





Qwen
Qwen的技术要点
- 数据:公共网络文档,百科全书,书籍,代码等。此外,数据集是多语言的,其中很大一部分数据是英语和中文的。最终数据集多达3万亿token。
- Tokenizer:采用开源的BPE,并以vocabulary C1100K base作为起始点,增加了常用的中文字符和单词以及其他语言的词汇。此外,仿照LLAMA2,将数字分为单个数字,最终词汇量大约是152K.
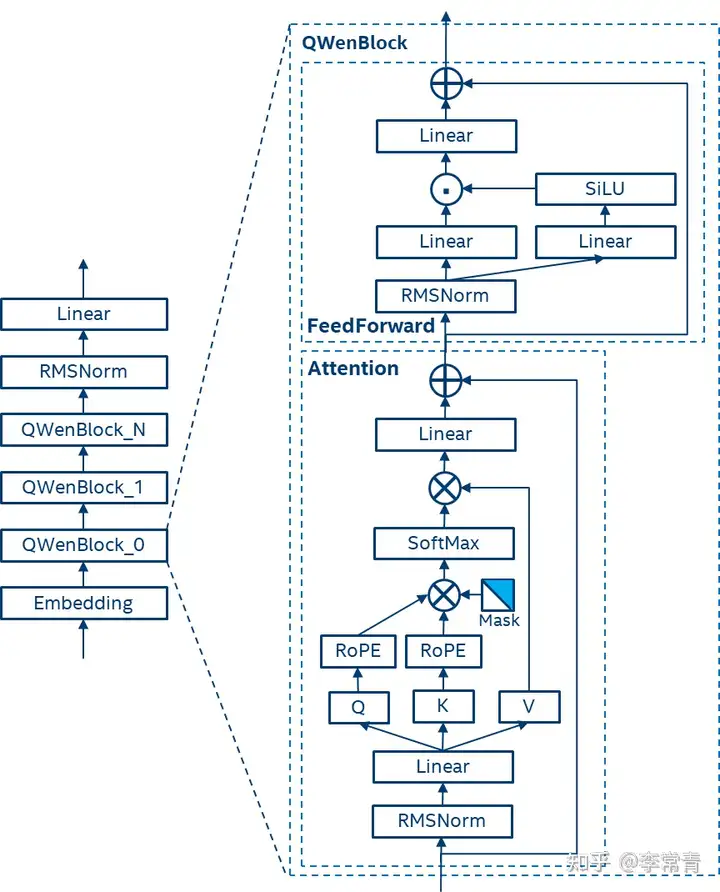
- 模型结构:
(1) Embedding和Output project:解耦嵌入。
(2) Positional embedding: RoPE,使用FP32的逆频率矩阵。
(3) Bias,除了Attention中的QKV,其他层的bias都去除,以增强外推能力,并防止过拟合。
(4) Pre-Norm & RMSNorm
(5) Activation:选用SwiGLU。 - 对于文本长度的拓展,使用了Dynamic NTK-aware interpolation,可以在无需训练的方法下调整尺度以防止高频信息的丢失,有效地扩展Transformer模型的上下文长度。
Qwen的预训练
- 采用标准的自回归语言模型训练目标
- 训练时上下文长度为2048
- 注意力模块采用Flash Attention技术,以提高计算效率并减少内存使用
- 采用AdamW优化器,设置β1=0.9,β2=0.95,,=1e-8
- 使用余弦学习率计划,为每种模型设定一个峰值学习率,学习率会衰减到峰值的10%
- 使用BFloat16混合精度加速训练
Qwen的对齐
SFT:采用ChatML格式的数据进行模型训练。
RM:偏好模型预训练和微调
PPO:使用RM进行RLHF。
Qwen-2
- Qwen2相对于Qwen的改进
- 多种模型规模
- 多语言支持:在训练数据中增加了27种语言的高质量数据,增强了模型的多语言能力。
- 代码和数学能力
- 长文本处理:Qwen2模型能够处理更长的上下文,最高可达128K tokens。
- 架构创新:引入了Group Query Attention。