





LoRA
LoRA原理
LoRA假设微调变化矩阵的内在秩远低于原矩阵维度d,因此将变化矩阵分解为B和A,而原矩阵的权重不发生变化。这样使得可训练参数数量极大减少,降低显存消耗量。见下图:
初始时将A矩阵高斯随机初始化,将B矩阵初始化为0,这样变化矩阵在开始训练时是0。还需要将进行scale: ,其中分子为r中的一个常数,r为选取的秩。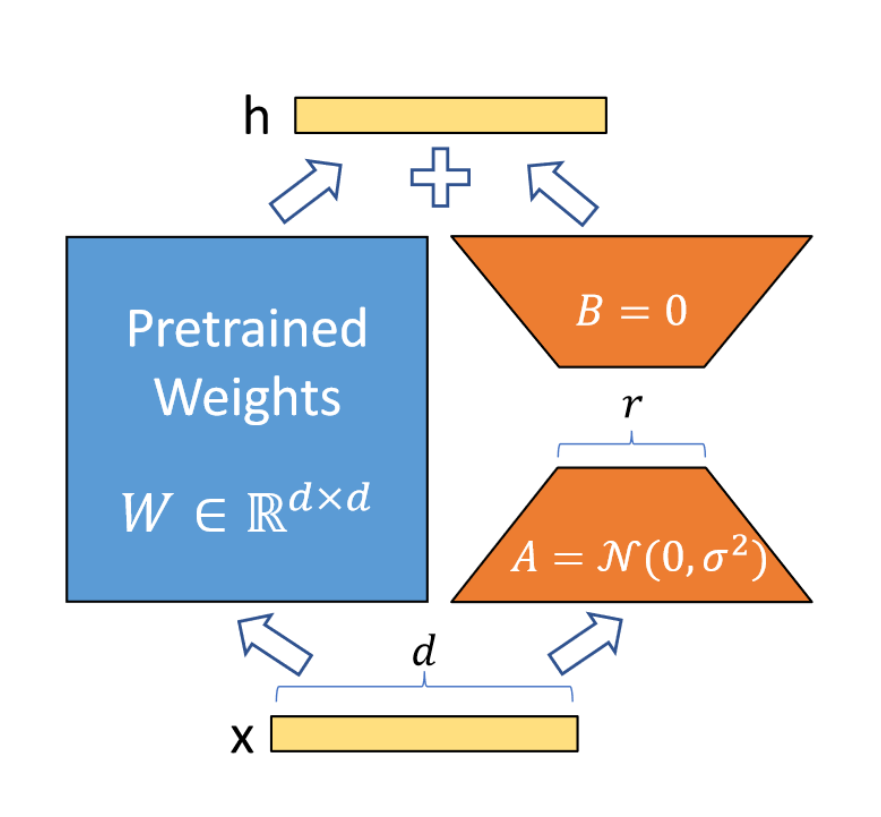
LoRA推理过程中有额外计算吗?
LoRA在推理时通常会将变化矩阵加在原矩阵上,这样并没有额外的计算开销,因此没有额外计算。
Lora初始化方式
A矩阵进行高斯分布初始化,B矩阵初始化为0.
LoRA应用于网络的哪些部分?
在Transformer中,可以应用于Attention中的Q,K,V矩阵和线性层,以及FFN中的两个MLP模块。能够大大降低微调参数量。通常用在Attention的q和v效果最好。
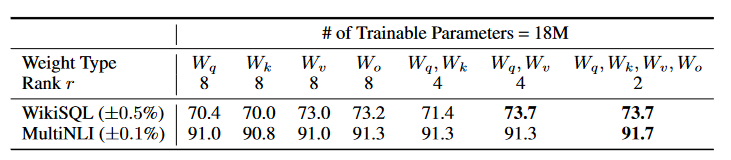
LoRA的r一般选取多少?
对于一般的任务,r=1,2,4,8 就足够了。而一些领域差距比较大的任务可能需要更大的r 。
QLoRA
Adapter tuning
Adapter tuning原理
在模型内部外置一些轻量级的层,通过训练这些层来适应新的数据变化。下图中为Bottleneck adapter。
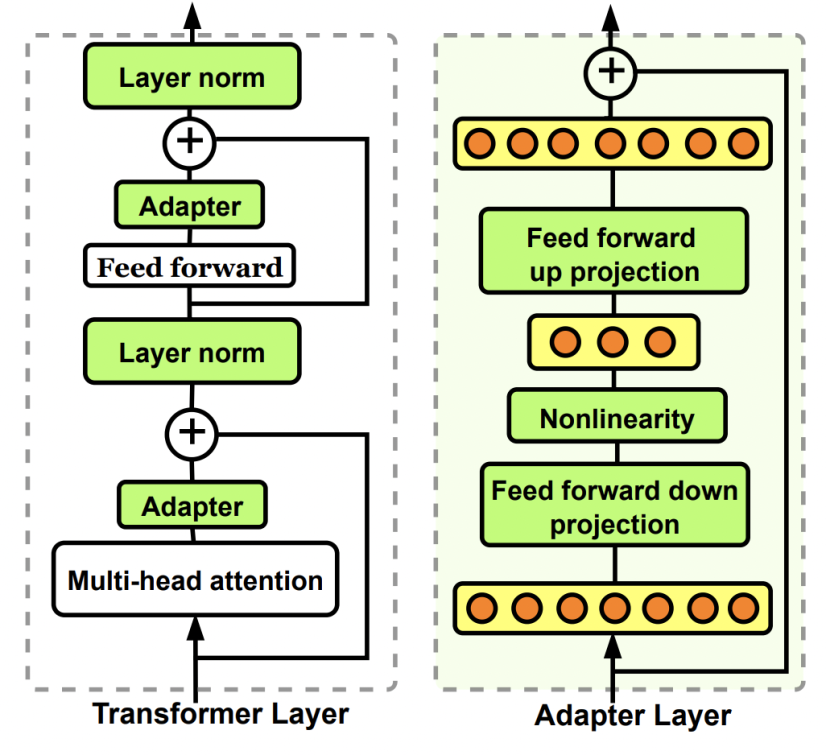
与LoRA的区别
Adapter会有新的模型层和参数;LoRA训练得到的部分最后会合并回原模型。
Prefix tuning
- Prefix tuning原理
主要适配NLG任务。
与Full-finetuning更新所有参数的方式不同,该方法是在输入token之前构造一段任务相关的virtual tokens作为Prefix,然后训练的时候只更新Prefix部分的参数,而Transformer中的其他部分参数固定。(该方法其实和构造Prompt类似,只是Prompt是人为构造的“显式”的提示,并且无法更新参数,而Prefix则是可以学习的“隐式”的提示。)同时,为了防止直接更新Prefix的参数导致训练不稳定的情况,他们在Prefix层前面加了MLP结构(相当于将Prefix分解为更小维度的Input与MLP的组合后输出的结果),训练完成后,只保留Prefix的参数。在每个Transformer layer前都会有prefix。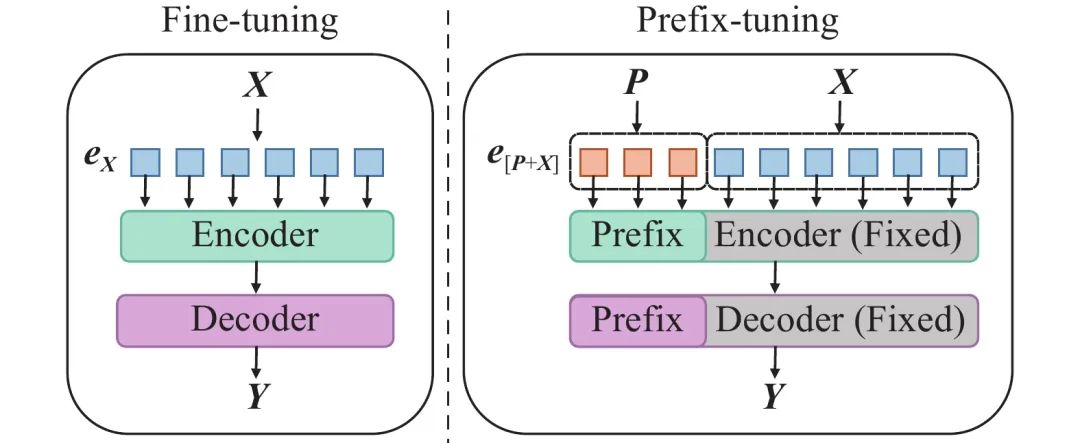
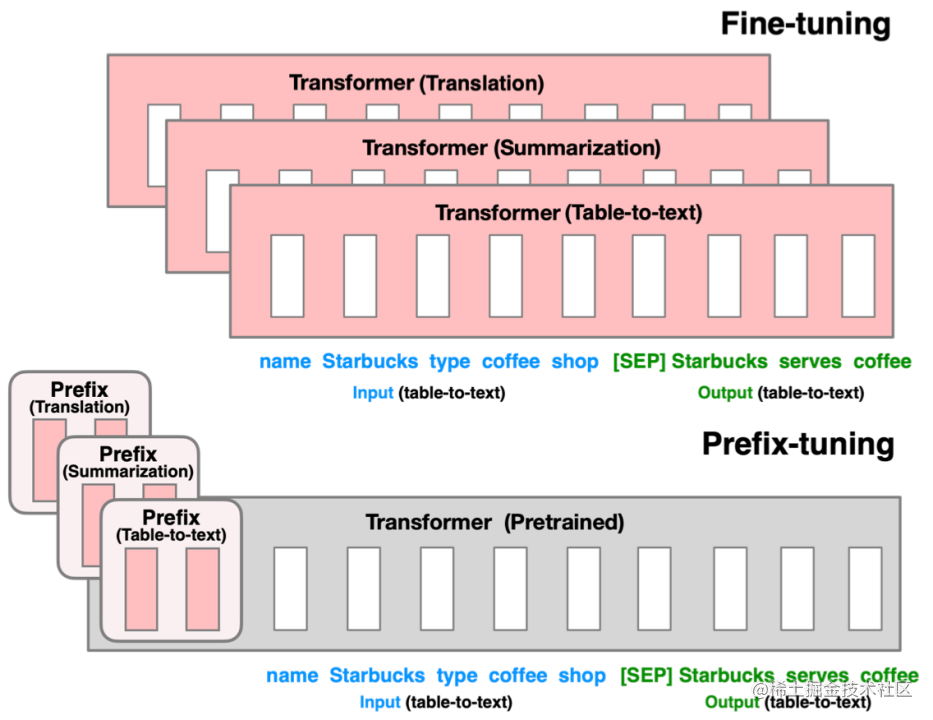 主要适配NLG任务。
主要适配NLG任务。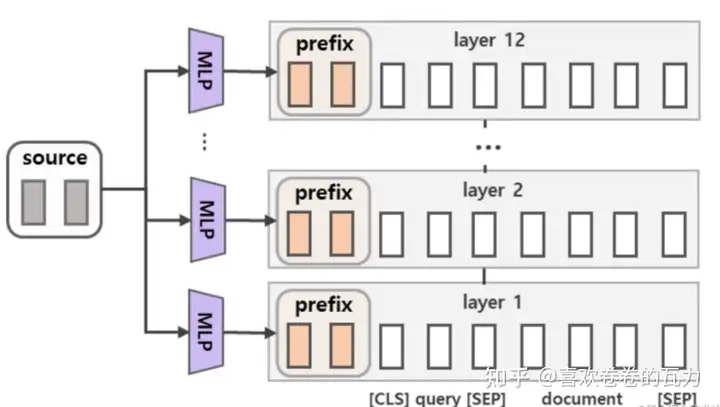
Prompt tuning
- Prompt tuning原理
该方法可以看作是 Prefix Tuning 的简化版本,它给每个任务定义了自己的Prompt,然后拼接到数据上作为输入,但只在输入层加入prompt tokens,并且不需要加入 MLP 进行调整来解决难训练的问题。 它在预训练语言模型的输入中添加可学习的嵌入向量作为提示。这些提示被设计成在训练过程中更新,以引导模型输出对特定任务更有用的响应。同时,Prompt Tuning 还提出了 Prompt Ensembling,也就是在一个批次(Batch)里同时训练同一个任务的不同 prompt(即采用多种不同方式询问同一个问题),这样相当于训练了不同模型。
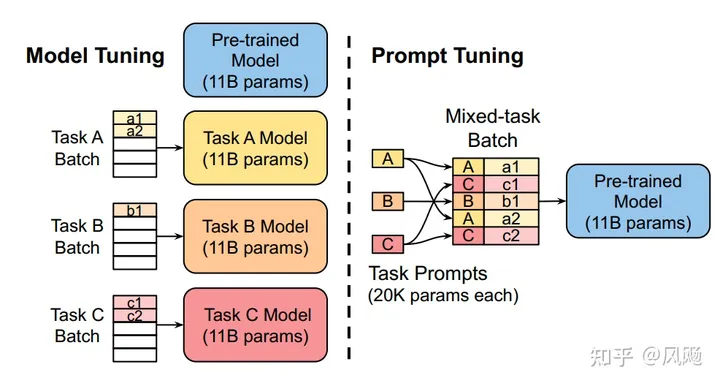
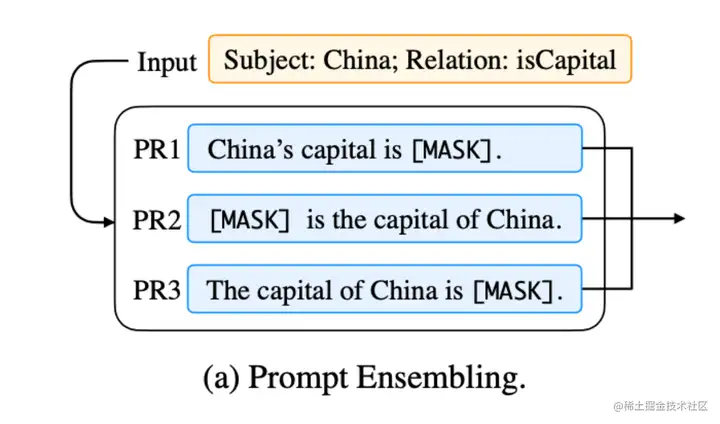
P-tuning
P-tuning V1原理
目的:使GPT适配NLU任务;避免人工设计prompt。
做法:该方法将Prompt转换为可以学习的Embedding层,并用MLP+LSTM的方式来对Prompt Embedding进行一层处理。相比Prefix Tuning,P-Tuning加入的可微的virtual token,但仅限于输入层,没有在每一层都加;另外,virtual token的位置也不一定是前缀,插入的位置是可选的。这里的出发点实际是把传统人工设计模版中的真实token替换成可微的virtual token。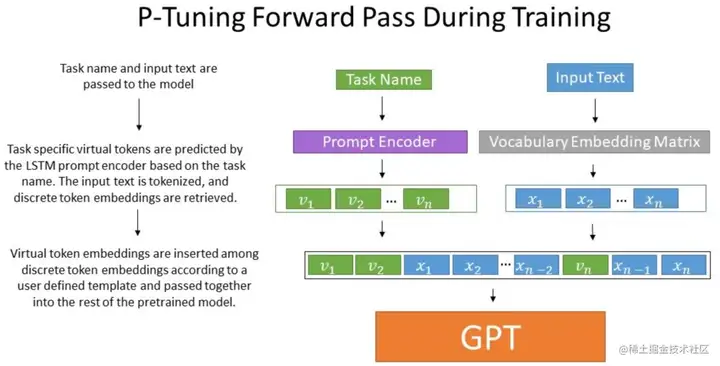
P-tuning V2原理
方法:该方法在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层,这带来两个方面的好处:(1)更多可学习的参数(从P-tuning和Prompt Tuning的0.01%增加到0.1%-3%),同时也足够参数高效。(2)加入到更深层结构中的Prompt能给模型预测带来更直接的影响(如Prefix tuning).具体做法基本同Prefix Tuning,可以看作是将文本生成的Prefix Tuning技术适配到NLU任务中.
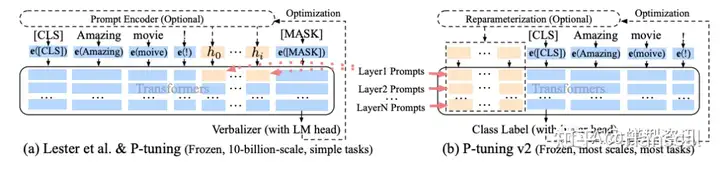
P-tuning V1/V2的区别。
参见上图。可以简单的将 P-Tuning 认为是针对 Prompt Tuning 的改进, P-Tuning v2 认为是针对 Prefix Tuning 的改进。