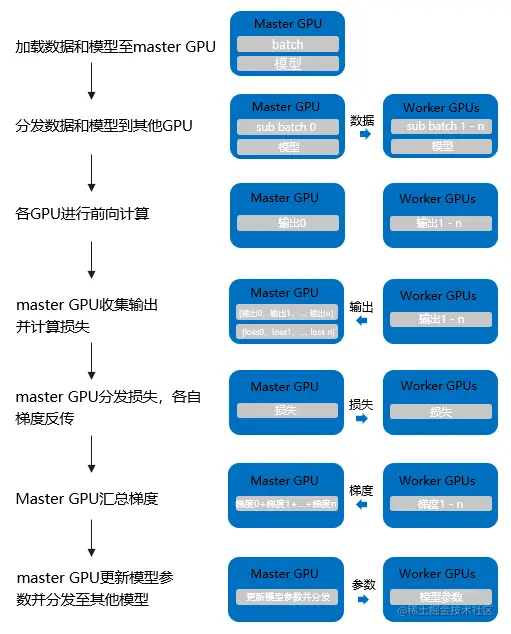
采用的是parameter server模式。
缺点:
- DP使用单进程多线程实现,但受困于GIL,会带来性能开销,速度很慢。
- 主卡性能和通信开销容易成为瓶颈,GPU 利用率通常很低。(主卡占用多,其他卡占用少)
- 不支持模型并行。
Pytorch中DDP的原理
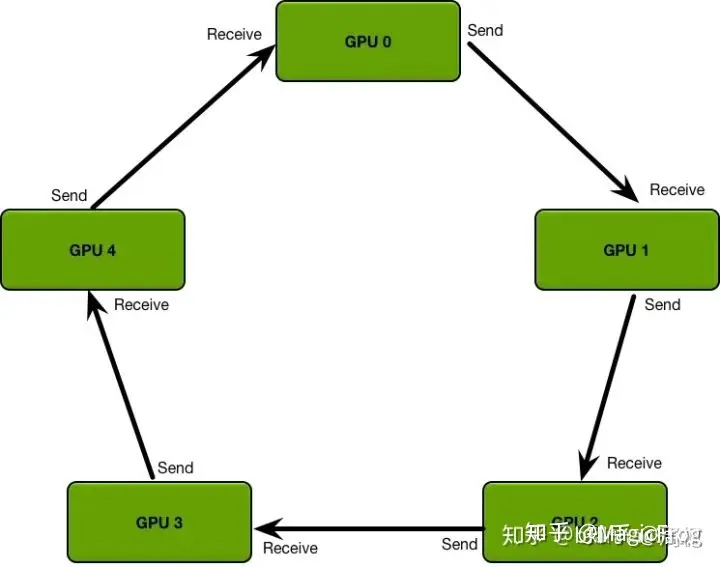
基于多进程实现,每个进程都有独立的优化器,执行自己的更新过程。每个进程都执行相同的任务,并且每个进程都与所有其他进程通信。进程(GPU)之间只传递梯度,这样网络通信就不再是瓶颈。
- 首先将 rank=0 进程中的模型参数广播到进程组中的其他进程
- 每个 DDP 进程都会创建一个 local Reducer 来负责梯度同步
- 训练过程中,每个进程从磁盘加载 batch 数据,并将它们传递到其 GPU。每个 GPU 都有自己的前向过程,完成前向传播后,梯度在各个 GPUs 间进行 Ring All-Reduce,每个 GPU 都收到其他 GPU 的梯度,从而可以独自进行反向传播和参数更新。
- 同时,每一层的梯度不依赖于前一层,所以梯度的 All-Reduce 和后向过程同时计算,以进一步缓解网络瓶颈。
DP与DDP的区别
- DP是基于单进程多线程实现,只用于单机;DDP是多进程实现的,并且因为每个进程都是独立的Python的解释器,避免了GIL带来的性能开销。
- 参数更新的方式不用。DP将各个GPU上梯度汇总后求平均,在主卡进行参数更新,然后将模型参数广播到其他GPU。DDP只传播梯度,且各进程中模型初始参数一致,因此更新后的参数也一致。
- DDP支持模型并行,而DP并不支持。
模型并行(1):张量并行
张量并行,将计算图中的层内的参数(张量)切分到不同设备(即层内并行),每个设备只拥有模型的一部分,以减少内存负荷。
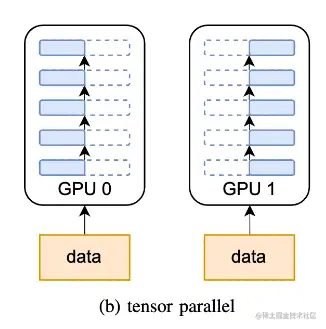
张量并行方式,有行并行和列并行。
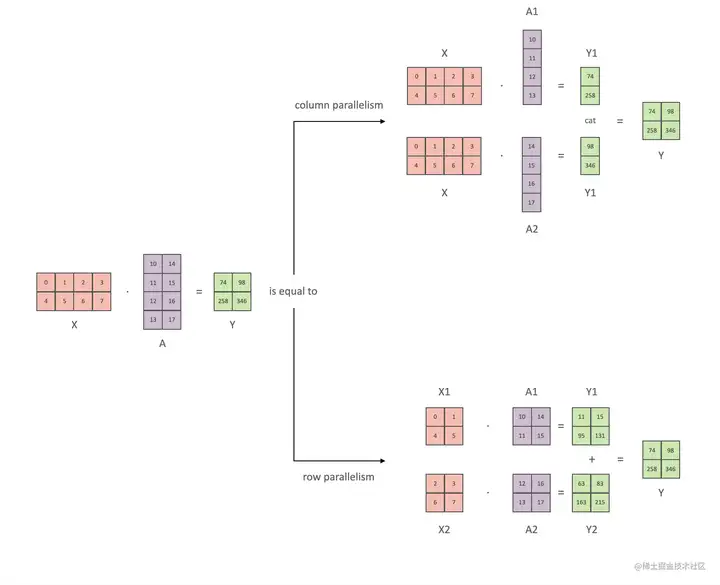
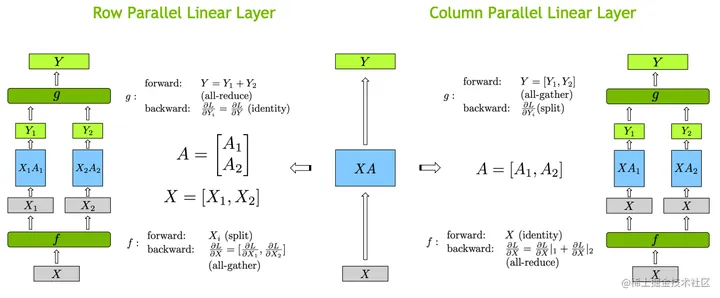
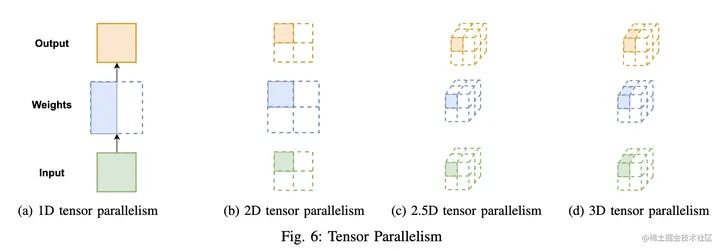
- 1D张量并行(Megatron-LM):张量并行则涉及到不同的分片 (sharding)方法,现在最常用的都是 1D 分片,即将张量按照某一个维度进行划分(横着切或者竖着切)。但每个处理器仍需要存储整个中间激活,在处理大模型时会消耗大量的显存空间。
- 多维张量并行(Colossal-AI)
模型并行(2):流水线并行
由于模型太大,无法将整个模型放置到单张GPU卡中;因此,将模型的不同层放置到不同的计算设备,降低单个计算设备的显存消耗,从而实现超大规模模型训练。各个设备上的网络层会使用反向传播过程计算得到的梯度更新参数。由于各个设备间传输的仅是相邻设备间的输出张量,而不是梯度信息,因此通信量较小。
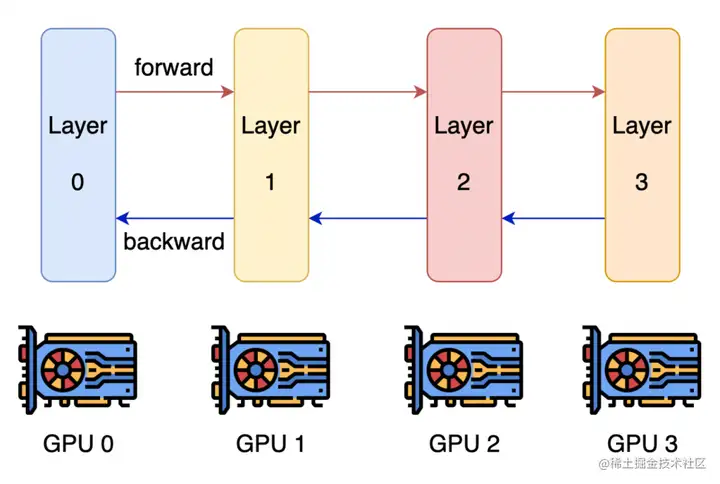
朴素流水线并行
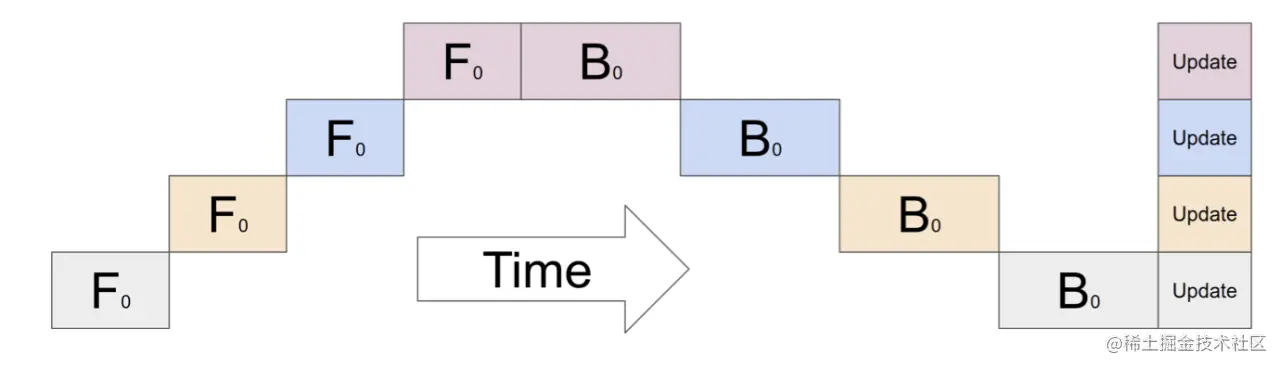
微批次流水线并行
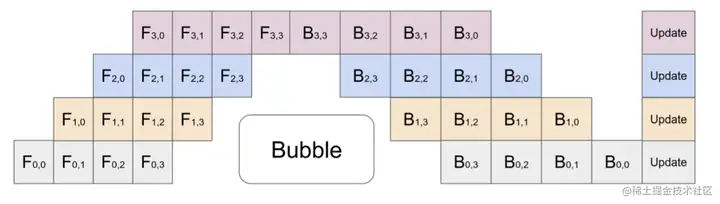
DeepSpeed
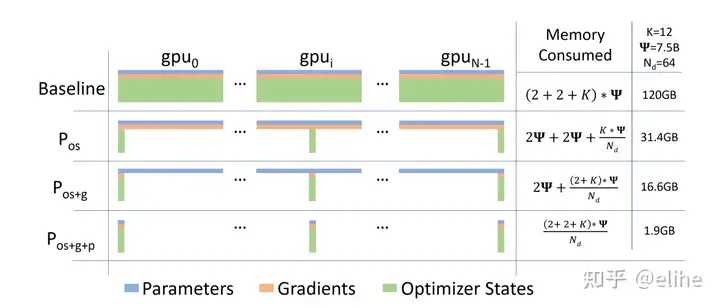
- ZeRO-DP的三种状态
ZeRO-DP简单来说就是想办法在数据并行的管线上把模型的参数分配到不同的显卡上,而不用所有显卡都装载所有参数。
它把训练期间模型状态的内存消耗归为三类:- OS(Optimizer State):优化器状态(如Adam的momentum和variance)(fp32的模型参数备份,fp32的momentum和fp32的variance)
- G(Gradient):模型梯度(fp16)
- P(Parameter):模型参数(fp16)
针对此,有三种优化方案。(3D parallelism)
Stage 1:
每台设备上都有完整的梯度和模型参数,但是只保留1/N的优化器状态,练时也只更新这部分状态对应的参数,每轮训练完成后进行reduce-scatter将所有机器上所有参数的梯度合并到负责的机器上去,然后再用all-gather将每台机器计算出的参数分发给全局。
Stage 2:
假设在于每台设备只能训练部分参数,所以单台设备上其他参数的梯度其实不需要保存。每台设备有完整的模型参数,但是只保留1/N的优化器状态和梯度。反向传播时每经过一层参数就开启一轮reduce-scatter将梯度整合到一个节点,计算出下一层梯度后删除前一层梯度。
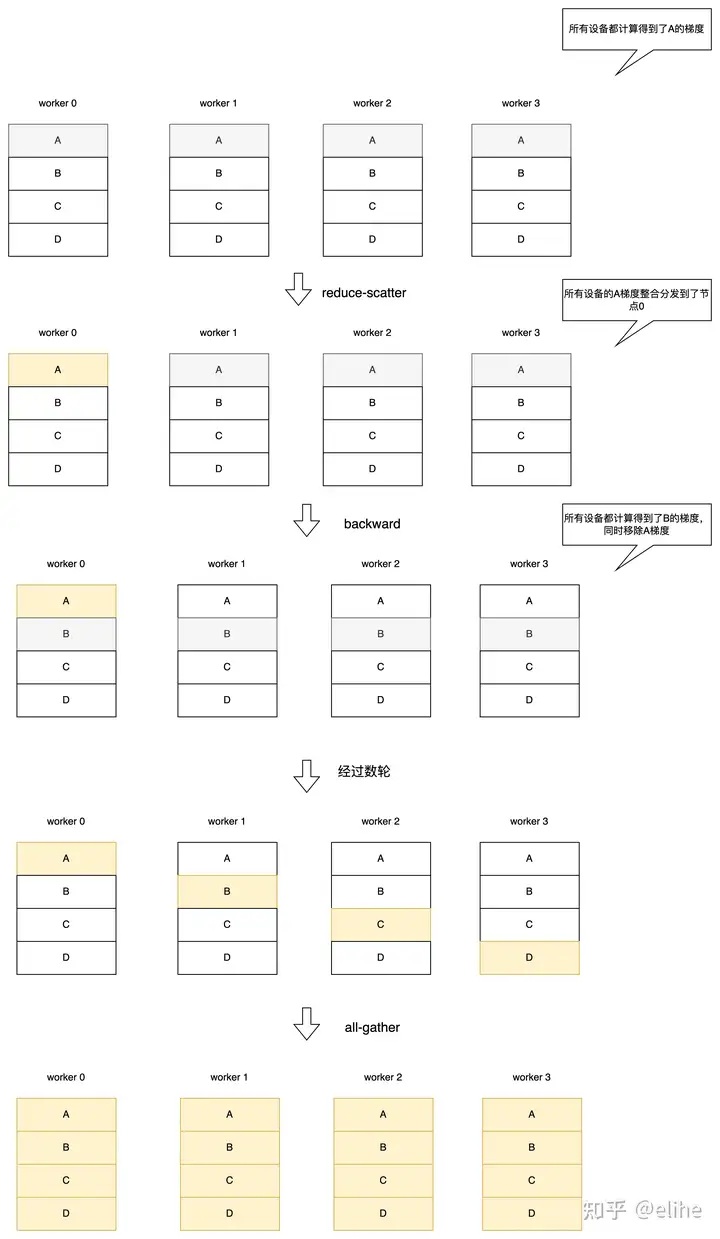
Stage 3:
在Stage 2基础上每一轮加上一次broadcast,把模型参数分发到各个设备上。
三个Stage的内存优化效率图
ZeRO-Offload
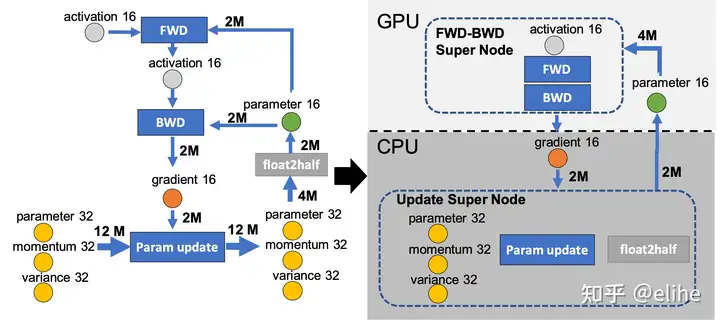
ZeRO-Offload的核心思路就是让CPU和内存也参与到训练中去。计算流程是,在GPU上面进行前向和后向计算,将梯度传给CPU,进行参数更新,再将更新后的参数传给GPU(可以开启Optimizer Offload和Param Offload,性能会受到影响。)
DeepSpeed各stage的速度以及显存消耗
速度:
Stage 0 > Stage 1 > Stage 1+Offload > Stage 2 > Stage 2+Offload > Stage 3 > Stage 3+Offload显存消耗:
Stage 0 < Stage 1 < Stage 1+Offload < Stage 2 < Stage 2+Offload < Stage 3 < Stage 3+Offload