





LLAMA
LLaMa介绍
预训练数据:全是开源数据。
Tokenizer: BPE implemented by SentecePiece,分词后训练集中共包含1.4T tokens。
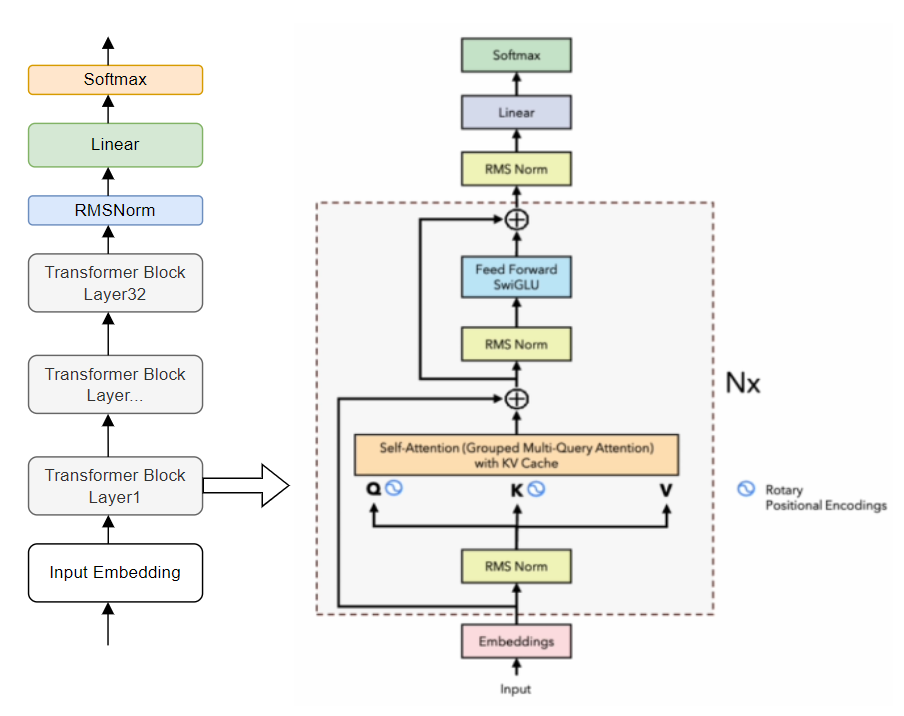
模型架构:相比与原始Transformer架构,有如下改动- Pre-norm:参考GPT3,在transformer sub-layer前进行norm。使用的是RMSNorm。
- SwiGLU: 参考PaLM,使用SwiGLU作为激活函数。
- RoPE: 将PE换成了RoPE。
- 在casual MHA这里使用了更efficient的实现方式。
- 保存线性层输出的activation。
Optimizer: AdamW,同时用CosLR schedule。同时有0.1的weight decay和1.0的grad clip。有2000 steps的warm up。
在2048台A100-80GB上训练了21天。
LLAMA中的RMSNorm
RMSNorm(Root Mean Square Layer Normalization)
提出动机:LayerNorm计算量比较大。
优点:(1)计算效率高。不需要同时计算均值和方差两个统计量,而只需要计算均方根这一个统计量(没有去中心化操作)。同时也减少了Norm中的参数量(只有lambda一个参数)。 (2)稳定性好。能缓解梯度消失和梯度爆炸。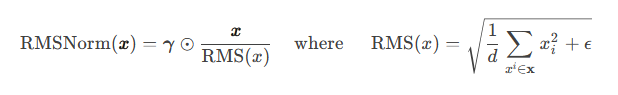
1 | class LlamaRMSNorm(nn.Module): |
- LLAMA的loss函数
Language Modeling,即自回归预测next word的概率,实现方式为Cross Entropy。
也会有其他的预训练损失函数。
LLAMA2
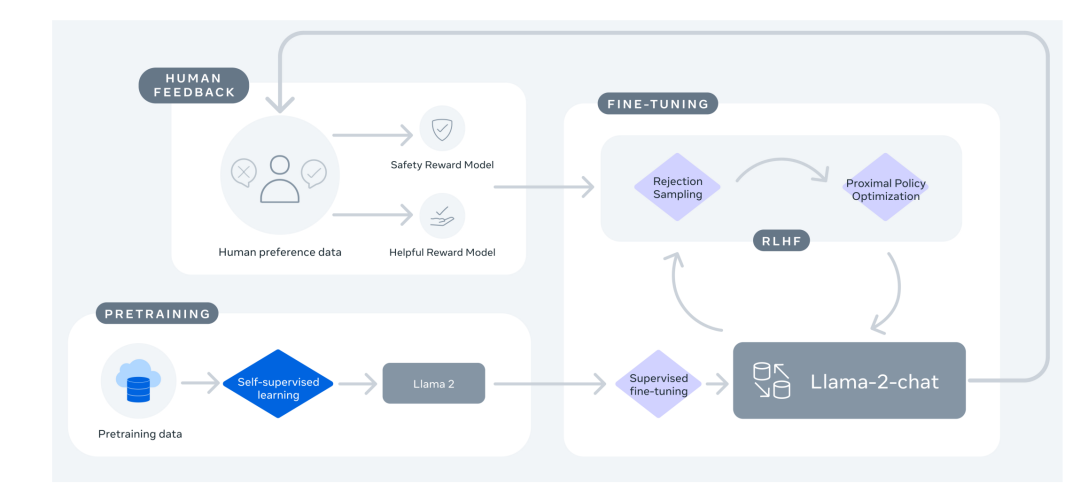
- LLAMA2的改进* 预训练语料扩充到2T token。 * 上下文长度从2048翻倍到4096. * 引入了Grouped-query attention、KV cache等技术 * 在LLAMA2基础上进一步SFT(Supervised Fine-tuning)和RLHF,得到LLAMA2-Chat。
LLAMA3
- LLAMA3的改进
- 训练数据集比LLAMA2大7倍。
- 采用了数据并行、模型并行、管道并行等并行化技术。
- 结合了SFT,Rejection sampling、PPO、DPO对预训练模型进行指令微调。
Vicuna
Vicuna是在LLaMa-13B的基础上使用监督数据微调得到的模型,数据集来自于ShareGPT.com 产生的用户对话数据,共70K条。
Vicuna在训练中将序列长度由512扩展到了2048,并且通过梯度检测和flash attention来解决内存问题;调整训练损失考虑多轮对话,并仅根据模型的输出进行微调。