





BERT
BERT模型结构
由多个Transformer Encoder堆叠。分为12层的BERT-base和24层的BERT-large。
最长序列:512个token,超过的需要截断。
Tokenizer: WordPiece。每个句子首个token都是[CLS],分隔符用[SEP]。会拆分Subword,例如playing拆分为play和###ing。
Embedding:见下图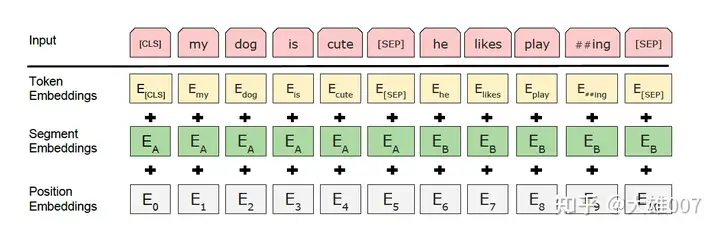
- Token Embedding:分词后转为词向量。
- Segement Embedding:用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务。(在句子对任务中,第一个句子为0,第二个为1;在文本分类中只有一个句子,则全部为0)
- Position Embedding:使用可学习的Position Embedding。
BERT预训练任务
由MLM和NSP两个自监督任务组成。
Masked Language Modeling(MLM):在BERT的实验中,15%的WordPiece Token会被随机Mask掉。在训练模型时,一个句子会被多次喂到模型中用于参数学习,但是Google并没有在每次都mask掉这些单词,而是在确定要Mask掉的单词之后,做以下处理:(1)80%的时候会直接替换为[Mask],将句子 “my dog is cute” 转换为句子 “my dog is [Mask]”。(2)10%的时候将其替换为其它任意单词,将单词 “cute” 替换成另一个随机词,例如 “apple”。将句子 “my dog is cute” 转换为句子 “my dog is apple”。(3)10%的时候会保留原始Token,例如保持句子为 “my dog is cute” 不变。
*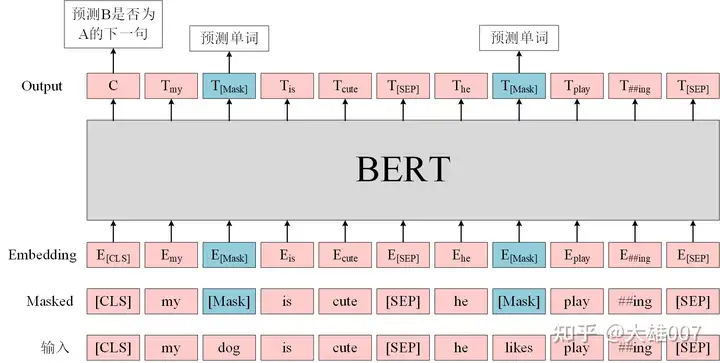
Next Sentence Prediction(NSP):判断句子B是否是句子A的下文。如果是的话输出’IsNext‘,否则输出’NotNext‘。训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的。
[CLS]的作用
BERT在第一句前会加一个[CLS]标志,最后一层该位对应向量可以作为整句话的语义表示,从而用于下游的分类任务等。因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。
BERT的优缺点
优点:(1)BERT 相较于原来的 RNN、LSTM 可以做到并发执行,同时提取词在句子中的关系特征,并且能在多个不同层次提取关系特征,进而更全面反映句子语义。(2)相较于 word2vec,其又能根据句子上下文获取词义,从而避免歧义出现。
缺点:(1)模型参数太多,而且模型太大,少量数据训练时,容易过拟合。(2)BERT的NSP任务效果不明显,MLM存在和下游任务mismathch的情况。(3)BERT对生成式任务和长序列建模支持不好。
BERT和GPT区别
- 训练目标不同:BERT是MLM和NSP;GPT是自回归的LM。
- 模型结构不同:BERT是Transformer Encoder,双向注意力;GPT是Decoder,单向注意力。
- 应用场景不同:BERT由于其双向上下文理解能力,BERT在需要理解整个输入序列的任务中表现更好,如问答系统、命名实体识别(NER)和句子对分类;由于其生成能力,GPT在文本生成任务中表现更好,如文本续写、对话系统和文本摘要。
- 使用方式:BERT通常是pretrain+finetune;;GPT通常是pretrain+prompting。
BERT-wwm
- BERT-wwm与BERT的区别
BERT在MLM过程中,可能只会mask掉某个Subword;BERT-wwm则是如果Subword被选中mask,那么整个单词都会进行mask。因此是全词掩码(Whole Word Mask)。
RoBERTa
- RoBERTa与BERT的区别
- 更多的预训练语料。
- 更大的batchsize。
- 更长的训练步数。
- 剔除NSP任务。
- 动态mask:BERT中,对于每一个样本序列进行mask之后,mask的tokens都固定下来了,即是静态mask的方式;而RoBERTa使用了动态mask的方式:对于每一个输入样本序列,都会复制10条,然后复制的每一个都会重新进行mask,即拥有不同的masked tokens。