GPT-1
简述一下GPT的训练过程。
GPT的训练过程采用了预训练和微调的二段式训练策略。
- 非监督式预训练: 利用大规模无标记语料,构建预训练单向语言模型。训练目标是Language Modeling loss。
- 监督式微调: 用预训练的结果作为下游任务的初始化参数,增加一个线性层,匹配下游任务。训练目标是有监督的目标函数,并加上Language Modeling作为辅助目标。
GPT的Decoder与Transformer Decoder的区别
- 激活函数为GELU
- 位置编码为Learning Position embedding
- 去除了Cross attention。
- Tokenizer采用的是BPE。
为什么GPT是Decoder-only?
Transformer 结构提出是用于机器翻译任务,机器翻译是一个Seq2Seq的任务,因此 Transformer 设计了Encoder 用于提取源端语言的语义特征,而用 Decoder 提取目标端语言的语义特征,并生成相对应的译文。GPT目标是服务于单序列文本的生成式任务,所以舍弃了关于 Encoder部分以及包括 Decoder 的 Cross Attention 层。
GPT-2
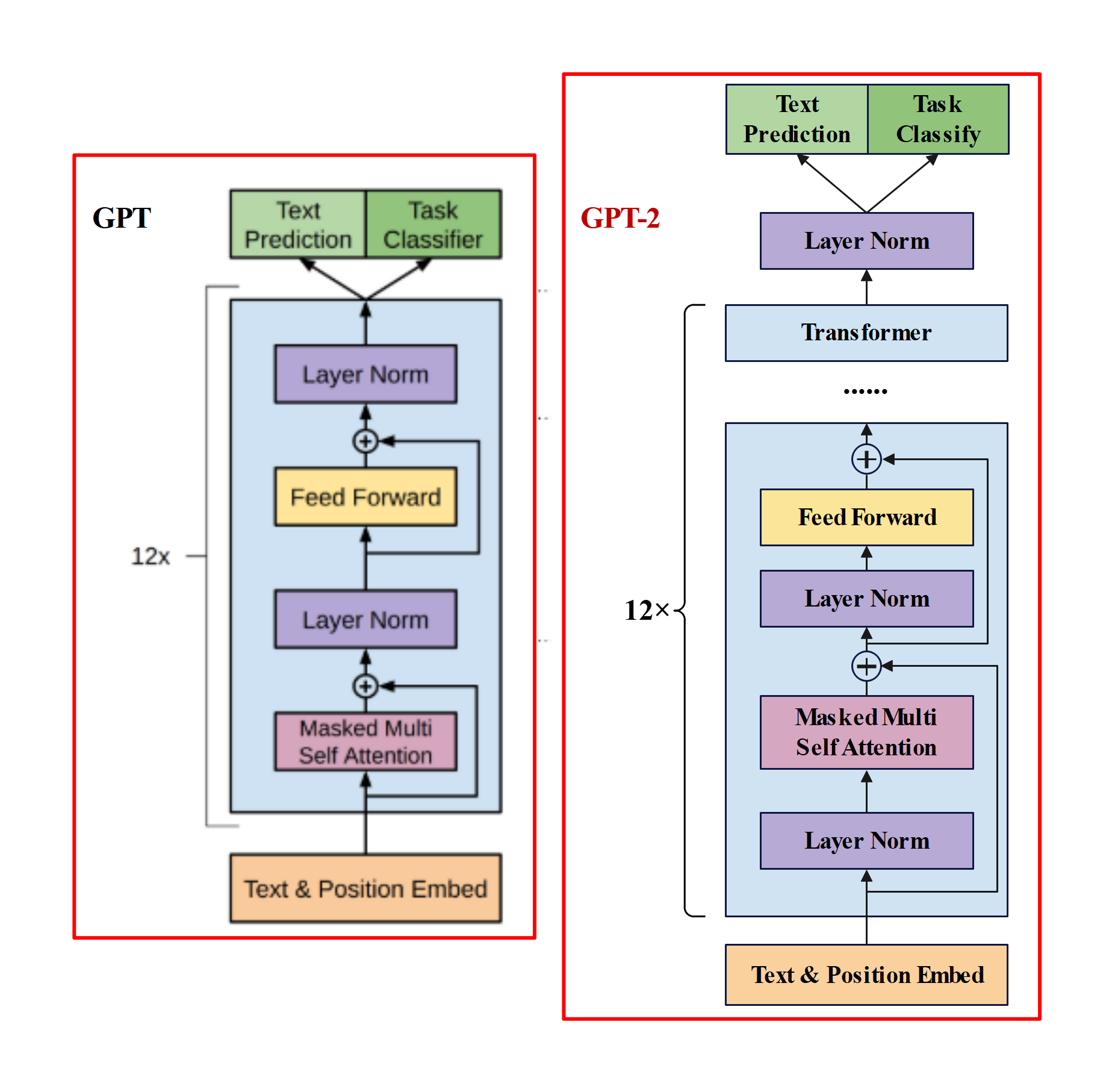
- GPT-2与GPT的区别?
主推zero-shot,而GPT-1为pre-train+fine-tuning。
模型更大。参数量达到1.5B,而GPT只有0.117B.
数据集更大。
训练参数变化,batch_size 从 64 增加到 512,上文窗口大小从 512 增加到 1024。
模型结构变化:- 后置层归一化( post-norm )改为前置层归一化( pre-norm );
- 在模型最后一个自注意力层之后,额外增加一个层归一化;
- 调整参数的初始化方式,按残差层个数进行缩放,缩放比例为;
- 输入序列的最大长度从 512 扩充到 1024;
GPT-3
- GPT-3与GPT-2区别?
GPT-2虽然提出zero-shot,比bert有新意,但是有效性方面不佳。GPT-3考虑few-shot,用少量文本提升有效性。
模型结构:- 大部分和GPT-2一样,但应用了Sparse attention。
论文尝试了四种方式的评估方法: - fine-tuning:预训练 + 训练样本计算loss更新梯度,然后预测。会更新模型参数.
- zero-shot:预训练 + task description + prompt,直接预测。不更新模型参数.
- one-shot:预训练 + task description + example + prompt,预测。不更新模型参数.
- few-shot(又称为in-context learning):预训练 + task description + examples + prompt,预测。不更新模型参数.
- 大部分和GPT-2一样,但应用了Sparse attention。
Instruct-GPT
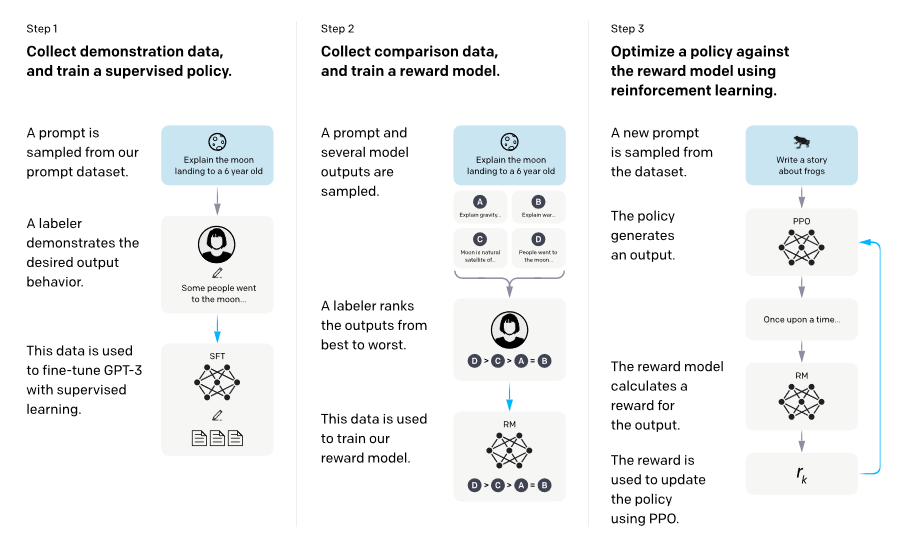
- 介绍一下InstructGPT。为了和人类的需求对齐—— 主要由三个阶段组成 : (1) SFT(Supervised Fine-tuning):收集一系列人工标注的(Question,Response)作为数据集,使用LM目标函数监督学习微调GPT-3(16个epoch)。根据验证集上的RM分数,选择最终的SFT模型。 (2) RM(Reward Modeling):RM是训练一个Reward Model,将SFT模型最后的嵌入层去掉后的模型,它的输入是prompt和response,输出是标量的奖励值。奖励模型的损失函数如下,这里使用的是排序中常见的pairwise ranking loss。这是因为人工标注的是答案的顺序,而不是分数,所以中间需要转换一下。 (3) RL(PPO):训练RL policy,即之前SFT过的GPT-3。用SFT的GPT-3输出Response,用上一步训练的Reward Model输出标量作为Reward,来训练这个RL policy。为了确保输出的质量不降低,有时也会在PPO的目标函数之外额外加上加权的LM目标函数。